SmolVLM是为资源受限设备设计的高效多模态模型,通过优化架构和训练策略,在图像和视频处理任务上表现出色,为设备端应用提供视觉理解能力。
原文标题:SmolVLM:资源受限环境下的高效多模态模型研究
原文作者:数据派THU
冷月清谈:
本文介绍了专为资源受限设备设计的高效多模态模型SmolVLM。通过精心设计的架构和训练策略,SmolVLM在图像和视频处理任务上表现出接近大型模型的性能。文章深入探讨了SmolVLM的架构设计,包括视觉与语言模型间的计算资源分配、高效视觉信息传递机制、以及图像与视频的高效编码策略。研究发现,小型模型中视觉与语言组件间的参数分配比例需要特别考量,且激进的压缩比例能有效降低自注意力计算开销。此外,学习型标记和结构化文本提示能显著提升模型性能,而重用大型语言模型的文本数据可能产生负面效果。实验结果表明,SmolVLM在计算效率和内存优化方面表现出色,并在多个下游应用场景中展现出巨大潜力,为实时、设备端应用提供了强大的视觉理解能力。
怜星夜思:
1、SmolVLM在资源受限设备上的表现确实亮眼,但它在哪些特定类型的任务上可能仍然面临挑战?例如,对于对抗性攻击或者处理极端复杂的场景,它的鲁棒性如何?从工程落地的角度来看,还有哪些优化空间?
2、文章提到SmolVLM在训练中对视频序列长度进行了分析,并发现适度延长视频序列长度对小型模型性能提升有显著价值。那么,除了视频长度,还有哪些视频数据的特性(比如帧率、分辨率、视频质量等)会对模型性能产生重要影响?在实际应用中,我们应该如何权衡这些因素,选择最合适的视频数据进行训练?
3、SmolVLM通过学习型标记改善了训练的稳定性和性能,那么,这种学习型标记的思想是否可以应用到其他多模态模型中?例如,在文本与语音的结合中,我们是否可以使用学习型标记来更好地表示语音的特征,从而提升模型的性能?
2、文章提到SmolVLM在训练中对视频序列长度进行了分析,并发现适度延长视频序列长度对小型模型性能提升有显著价值。那么,除了视频长度,还有哪些视频数据的特性(比如帧率、分辨率、视频质量等)会对模型性能产生重要影响?在实际应用中,我们应该如何权衡这些因素,选择最合适的视频数据进行训练?
3、SmolVLM通过学习型标记改善了训练的稳定性和性能,那么,这种学习型标记的思想是否可以应用到其他多模态模型中?例如,在文本与语音的结合中,我们是否可以使用学习型标记来更好地表示语音的特征,从而提升模型的性能?
原文内容

来源:Deephub Imba本文共5000字,建议阅读5分钟本文介绍了SmolVLM模型在资源受限环境下的高效多模态模型研究。
SmolVLM是专为资源受限设备设计的一系列小型高效多模态模型。尽管模型规模较小,但通过精心设计的架构和训练策略,SmolVLM在图像和视频处理任务上均表现出接近大型模型的性能水平,为实时、设备端应用提供了强大的视觉理解能力。
SmolVLM架构设计
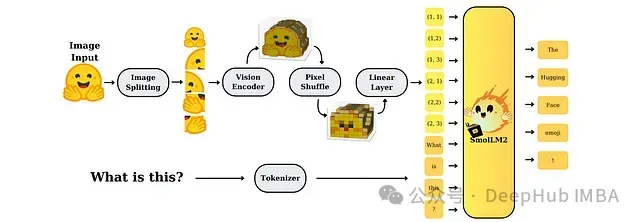
该研究系统性地探索了小型多模态模型的设计选择与权衡。在SmolVLM的架构中,图像首先通过视觉编码器进行处理,编码后的视觉特征经过池化和维度投影后输入到SmolLM2语言骨干网络中进行多模态理解与生成。
SmolVLM根据不同的计算资源需求构建了三种主要变体:
-
SmolVLM-256M:结合93M参数的SigLIP-B/16视觉编码器和SmolLM2-135M语言模型。该变体可在不足1GB显存环境中运行,特别适合极度受限的边缘计算场景。
-
SmolVLM-500M:将93M参数的SigLIP-B/16视觉编码器与SmolLM2-360M语言模型组合。这一变体在内存效率与性能之间取得平衡,适用于中等计算资源的边缘设备。
-
SmolVLM-2.2B:整合400M参数的SigLIP-SO400M视觉编码器和1.7B参数的SmolLM2语言骨干网络。该配置在保持可部署于高端边缘系统的同时最大化了性能表现。
视觉与语言模型间的计算资源分配策略
研究团队将三种SmolLM2变体(参数量分别为135M、360M和1.7B)与两种SigLIP视觉编码器进行配对:紧凑型93M参数的SigLIP-B/16和更大的428M参数的SigLIP-SO400M。研究发现,与大型多模态模型不同,小型模型中视觉与语言组件间的参数分配比例需要特别考量。
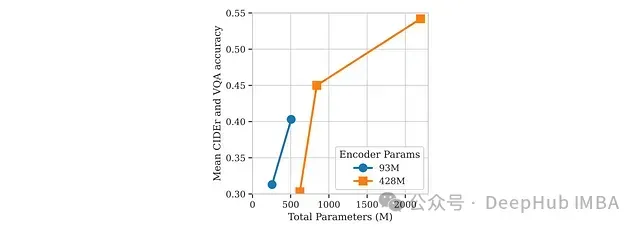
实验结果显示:
-
当大型视觉编码器与最小规模语言模型(135M)配合时,模型性能显著下降,这表明编码器与语言模型之间存在不平衡的低效组合。
-
对于中等规模语言模型(360M),采用更大的视觉编码器虽然提升了11.6%的性能,但这伴随着66%的参数量增加,因此从参数效率角度考虑,紧凑型编码器仍更具优势。
-
只有在最大规模语言模型(1.7B)配置下,更大的视觉编码器参数增加比例降至约10%,此时大型视觉编码器的性能提升与参数增加达到较好平衡。
高效视觉信息传递机制设计
SmolVLM采用自注意力架构,将视觉编码器生成的视觉标记与文本标记连接后由语言模型共同处理。这种设计需要比SmolLM2原有2k标记限制更长的上下文处理能力,因为单张512×512分辨率图像经由SigLIP-B/16编码后就需要1024个标记。为解决这一挑战,研究者通过将RoPE基数从10k增加到273k以扩展模型的上下文处理能力,并在混合数据集上进行微调,这些数据包括长上下文数据(Dolma、The Stack)、短上下文源(FineWeb-Edu、DCLM)以及来自SmolLM2的数学内容。
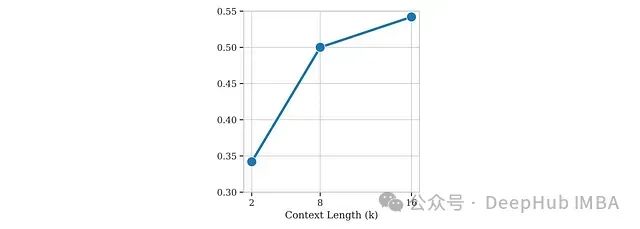
研究结果表明:
-
对于1.7B参数规模的语言模型,在16k标记处的微调性能保持稳定。
-
较小规模模型(135M、360M)在上下文超过8k标记时性能显著下降。
-
对2.2B参数SmolVLM的实验进一步证实,性能随上下文窗口增加至16k标记时持续提升。
-
基于这些发现,SmolVLM最终采用了16k标记的上下文窗口,而较小变体则采用8k标记限制。
最新的视觉-语言模型通常结合自注意力架构与标记压缩技术,以高效处理长序列并降低计算开销。像素重排(Pixel Shuffle,从空间到深度的重新排列)是一种特别有效的视觉压缩方法,最初为超分辨率任务提出,近期被Idefics3等模型采用。这种技术将空间特征重新排列到额外的通道维度,减少空间分辨率同时提高表示密度。
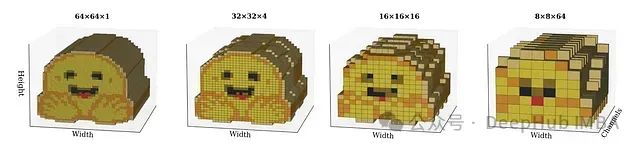
像素重排可将视觉标记总数减少r²倍(r为重排比例因子)。然而,过高的重排比例会将较大的空间区域压缩到单个标记中,从而损害需要精确空间定位的任务,如光学字符识别(OCR)。
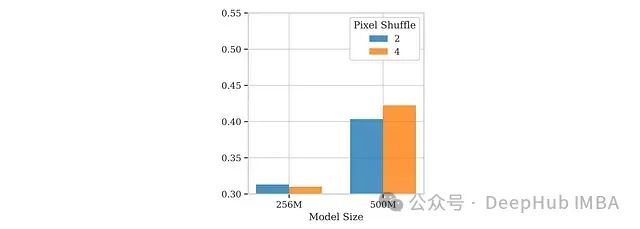
不同模型规模下最佳像素重排因子对比(PS=2 vs. PS=4)。
研究发现:
-
大型模型如InternVL和Idefics3通常使用r = 2的重排比例,以平衡压缩效率与空间分辨率保真度。
-
对比实验表明,较小规模的多模态模型反而受益于更激进的压缩比例(r = 4),这是因为减少的标记数量有效降低了自注意力计算开销,并显著改善了长上下文建模能力。
图像与视频的高效编码策略
在图像和视频处理中合理分配标记资源对高效多模态建模至关重要。图像通常需要较高分辨率和更多标记以保持视觉细节,而视频则需要在每帧使用较少标记以高效处理更长的时间序列。为此,研究者采用了图像分割策略,将高分辨率图像分成多个子图像,并结合原始图像的缩小版本。实验证明,这种方法能在不产生过多计算开销的前提下有效保持图像质量。然而,对于视频处理,实验发现诸如帧平均等压缩策略会显著降低模型性能。
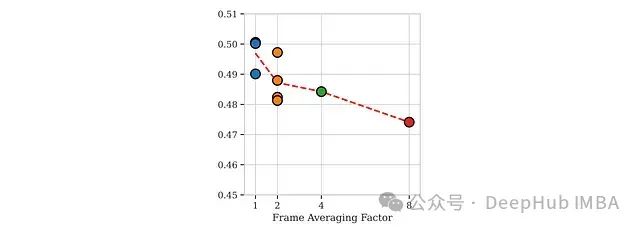
实验结果显示:
-
合并多个视频帧显著降低了OpenCompass-Video评测结果,特别是在较高的平均因子(2、4、8)条件下。
-
基于这些发现,SmolVLM的最终设计中排除了帧平均策略,而是选择将视频帧重新缩放到视觉编码器的标准输入分辨率。
学习型标记与字符串表示的效能比较
SmolVLM设计中的一个关键考量点是如何有效编码分割子图像的位置信息。初期实现中使用了简单的字符串标记(如<row_1_col_2>),但这导致了训练过程中出现"OCR损失瘟疫"现象——表现为损失函数突然下降但OCR任务性能没有相应提升。
为解决训练不稳定性问题,研究团队引入了可学习的位置标记,这显著改善了训练收敛性并减少了性能停滞。实验表明,虽然较大规模模型对使用原始字符串位置编码相对稳健,但较小规模模型从可学习位置标记中获益显著,在OCR准确率和跨任务泛化能力方面均取得了明显优势。
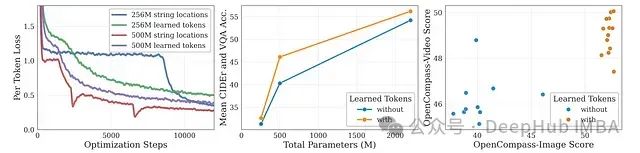
研究结果表明:
-
在多个图像和文本基准测试中,采用学习型位置标记的模型始终优于使用朴素字符串位置编码的版本。
-
利用学习型标记的模型在OpenCompass-Image和OpenCompass-Video评估中获得更高分数,强调了结构化位置标记在紧凑多模态模型中的重要性。
结构化文本提示与媒体分割技术
研究团队系统评估了系统提示和显式媒体引入/结束标记如何逐步提升SmolVLM在图像和视频基准测试中的性能。
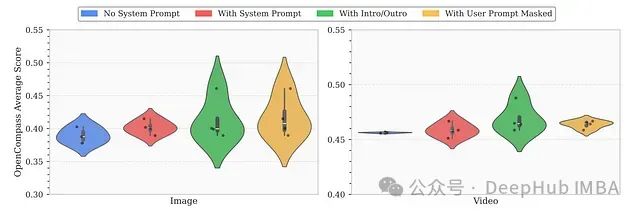
不同训练策略对SmolVLM性能的累积影响。
系统提示增强:通过在任务开始前添加简明指令以明确化任务目标并减少零样本推理过程中的歧义。这一策略导致了各项任务性能的明显提升,特别是在以图像为中心的任务中效果更为显著。
媒体引入/结束标记:为清晰标记视觉内容边界,研究者在图像和视频段落周围引入了特定的文本标记(如"这是一张图像..."和"这是从视频中采样的N帧..."),并使用结束标记过渡回文本指令(如"给定这张图像/视频...")。这种结构化标记策略大幅提升了视频任务性能——多帧内容混淆风险更高的场景——同时在图像任务上也产生了可测量的改进。
用户提示屏蔽策略:为减少过拟合风险,研究者在监督微调阶段探索了用户提示屏蔽技术。与未屏蔽基线相比,屏蔽用户查询策略在图像和视频任务中均产生了更好的性能表现。这种效果在多模态问答场景中尤为显著,其中问题模式往往高度重复且模型容易记忆表面特征。通过屏蔽策略,模型被迫依赖于与任务真正相关的内容而非表面重复模式,从而促进了更好的泛化能力。
LLM-SFT文本数据重用对模型性能的影响
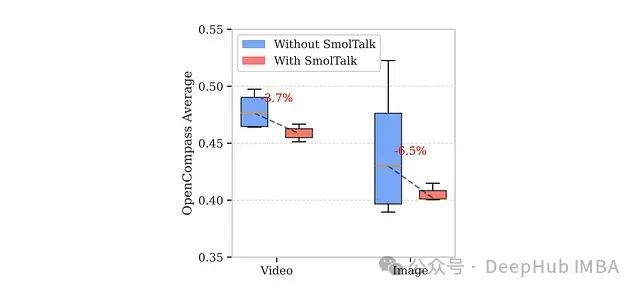
直观上,重用大型语言模型最终监督微调阶段的文本数据似乎是合理的,因为这可能提供分布内提示和更高质量的语言输入。然而,实验结果表明:
-
在较小规模的多模态架构中,纳入LLM-SFT文本数据(如SmolTalk)可能产生负面效果,导致视频任务性能最多下降3.7%,图像任务最多下降6.5%。
-
这种负迁移现象主要归因于数据多样性的减少,这一负面影响超过了重用高质量文本带来的任何潜在收益。
-
基于这些发现,研究团队在最终训练数据混合中严格控制文本比例维持在14%。
针对紧凑型模型优化的思维链集成
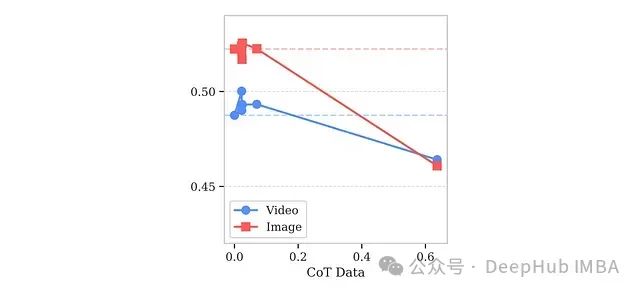
思维链(Chain-of-Thought,CoT)提示技术,即在训练过程中向模型展示明确的推理步骤,通常能显著增强大型模型的推理能力。然而,这一技术对较小规模多模态架构的影响尚未得到充分研究。为探索这一问题,研究者在Mammoth数据集中系统调整了CoT示例的比例,涵盖文本、图像和视频多种任务类型。
实验结果表明:
-
纳入极少量(0.02-0.05%)的CoT示例能略微改善模型性能,但更高比例的CoT数据会显著降低整体效果,尤其是在图像相关任务中。
-
这些发现提示,过多面向推理的文本数据可能会超出较小规模VLM的容量限制,从而损害其视觉表示能力和多模态理解效率。
视频序列长度对模型性能的影响分析
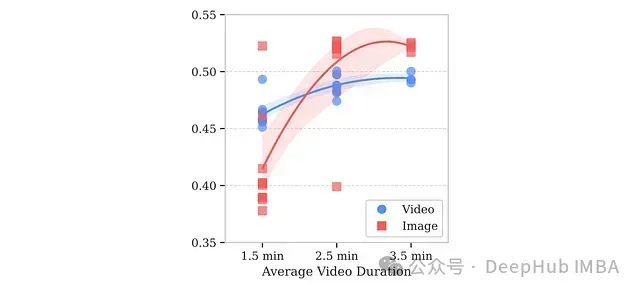
增加训练阶段的视频时长能提供更丰富的时间上下文信息,但同时也增加了计算资源需求。为确定最佳视频时长,研究团队在平均视频长度从1.5分钟到3.5分钟不等的条件下训练了多个SmolVLM变体。
研究发现:
-
当视频处理时长接近3.5分钟时,模型在视频和图像基准测试上均表现出显著性能提升,这可能归因于更有效的跨模态特征学习机制。
-
将视频时长延长至3.5分钟以上所带来的进一步性能提升有限,表明相对于增加的计算成本,收益已开始递减。
-
因此,适度延长视频序列长度对小型模型性能提升具有显著价值,但过长序列所带来的额外性能提升无法合理证明其计算成本的增加。
训练数据构成
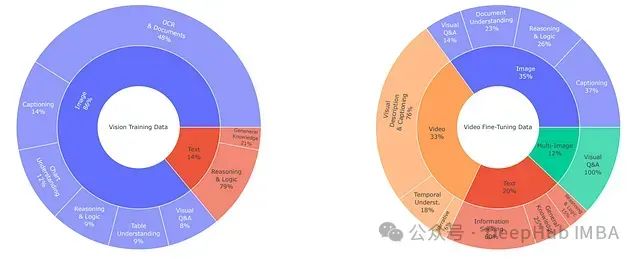
SmolVLM的训练分为两个关键阶段:视觉基础训练阶段和视频增强阶段。
视觉训练阶段利用了Idefics模型使用的数据集的优化组合,并增补了MathWriting等专业数据集。这一阶段包含多样化的视觉处理任务,如文档理解、图像描述和视觉问答(其中2%专门用于多图像推理能力培养)。此外,还包括图表理解、表格分析和视觉推理等高级任务。
为保持模型在纯文本任务中的性能水平,研究者保留了适量的通用知识问答和基于文本的推理与逻辑问题,包括数学计算和编程挑战等。
视频微调阶段维持了14%的文本数据比例和33%的视频内容以实现最优性能平衡。视频数据方面,视觉描述和字幕内容取样自LLaVA-video-178k、Video-STAR、Vript和ShareGPT4Video等数据集。时间理解任务数据来自Vista-400k,叙事理解能力则主要通过MovieChat和FineVideo数据集培养。多图像处理数据从M4-Instruct和Mammoth数据集中采样获得。
模型评估结果
主要性能表现
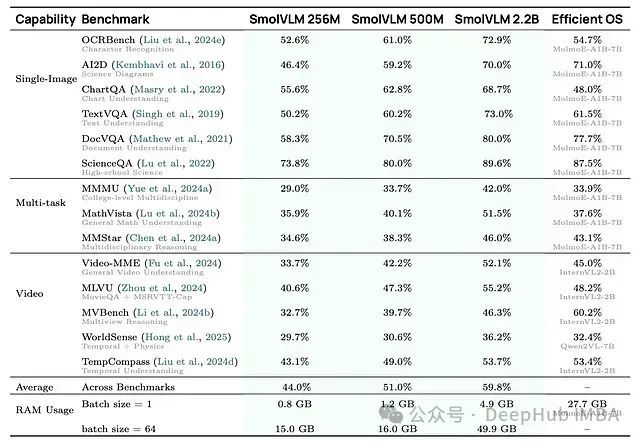
SmolVLM各变体在视觉-语言任务上的性能比较。
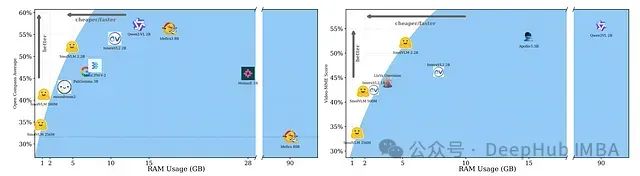
SmolVLM与其他先进小型VLM模型的性能对比。
研究评估表明:
-
小规模模型的卓越性能:尽管参数规模有限,SmolVLM在多种基准测试中展现出了强大的性能水平。其中,SmolVLM-2.2B在大多数评测中达到了59.8%的最高总体得分,甚至超越了如Idefics 80B等参数规模显著更大的模型。
-
计算效率与内存优化:与大型模型相比,SmolVLM系列展示出显著的计算效率和更低的内存占用。例如,SmolVLM-256M在单图像推理任务中仅需0.8GB VRAM,而同类任务下MolmoE-A1B-7B则需要27.7GB内存资源。
-
参数规模扩展效益:增加SmolVLM的参数规模能一致地提升各项基准测试性能。值得注意的是,即使是以视觉为主导的任务也能从语言模型容量扩展中获益,这表明语言模型组件对多模态推理能力具有重要影响。
-
与同类紧凑型VLM的竞争优势:SmolVLM-2.2B与其他小型VLM相比表现出显著竞争力,同时保持极低的GPU资源使用率。在多个基准测试中,它优于具有类似甚至更大参数规模的竞争模型,同时显著降低了VRAM消耗。
-
卓越的视频处理能力:SmolVLM在视频理解任务中表现尤为突出,在Video-MME和WorldSense等专业基准测试中超越了多个参数规模明显更大的模型。
设备端部署性能分析
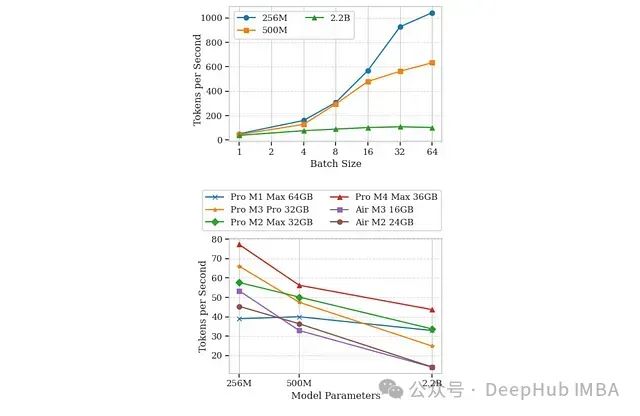
各模型版本的每秒标记处理吞吐量对比。
SmolVLM展现出适合设备端和边缘计算环境部署的关键特性:
-
在A100 GPU环境下,SmolVLM-256M实现了每秒0.8到16.3个样本的高吞吐量处理能力,且随批处理大小增加表现出良好的扩展性。
-
同样在A100环境中,SmolVLM-500M展示了良好的性能扩展特性(每秒处理0.7到9.9个样本),而2.2B参数变体则展现出中等水平的扩展性能(每秒0.6到1.7个样本),这主要受限于更高的计算需求。
-
在算力较低的L4 GPU环境中,SmolVLM-256M在批量大小为8时达到每秒2.7个样本的峰值吞吐量,证明了其在边缘计算设备上的适用性。
-
在L4环境下,受硬件条件限制,SmolVLM-500M和2.2B参数变体在较小批量大小条件下达到各自峰值性能(分别为每秒1.4和0.25个样本)。
-
通过优化的ONNX模型导出技术,SmolVLM实现了跨平台兼容性和更广泛的部署可能性。
-
SmolVLM-256M借助WebGPU技术在14英寸MacBook Pro(搭载M4 Max芯片)上实现了每秒高达80个解码标记的处理速度,展示了在浏览器环境中部署的可行性与效率。
下游应用场景
-
ColSmolVLM:较小规模的SmolVLM变体(256M和500M参数配置)能够在智能手机和便携式笔记本电脑等资源受限设备上实现高效多模态推理。这一应用实例有力证明了SmolVLM在设备端实际部署中的有效性。
-
Smol Docling:通过"DocTags"技术优化的256M参数SmolVLM特化版本在文档处理领域达到了与大型模型相当的性能水平,同时保持了紧凑的模型尺寸。这一成果突显了SmolVLM在专业文档理解任务中的高效率表现。
-
BioVQA:小规模SmolVLM模型在生物医学视觉问答领域展示出了令人鼓舞的结果,证明了这些模型在计算资源有限的医疗保健应用场景中的潜力。这一应用扩展展示了SmolVLM在专业垂直领域的适用性和有效性。
论文地址:
https://arxiv.org/abs/2504.05299
编辑:王菁
