通用人工智能研究院发布了 Minecraft Universe (MCU),一个面向通用智能体评测的生成式开放世界平台,旨在革新AI评测范式,推动AI技术发展。
原文标题:ICML Spotlight | MCU:全球首个生成式开放世界基准,革新通用AI评测范式
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到现有 SOTA 模型在 MCU 平台上表现不佳,尤其是在泛化和创造性方面。那么,你认为未来提升开放世界 AI 的关键方向是什么?是需要更强大的算力、更先进的算法,还是其他什么?
3、MCU 平台利用 GPT-4o 和 VLM 实现了任务的自动生成和评估。这种自动化评测方式,相比传统的人工评测,有哪些优势和局限性?
原文内容

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。
为此,我们构建了 Minecraft Universe(MCU) ——一个面向通用智能体评测的生成式开放世界平台。MCU 支持自动生成无限多样的任务配置,覆盖丰富生态系统、复杂任务目标、天气变化等多种环境变量,旨在全面评估智能体的真实能力与泛化水平。该平台基于高效且功能全面的开发工具 MineStudio 构建,支持灵活定制环境设定,大规模数据集处理,并内置 VPTs、STEVE-1 等主流 Minecraft 智能体模型,显著简化评测流程,助力智能体的快速迭代与发展。

-
论文地址:https://arxiv.org/pdf/2310.08367
-
代码开源:https://github.com/CraftJarvis/MCU
-
项目主页:https://craftjarvis.github.io/MCU
-
MineStudio:https://github.com/CraftJarvis/MineStudio
🚨开放世界AI,亟需理想的评测基准!
传统测试基准包含有标准答案的任务(如代码、推理、问答),但开放世界任务 Minecraft 有着完全不同的挑战:
-
目标开放多样:任务没有唯一解,策略可以千变万化;
-
环境状态庞杂:状态空间近乎无限,还原真实世界复杂度;
-
长周期任务挑战:关键任务持续数小时,智能体需长期规划。
在这样的环境中,我们需要的不只是一个评分系统,而是一个维度丰富、结构多元的综合评测框架。
🌌MCU:为开放世界 AI 打造的「全方位试炼场」
当前已有不少 Minecraft 的测试基准,但它们普遍面临「三大瓶颈」:
-
任务单一:局限于如挖钻石、制造材料等少数几个场景的循环往复。
-
脱离现实:部分建模任务甚至超出了普通人类玩家的能力范畴。
-
依赖人工评测:效率低下,导致评测难以规模化推广。
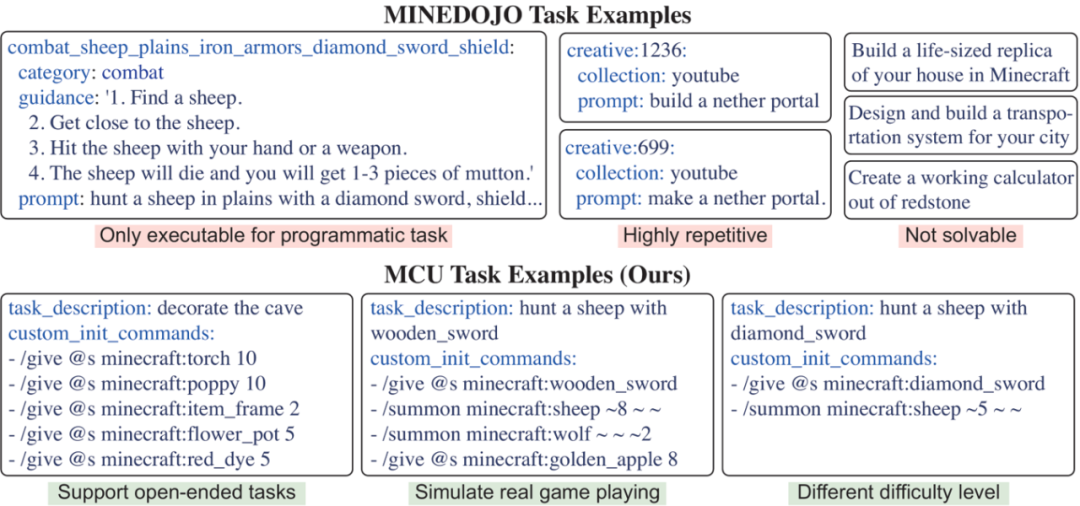
与之前 minecraft 测试基准对比示意图。
针对以上痛点,MCU 实现了以下三大核心突破:
一:3,452 个原子任务 × 无限组合生成,构筑海量任务空间
MCU 构建了一个覆盖真实玩家行为的超大任务库:
-
11 大类 × 41 子类任务类型:如挖矿、合成、战斗、建造等;
-
每个任务都是「原子级粒度」:可独立测试控制、规划、推理、创造等能力;
-
支持 LLM 动态扩展任务,比如:用钻石剑击败僵尸、雨天徒手采集木材、
🔁任意组合这些原子任务,即可生成无限的新任务,每一个都对 AI 是全新挑战!
模拟多样化真实世界挑战。
二. 任务全自动生成 × 多模态智能评测,革新评估效率
GPT-4o 赋能,一句话生成复杂世界:
-
自动生成完整的任务场景(包括天气、生物群系、初始道具等)。
-
智能验证任务配置的可行性,有效避免如「用木镐挖掘钻石」这类逻辑错误型任务。
VLM(视觉语言模型)驱动,彻底改变了传统人工打分的低效模式:
-
基于 VLM 实现对任务进度、控制策略、材料利用率、执行效率、错误检测及创造性六大维度的智能评分。
-
模型自动生成详尽的评估文本,评分准确率高达 91.5%;
-
评测效率相较人工提升 8.1 倍,成本仅为人工评估的 1/5!
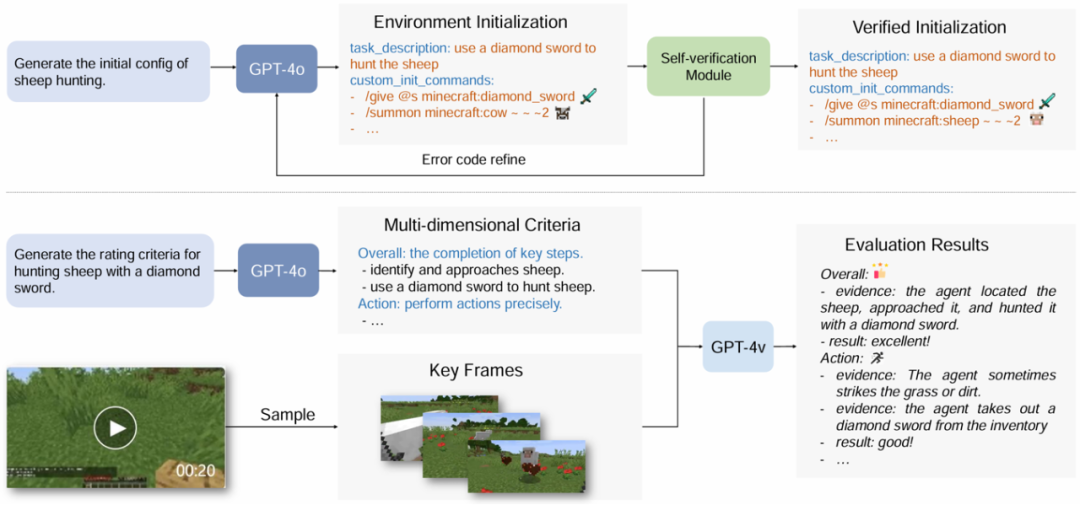
任务生成 x 多模态评测流程图。
三:高难度 × 高自由度的「试金石」任务设计,深度检验泛化能力
MCU 支持每个任务的多种难度版本,如:
-
「白天在草原击杀羊」VS「夜晚在雨林躲避怪物并击杀羊」;
-
「森林里造瀑布」VS「熔岩坑边缘建造瀑布」。
这不仅考验 AI 是否能完成任务,更深度检验其在复杂多变环境下的泛化与适应能力。
📉打破「模型表现良好」的幻象:现有 SOTA 模型能否驾驭 MCU ?
我们将当前领域顶尖的 Minecraft 智能体引入 MCU 进行实战检验:GROOT:视频模仿学习代表;STEVE-I:指令执行型控制器;VPT(BC/RL):基于 YouTube 行为克隆训练而成的先驱。结果发现,这些智能体在简单任务上表现尚可,但在面对组合任务和陌生配置场景时,完成率急剧下降,且错误识别与创新尝试是其短板。
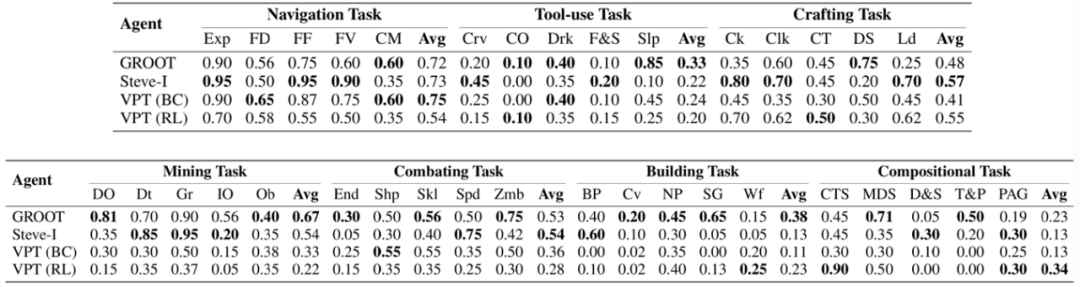
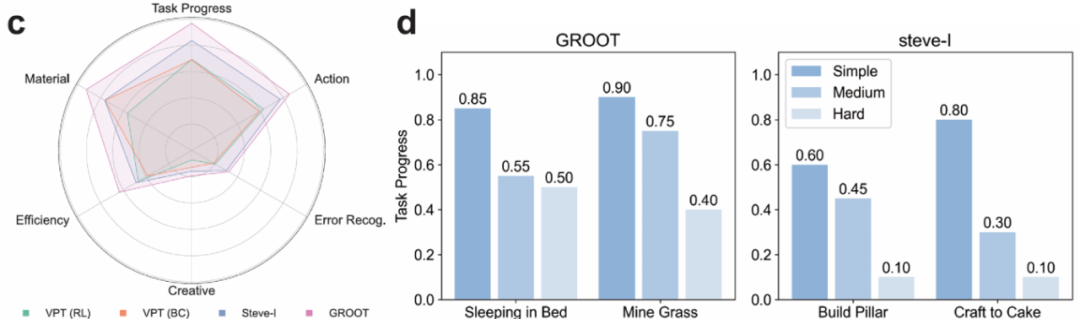
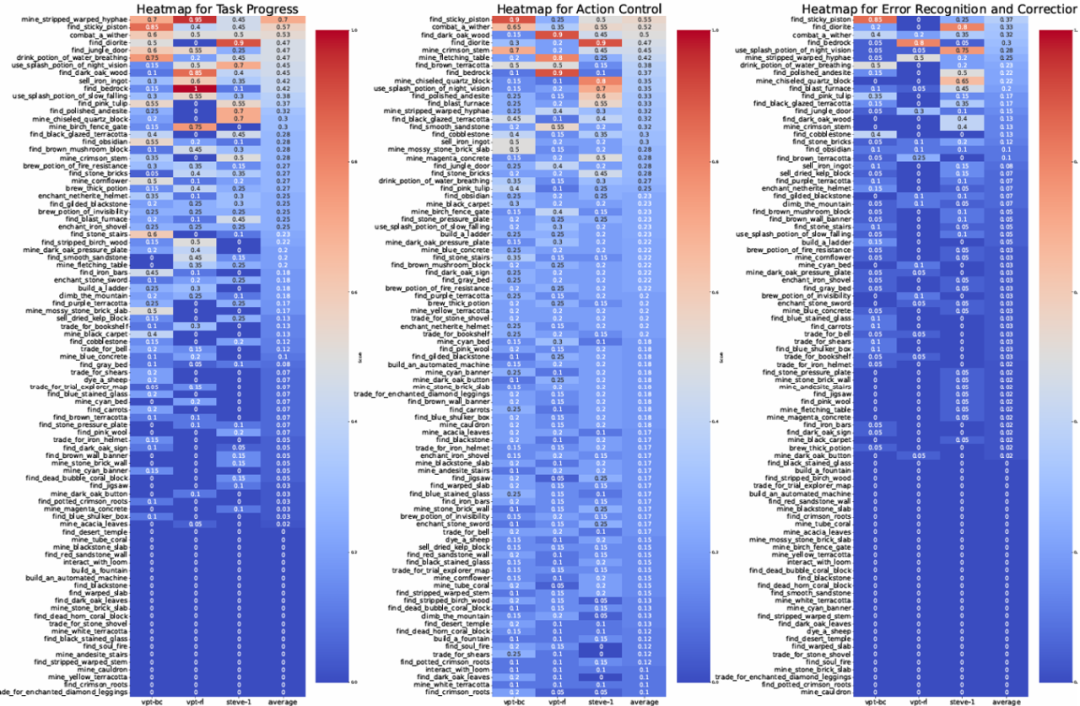
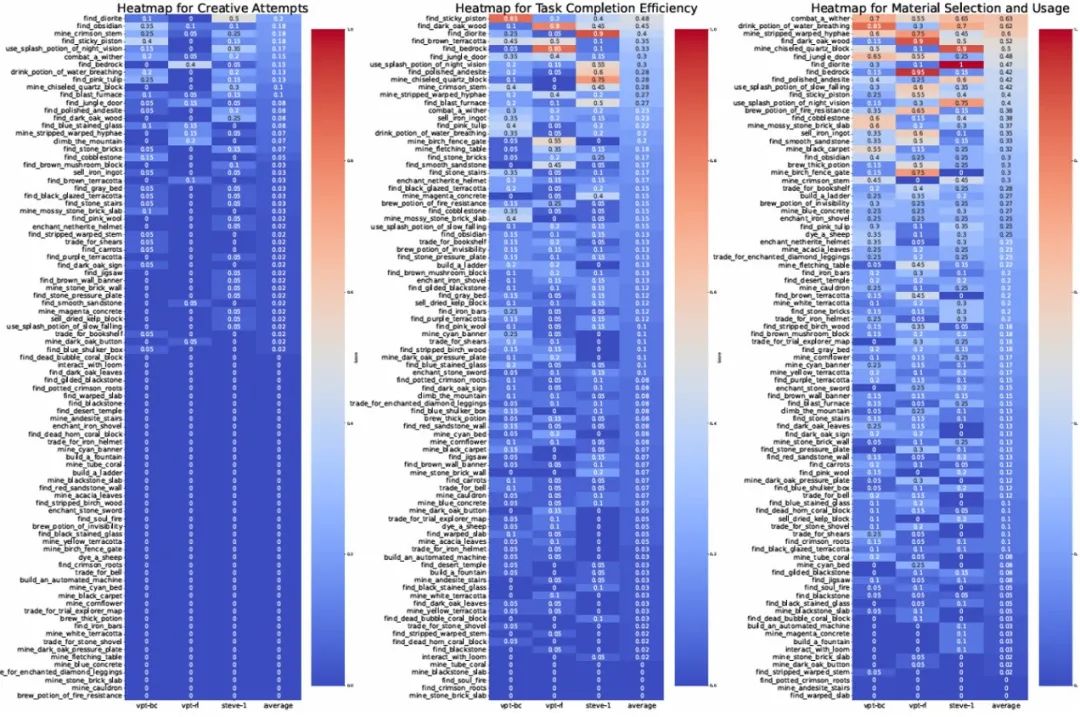
SOTA 模型在 MCU 上的测试结果。
研究团队引入了更细粒度的任务进度评分指标(Task Progress),区别于传统 0/1 式的「任务完成率」,它能动态刻画智能体在执行过程中的阶段性表现,哪怕任务失败,也能反映其是否在朝正确方向推进。
实验发现,当前主流模型如 GROOT、STEVE-I、VPT-RL,在原子任务中尚有可圈可点的表现,但一旦面对更具组合性和变化性的任务,其成功率便会骤降。甚至对环境的微小改动也会导致决策混乱。比如「在房间内睡觉」这个看似简单的任务,仅仅是将床从草地搬到屋内,就让 GROOT 频繁误把箱子当床点击,甚至转身离开现场——这揭示了现有模型在空间理解与泛化上的明显短板。
更令人警醒的是,智能体在建造、战斗类任务中的「创造性得分」与「错误识别能力」几乎全面落后。这说明它们尚未真正具备人类那种「发现问题、调整策略」的自主意识,而这正是通用智能迈向下一个阶段的关键。
MCU 的评测结果首次系统性地揭示了当前开放世界智能体在「泛化、适应与创造」这三大核心能力上存在的鸿沟,同时也为未来的研究指明了方向:如何让 AI 不仅能高效完成任务,更能深刻理解任务的本质,并创造性地解决复杂问题。
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com