字节UNO模型在多主体图像生成中达SOTA,通过“模型-数据共同进化”提升图像质量和多样性。教程已上线HyperAI超神经。
原文标题:多主体驱动生成能力达SOTA,字节UNO模型可处理多种图像生成任务
原文作者:数据派THU
冷月清谈:
字节跳动Intelligent Creation团队提出的UNO模型,通过扩散Transformer模型和“模型-数据共同进化”范式,有效提升了多主体图像生成任务中的数据可扩展性和主体扩展性。该模型以FLUX为基础,能够处理图像生成任务中的不同输入条件,并在DreamBench和多主体驱动生成的基准测试中取得了SOTA级别的DINO和CLIP-I分数,表明其在主体相似性和文本可控性方面表现出色。用户可以通过HyperAI超神经官网的教程体验UNO模型,上传图片并输入文本描述,即可生成定制化图像。
怜星夜思:
1、UNO模型采用的“模型-数据共同进化”范式,相较于传统图像生成模型,有哪些优势和潜在的局限性?
2、文章提到UNO模型在多主体驱动生成方面表现出色,那么在处理更复杂场景,例如包含大量主体、复杂光照条件或艺术风格迁移时,UNO模型会面临哪些挑战?
3、文章中展示了UNO模型将Logo印在杯子上的例子,如果我想用UNO模型生成更具有创意的图像,比如让猫咪穿上宇航服在月球上漫步,需要注意哪些Prompt的技巧?
2、文章提到UNO模型在多主体驱动生成方面表现出色,那么在处理更复杂场景,例如包含大量主体、复杂光照条件或艺术风格迁移时,UNO模型会面临哪些挑战?
3、文章中展示了UNO模型将Logo印在杯子上的例子,如果我想用UNO模型生成更具有创意的图像,比如让猫咪穿上宇航服在月球上漫步,需要注意哪些Prompt的技巧?
原文内容


「UNO:通用定制化图像生成」教程已上线至 HyperAI超神经官网的教程板块中,欢迎体验!
如今,主体驱动生成 (subject-driven generation) 已经广泛应用于图像生成领域,但其在数据可扩展性和主体扩展性方面仍面临诸多挑战,例如从单主体数据集转向多主体并对其进行扩展尤为困难;目前的热门研究方向是单主体,在面对多主体生成任务时表现欠佳。
针对于此,字节跳动 Intelligent Creation 团队利用扩散 Transformer 模型本身具备的上下文生成能力,生成了具有高度一致性的多主体配对数据,并以 FLUX 为基础模型提出了 UNO 模型,能够处理图像生成任务中的不同输入条件。其借助「模型-数据共同进化」的新范式,在优化模型性能的同时,丰富训练数据,提高生成图像的质量和多样性。
研究人员在 DreamBench 和多主体驱动生成的基准测试上进行了大量实验。UNO 在这两项任务中均取得了最高的 DINO 和 CLIP-I 分数,表明其在主体相似性和文本可控性方面表现出色,能力达 SOTA 级别。
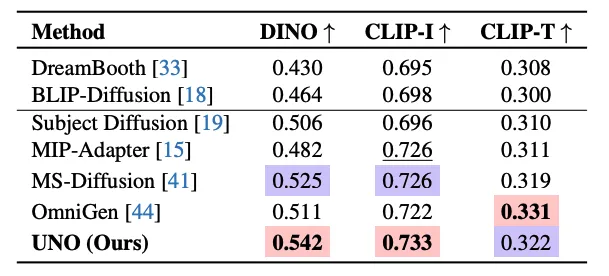
多主体驱动生成评测结果,UNO 达 SOTA
目前,「UNO:通用定制化图像生成」教程已上线至 HyperAI超神经官网的教程板块中,点击下方链接即可快速体验 ⬇️
教程链接:https://go.hyper.ai/XELg5
Demo 运行
1. 登录 hyper.ai,在「教程」页面,选择「UNO:通用定制化图像生成」,点击「在线运行此教程」。
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。

3. 选择「NVIDIA GeForce RTX 4090」以及「PyTorch」镜像。OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
HyperAI超神经专属邀请链接(直接复制到浏览器打开):
https://openbayes.com/console/signup?r=Ada0322_NR0n
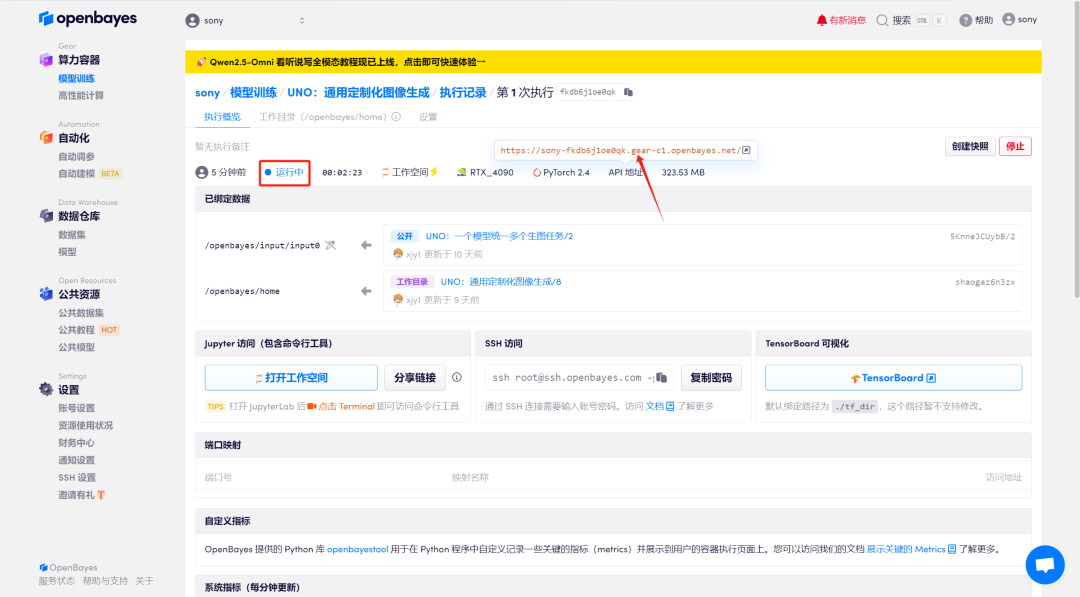
4. 等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。
效果展示
在「Prompt」中输入描述生成图片的文本,然后在「Ref Img」中上传生成图片的图片内容。调整「Gneration Width/Height」以选择生成图片的长/宽,最后点击「Generate」生成。
参数调整简介:
* Number of steps: 表示模型的迭代次数或推理过程中的步数,代表模型用于生成结果的优化步数。更高的步数通常会生成更精细的结果,但可能增加计算时间。
* Guidance: 它用于控制生成模型中条件输入(如文本或图像)对生成结果的影响程度。较高的指导值会让生成结果更加贴近输入条件,而较低的值会保留更多随机性。
* Seed: 是随机数种子,用于控制生成过程中的随机性。相同的 Seed 值可以生成相同的结果(前提是其他参数相同),这在结果复现中非常重要。
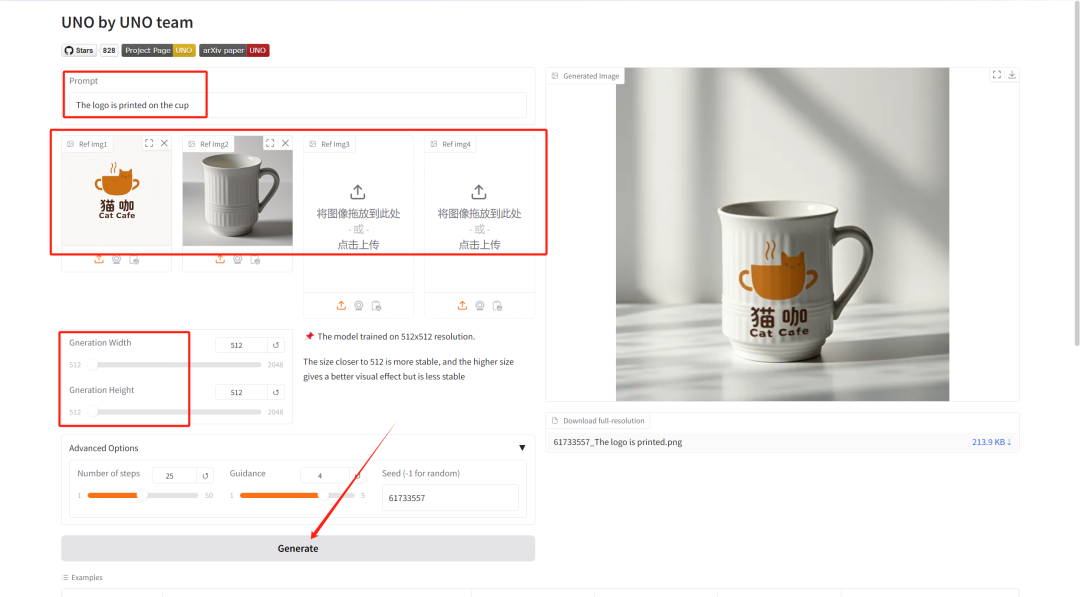
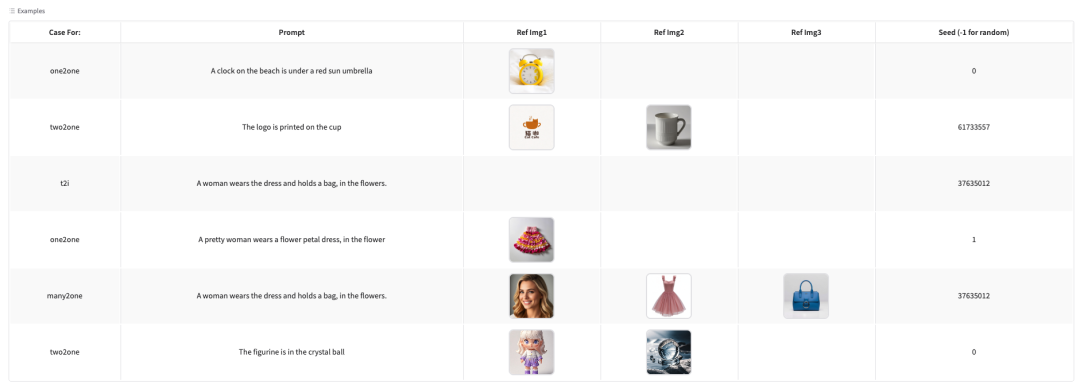
这里我们上传了一张 logo 和一张杯子的图片,文本描述为:The logo is printed on the cup(把 logo 印在杯子上)。可以看到模型很准确地为我们处理了图片。

教程还为大家提供了多类 Examples,欢迎感兴趣的读者通过下方链接体验 ⬇️
教程链接:https://go.hyper.ai/XELg5
编辑:王菁
