阿里云PolarDB登顶TPC-C,揭秘其多主集群技术。通过RDMA等技术实现高性能横向扩展,突破单机瓶颈,为现代数字化业务提供核心基础设施。
原文标题:登顶TPC-C!阿里云自研数据库分布式扩展技术揭秘
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文中提到PolarDB在全球只读节点的设计上,避免了为RO节点存储额外的数据副本,节省了存储开销。这种设计方案有哪些潜在的风险或者限制?在哪些场景下可能不适用?
3、PolarDB通过深度融合RDMA/CXL等新型硬件来提升性能,这种软硬件协同的思路对数据库的未来发展有哪些启示?是否意味着未来的数据库需要更加依赖特定的硬件环境?
原文内容

近年来,云原生架构进一步推动了弹性扩展与低成本运维。其意义在于突破单机性能瓶颈,实现海量数据与高并发场景的支撑,通过多节点协同保障高可用与容灾能力,同时降低资源成本,并推动数据库从封闭系统向灵活、智能的分布式架构演进,成为现代数字化业务的核心基础设施。
日前,阿里云PolarDB云原生数据库以超越原记录2.5倍的性能一举登顶TPC-C基准测试排行榜,以每分钟20.55亿笔交易(tpmC)和单位成本0.8元人民币(price/tpmC)的成绩刷新TPC-C性能和性价比双榜的世界纪录。每一个看似简单的数字背后,都蕴含着无数技术人对数据库性能、性价比和稳定性的极致追求,PolarDB的创新步伐从未止步。
一、概述

本次TPC-C基准测试,我们所使用的是PolarDB for MySQL 8.0.2版。PolarDB MySQL版支持多主集群(Limitless),客户通过加读写节点(RW)的方式即可从PolarDB MySQL一主多读变配为PolarDB MySQL版多主集群(Limitless)。
PolarDB MySQL版多主集群(Limitless)支持多主多写、内存融合、分布式存储、秒级横向扩展,支持单表读写透明的跨机扩展到海量节点。本次TPC-C基准测试中 PolarDB 以2340个读写节点的形态(规格为48核512GB),支持了每分钟20.55亿笔交易(tpmC)。从tmpC和price/tpmC刷新TPC-C性能和性价比双榜的世界纪录。
早期的云原生关系型数据库主要形态是基于存储和计算分离的一写多读形态,虽然其可以很好地替换原生或者托管的MySQL/PG数据库,但是因其单写架构限制了其写能力的扩展。随着云原生数据库技术的不断演进,支持大规模部署和横向读写扩展的云原生数据库PolarDB MySQL版多主集群(Limitless)功能就此诞生。其核心优势是可弹性扩缩计算节点且每个节点都可处理读写请求,可在多个节点上实现并发写入。此外,其在保留单机高性能,高弹性的同时,利用RDMA/CXL等技术,对节点间的事务和数据进行高效融合,在保证事务一致性的前提下,实现高效的透明秒级横向跨机读写线性扩展。
本篇文章将详细介绍PolarDB MySQL版多主集群(Limitless)的整体架构,以及支撑其成功登顶TPC-C的核心技术创新点。
二、技术深入解读
(一)PolarDB MySQL版多主集群(Limitless)整体架构

图1: PolarDB MySQL版多主集群(Limitless)架构图
PolarDB MySQL版集群包含多个RW计算节点、多个RO计算节点、可选的Cache Coordinator节点组成,其底层基于分布式共享存储。每个RW节点均可读可写,并通过RDMA/CXL高速网络和Cache Coordinators通信,Cache Coordinators 负责集群元数据管理和事务信息协调,同时支持CDC功能,负责输出统一的全局Binlog。
此外,该架构支持将单一分区表的不同分区动态分布到不同RW节点上,并通过分区裁剪模块判断执行计划应该路由到哪个RW节点。因此,可支持不同分区在各RW节点并发写入,实现写能力的横向扩展,能够极大提升集群整体的并发读写性能。并且,集群还支持跨节点的分布式查询、分布式DML、分布式DDL,并通过RDMA内存融合的方式保证跨节点事务的一致性和原子性。此外,设计了全局RO节点来支持全局查询/多表联合查询/列存查询加速。
PolarDB的集群中多个RW计算节点采用对称架构,即其单个RW节点包含了传统分布式数据库的CN(协调节点)和DN(数据节点)节点的功能,不再需要客户去单独配置CN节点和DN节点的数量。对称节点的设计有显著的优势:
- 可充分提升资源利用率,避免因在不同负载下CN/DN某一个打满而另一个闲置的资源浪费;
- 可降低CN/DN分离带来的额外的通信成本,提升性能;
- 计算节点采用MySQL原始的语法解析/优化/执行器带来了100%的MySQL兼容性。
1.PolarTrans云原生事务系统
InnoDB原生事务系统是基于活跃事务列表实现的,但维护活跃事务列表需要全局大锁保护,成本开销较大,在高并发场景下容易成为整个系统的性能瓶颈点。另外,考虑到分布式事务一致性方案大多基于提交时间戳方案(TSO/TrueTime/HLC等),因此,PolarTrans通过提交时间戳技术(CTS)优化原生事务系统,核心数据结构为CTS log,由一段ring buffer组成,事务ID trx_id通过取模映射到其对应的slot,每个slot存储trx指针和cts值(事务提交时间戳)。其优化的核心思想是移除对复杂数据结构的维护,事务状态迭代、可见性判断等核心事务逻辑, 都是通过CTS log来完成,更加轻量级;同时PolarTrans将大部分的逻辑进行无锁优化,因此,PolarTrans事务系统对于读写混合场景、纯写场景都有较大的性能提升。
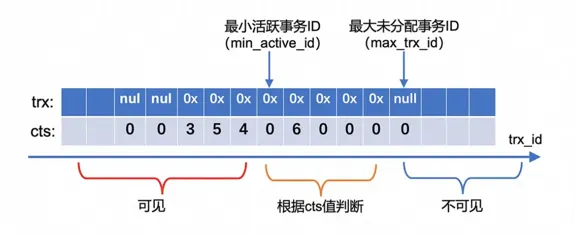
图2:CTS Log 结构图
2.分布式快照一致性
InnoDB原生快照一致性读依赖活跃事务列表维护事务状态,提供事务可见性判断,该机制在分布式多写场景中暴露严重缺陷:维护集群跨节点的全局活跃事务列表,引发高频全局锁竞争,扩展性随节点数增长而急剧下降。PolarDB基于PolarTrans以及RDMA来构建分布式事务系统,提供分布式快照一致性能力:
(1)集群中所有节点通过RDMA进行点对点互连,跨机共享RDMA注册的内存CTS Log来实现全局事务状态信息同步和跨物理机直接更新,避免通过中心节点维护全局活跃事务列表,同时CTS Log提供了事务远程提交,状态查询等能力。
(2)通过TSO或HLC两种时间戳管理方案,生成事务提交时间戳,分布式写事务的所有子事务通过相同的时间戳进行原子提交,分布式读通过统一的时间戳结合CTS Log判断数据可见性,保证分布式读一致性。
3.多机事务一致性:云原生分布式事务
我们设计实现了一种软硬件协同的云原生分布式事务方案,可实现良好的多机写扩展性。核心思想是利用RDMA等新型硬件低延迟优势,加速提交流程中Prepare阶段和Commit阶段的执行。相对于传统或现有的数据库分布式事务方案来说,我们所设计的软硬件协同的云原生分布式事务方案的核心优化点有:
(1)通过利用RDMA新型硬件低延迟的优势和LSN机制,优化了分布式事务Prepare阶段的执行流程,仅需执行远端RDMA读操作就可确定事务的Prepared状态,避免了Prepare阶段协调节点与参与节点之间的SQL交互开销。
(2)设计了CTS Log记录事务提交时间戳,协调节点CN通过RDMA将事务提交时间戳cts,以微秒级延迟写入参与节点PN的CTS Log,优化了Commit阶段的执行逻辑,使得Commit阶段可以异步执行。
4.多机并行DDL
PolarDB全局共用全量dd信息的同时将表进行拆分,不同RW节点负责读写不同分表,以提升单表的吞吐和数据承载能力。在实际业务中对表拆分后,如何控制所有分表的DDL流程,协调与逻辑表的关系,防止表的元信息不一致,是分布式DDL设计需要考虑的难题。
(1)DDL并发控制:在分布式表场景下,为了防止同一张表出现并发DDL,我们复用库/表锁的思想和管理逻辑,为全局库/表增加一个XB锁类型,执行DDL时首先拿XB锁,从而避免并发DDL。
(2)分布式DDL原子性保证:设计一种基于多阶段提交协议的机制,在Commit阶段之前的任何时间点,如果DDL执行过程发生异常,会立即报告给协调节点CN;CN向所有DN发送指令,回滚DN节点上执行的DDL操作,从而保证分布式DDL操作的原子性。
(三)高可用机制
为了实现数据库系统的高可用,传统OLTP数据库的做法是为每个主节点(Primary)维护一个或多个备节点(Standby)。为了降低成本且保证系统的高可用,我们提供了可供用户选择的多样化高可用方案。
首先,基于私有RO节点的高可用方案,用户可选择为每个RW节点配置私有RO节点,私有RO节点和RW共享同一份数据,无需额外存储数据。当一个RW节点发生故障时,可将其私有RO节点秒级切换为RW,接管流量请求,集群整体性能不会受到影响。另一方面,如果用户没有为RW节点配置私有RO,当RW节点发生故障时,我们还提供RW节点间互为备节点的机制来保证高可用。当一个RW节点发生故障时,可选择另外一个低负载的RW节点来快速接管故障节点上的流量,只需将故障节点上的库表重映射到低负载的RW即可,但由于资源限制在高压力负载下可能会影响集群整体性能。
(四)全局RO节点
为了支持跨表/库的全局查询/多表联合查询,我们设计了全局只读(RO)节点。考虑到集群中的每个RW节点都可以看到共享存储中的所有数据,因此将全局只读节点设计为多个RW节点的聚合库。全局只读节点可以直接查询所有RW节点写入的数据,避免了从多个RW节点查询数据并聚合它们。同时,不需要为全局RO节点存储额外的数据副本,节省了聚合库的额外存储开销。对于跨多个RW节点的全局查询,数据库集群提供透明路由,通过PolarProxy将全局查询自动路由到全局只读节点上。
(五)极致的性能和扩展性
使用TPC-C基准测试程序对PolarDB MySQL版Limitless超大规模集群(2340个读写节点,节点规格48核512GB)进行了性能测试,TPC-C被认为是数据库领域的“奥林匹克”,它是OLTP(联机交易处理系统)数据库性能测试唯一的国际权威榜单。
1.超大规模集群下稳定的性能

图3:摘自阿里云 PolarDB TPCC 报告
在8小时持续压测过程中,集群整体tpmC的波动率一直处于0.16%以内(标准要求2%以内),实现了8小时持续、无任何错误、稳定的压测,且集群整体tpmC高达20.55亿,刷新TPC-C世界纪录,登顶世界第一。
2.超大规模集群下高可用和容灾能力

图4:PolarDB TPCC 容灾场景性能数据
在容灾场景测试中,执行了不同组件的故障测试,真实的物理机器断电,验证了集群在物理机器故障的突发情况下,能在10 秒内完成故障容灾切换,2分钟内完成整体性能的恢复,容灾测试过程中对集群整体性能的影响控制在2%以内(标准要求10%以内),并且可以保证数据不丢失,分布式事务一致性等。
3.秒级水平扩容能力

图5:秒级水平扩容测试结果
在横向水平扩容测试时,创建的4个DB最开始都在RW1上,压测过程中,逐渐增加RW节点个数,并将DB2-DB4依次绑定到新增的RW节点。图中展示了扩容过程中集群整体的性能变化,表明集群可以实现秒级的水平扩容。
三、整体总结
PolarDB是第一个深度融合RDMA/CXL等新硬件的云原生关系型数据库,支持大规模高性能的横向跨机读写扩展,最高可扩展至数千个计算节点。该架构支持高性能的跨节点事务一致性,深度融合RDMA技术的云原生事务系统PolarTrans,弹性并行查询ePQ,其分布式能力实现性能近线性扩展。
此外,通过索引结构、I/O路径等90多种优化技术,集群中每个节点都实现了极致的单机性能。值得强调的是,PolarDB MySQL版多主集群(Limitless)成功刷新TPC-C世界纪录,表明PolarDB创新的可横向跨机读写扩展的多主多写云原生架构,不仅突破了单集群的扩展性瓶颈,还成功扛住了全球最大规模的并发交易峰值,在性能、可扩展性等多个维度均处于全球领跑者位置。
云原生数据库 PolarDB MySQL 版
PolarDB 100%兼容 MySQL,交易和分析性能最高分别是开源数据库的6倍和400倍,TCO 低于自建数据库50%。
点击阅读原文可以免费试用哦。