《Chaos》特刊聚焦数据驱动的复杂系统建模,利用机器学习等新方法,在网络扰动检测、信息分解及临界转变预测等方面取得突破。
原文标题:Chaos:数据驱动的复杂系统建模特刊概览
原文作者:数据派THU
冷月清谈:
《Chaos》期刊特刊聚焦数据驱动的复杂系统建模,展示了跨学科的最新研究成果。特刊结合机器学习与双曲几何嵌入、信息分解等方法,在检测网络局部扰动及分析癫痫脑网络响应中取得了突破。主要研究包括:
1. **网络扰动检测**:提出利用双曲几何嵌入检测网络局部扰动的新方法,并应用于分析癫痫手术对大脑区域的影响。
2. **信息分解**:运用整合信息分解框架分析计算机和神经元网络,揭示网络结构拓扑细节。
3. **盆地熵**:提出盆地熵作为时滞系统分岔的指标,用于捕获吸引盆的相关性质。
4. **自适应储备池计算**:提出一种自适应储备池计算架构,用于预测非线性动力系统中临界转变的发生。
5. **循环神经网络**:揭示循环神经网络中行为雪崩与内部神经元动力学之间存在复杂关系。
6. **电网同步动力学**:分析电网结构对相位振荡器同步动力学的影响,揭示不同拓扑下的同步特性。
7. **朗之万方程与神经常微分方程**:结合N维朗之万方程与神经常微分方程,用于预测电力价格时间序列。
8. **高阶相互作用网络聚类系数**:提出适用于超图的聚类系数,揭示高阶互动的特性。
9. **股票市场订单转换**:使用马尔可夫链模型分析中美贸易战期间股票市场订单数据,揭示交易者行为模式。
1. **网络扰动检测**:提出利用双曲几何嵌入检测网络局部扰动的新方法,并应用于分析癫痫手术对大脑区域的影响。
2. **信息分解**:运用整合信息分解框架分析计算机和神经元网络,揭示网络结构拓扑细节。
3. **盆地熵**:提出盆地熵作为时滞系统分岔的指标,用于捕获吸引盆的相关性质。
4. **自适应储备池计算**:提出一种自适应储备池计算架构,用于预测非线性动力系统中临界转变的发生。
5. **循环神经网络**:揭示循环神经网络中行为雪崩与内部神经元动力学之间存在复杂关系。
6. **电网同步动力学**:分析电网结构对相位振荡器同步动力学的影响,揭示不同拓扑下的同步特性。
7. **朗之万方程与神经常微分方程**:结合N维朗之万方程与神经常微分方程,用于预测电力价格时间序列。
8. **高阶相互作用网络聚类系数**:提出适用于超图的聚类系数,揭示高阶互动的特性。
9. **股票市场订单转换**:使用马尔可夫链模型分析中美贸易战期间股票市场订单数据,揭示交易者行为模式。
怜星夜思:
1、文章提到了多种复杂系统建模方法,例如双曲几何嵌入、信息分解、储备池计算等。在实际应用中,如何选择最合适的建模方法?有没有通用的选择标准或原则?
2、特刊中多篇文章都涉及到了“涌现”现象,例如,同步、混沌、相变等。这种现象在复杂系统中非常常见,我们应该如何理解“涌现”?
3、文章提到了数据驱动建模在复杂系统中的应用。那么,数据驱动建模与传统的基于机理的建模方法相比,有哪些优缺点?在什么情况下应该选择数据驱动建模?
2、特刊中多篇文章都涉及到了“涌现”现象,例如,同步、混沌、相变等。这种现象在复杂系统中非常常见,我们应该如何理解“涌现”?
3、文章提到了数据驱动建模在复杂系统中的应用。那么,数据驱动建模与传统的基于机理的建模方法相比,有哪些优缺点?在什么情况下应该选择数据驱动建模?
原文内容

本文共3300字,建议阅读9分钟
如何利用数据驱动方法解析复杂系统的规律?

为什么人类心脏的数万亿细胞能自发同步搏动?
气候系统为何在临界点突然发生剧变?
从大脑神经元到全球供应链,复杂系统如何主宰世界的「秩序与失控」?
2021年诺贝尔物理学奖将聚光灯投向复杂系统科学,揭示了系统背后的隐藏规律:从神经网络到生态演化,从病毒传播到金融震荡,那些广泛存在的涌现现象,例如,同步、混沌、相变等,都源自系统内部自组织的网络结构,而非中央控制器。在这个数据洪流奔涌的时代,不同领域的学者们正用全新的模型、方法,结合机器学习技术,推动复杂系统领域的创新性研究。
Chaos期刊重磅推出「数据驱动的复杂系统建模」特刊,汇集计算或数据驱动模型中提出的复杂系统新见解,以及表征集体行为或网络结构的新方法。集智编辑部深入研读特刊内容,精选其中具有突破性的研究成果,为大家带来系统性概括和梳理,希望能给广大研究者带来切实可行的启发和思考,助力跨学科创新探索。我们正站在科学范式变革的关口:当海量数据遇见复杂系统理论,那些曾被视为不可预测的混沌,终将显现深藏其中的秩序之美。

特刊地址:https://pubs.aip.org/cha/collection/13407/Data-Driven-Models-and-Analysis-of-Complex-Systems
1. 检测潜在双曲嵌入空间中网络的局部扰动
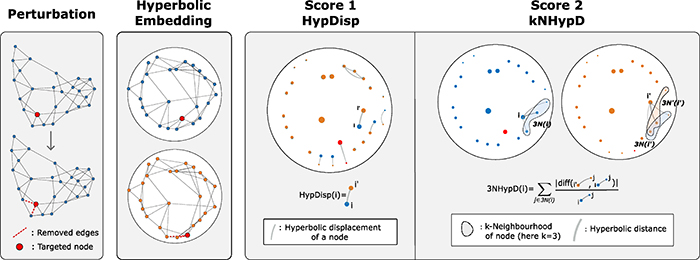
双曲扰动分数计算流程
本文介绍了两种检测网络局部扰动的新分数,考虑对网络进行非欧几里得表征,将它们嵌入到双曲几何的Poincaré disk model中。该方法对真实大脑网络进行了潜在几何表征,识别并量化癫痫手术对大脑区域的影响。
地址:https://pubs.aip.org/aip/cha/article/34/6/063117/3296060/Detecting-local-perturbations-of-networks-in-a?searchresult=1
2. 整合信息分解揭示计算机和体外神经元网络的主要结构特征
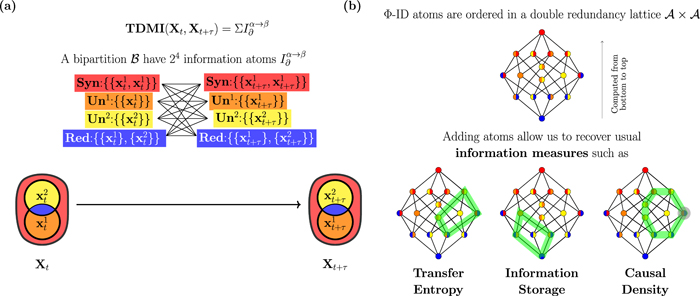
整合信息分解框架
整合信息分解(Φ-ID)允许人们探索信息在系统各部分之间流动的模式,文章使用Φ-ID框架对计算机和体外数据进行分析,将通常的传递熵测度分解为协同、冗余和特有信息传递模式,证明了特有信息传递是从网络活动数据中揭示结构拓扑细节最相关的度量,而冗余信息仅为该应用引入了剩余信息。
主题:信息论熵,计算机仿真,网络理论,神经科学,生物信息传递
地址:https://pubs.aip.org/aip/cha/article/34/5/053139/3295339/Integrated-information-decomposition-unveils-major?searchresult=1
3. 盆地熵(Basin entropy)作为时滞系统分岔的指标

平面上的吸引盆,由初始的函数参数决定
考虑一个简单的时滞系统,由一个具有线性延迟反馈项的双稳系统组成。文章证明了盆地熵捕获了两个共存吸引子吸引盆的相关性质。此外,盆地熵可以捕获Hopf分岔的渐进性,因为在不动点变得不稳定之前,一个与不动点共存的振荡极限环行为出现。新的极限环改变了吸引力盆地的结构,从而被盆地熵所捕获。
主题:非线性系统,混沌系统,熵,反馈控制系统
地址:https://pubs.aip.org/aip/cha/article/34/5/053113/3287873/Basin-entropy-as-an-indicator-of-a-bifurcation-in?searchresult=1
4. 自适应储备池计算(Adaptable reservoir computing):一种用于预测非线性动力系统中临界转变的无模型数据驱动范式
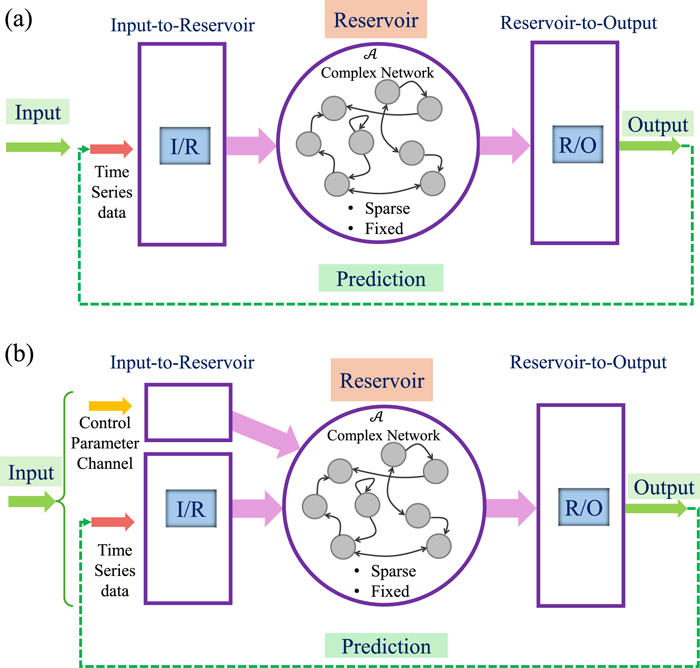
储备池计算架构
如何在系统方程未知的情况下仅根据数据预测临界转变的发生?文章提出了一种自适应储备池计算架构,模型设定是,系统动力学目前处于一个具有振荡动力学的正常吸引子上,未来分岔参数发生变化,可能会发生临界转变,切换到另一个吸引子。为预测临界转变,储备池计算不仅学习了目标系统在某个特定参数值下的动态“气候”,更重要的是要从数据中发现系统动力学如何随分岔参数变化。
地址:https://pubs.aip.org/aip/cha/article/34/5/051501/3287956/Adaptable-reservoir-computing-A-paradigm-for-model?searchresult=1
延伸阅读:复杂系统的数据驱动建模:储备池计算教程,以洛伦兹吸引子为例,介绍了储备池计算在训练、预测和优化方面的代码,并讨论了优化以找到正确参数的重要性。
5. 循环神经网络中行为雪崩与内部神经元动力学之间的非平凡关系(non-trivial relationship)

RNN架构,神经元的动力学状态通过tanh机或函数转换成发放率
文章通过训练处于混沌状态的循环神经网络生成服从幂律分布的行为状态,并发现即使改变网络连接,神经元雪崩大小分布依旧保持不变,从而揭示行为统计特性与神经元内部动力学之间存在复杂且非一一对应的平凡关系。
主题:动力学系统,相变,MATLAB,人工神经网络,数学建模,二分序列
地址:https://pubs.aip.org/aip/cha/article/34/5/053104/3287645/Non-trivial-relationship-between-behavioral?searchresult=1
6. 电网模型上相位振荡器的同步动力学
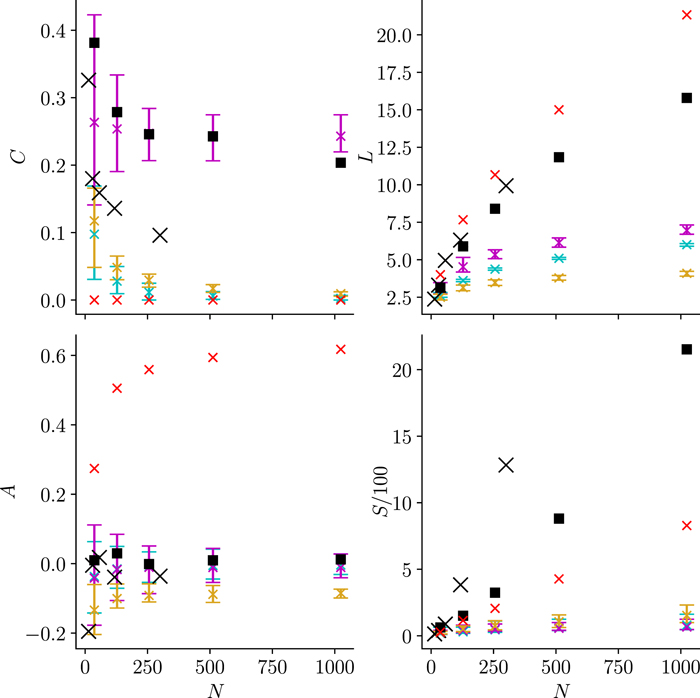
ENTSO-E网络模型(黑色方块)、IEEE测试(黑色交叉)、小世界(紫色)、无标度(黄色)、随机(绿松石色)和规则网络(2d晶格)的拓扑和频谱特征
通过分析欧洲和美国电网及典型网络模型的拓扑和谱特性,文章探讨了这些结构对具有异质自然频率相位振荡器同步动力学的影响,发现电网结构降低了暂时稳定同步的能力,并揭示了不同拓扑下同步动力学的非平凡共性。
主题:耦合振荡器,Kuramoto模型,混沌系统,电力,电力电子学,图论,网络理论,频谱现象和性质
地址:https://pubs.aip.org/aip/cha/article/34/4/043131/3282305/Synchronization-dynamics-of-phase-oscillators-on?searchresult=1
近期颁发的2025年玻尔兹曼奖,授予者之一为同步现象研究开拓者藏本由纪 Yoshiki Kuramoto,Kuramoto模型推荐阅读:从无序到有序:2025年玻尔兹曼奖得主如何揭示自然界的隐藏scaling law
7. 用n维朗之万方程和神经常微分方程进行预测
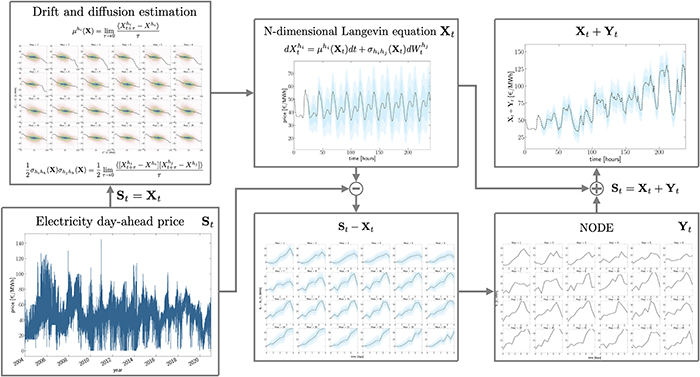
时间序列预测框架示意图
文章提出了一种结合N维朗之万方程与神经常微分方程的数据驱动模型,用以系统捕捉和预测电力价格时间序列中的平稳与非平稳特性,并在西班牙电力日内市场中验证了其有效性。
主题:能源预测、能源市场、人工神经网络、机器学习、复杂系统理论、朗之万动力学、随机过程、时间序列分析
地址:https://pubs.aip.org/aip/cha/article/34/4/043105/3280361/Forecasting-with-an-N-dimensional-Langevin?searchresult=1
8. 高阶相互作用网络的聚类系数
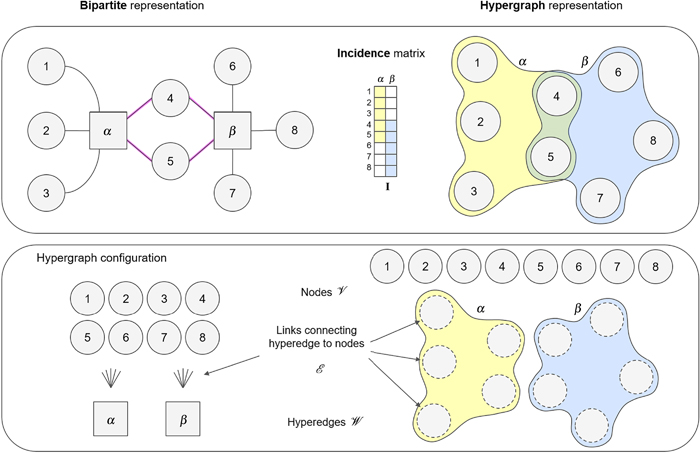
超图和它的不同表示方式,以及四元motif
文章提出了一种适用于无向和有向超图的“四元聚类系数”,并通过与随机超图的比较发现真实超图中存在大量高聚类节点,这些节点往往具有大度数和大超边,表明仅基于二元交互的聚类分析无法揭示高阶互动的特性。
主题:结构分析,网络分析,图论,网络理论,拓扑性质,复杂系统理论
地址:https://pubs.aip.org/aip/cha/article/34/4/043102/3280414/Clustering-coefficients-for-networks-with-higher?searchresult=1
9. 2018年中美贸易战期间高频股票市场订单转换:离散时间马尔可夫链分析
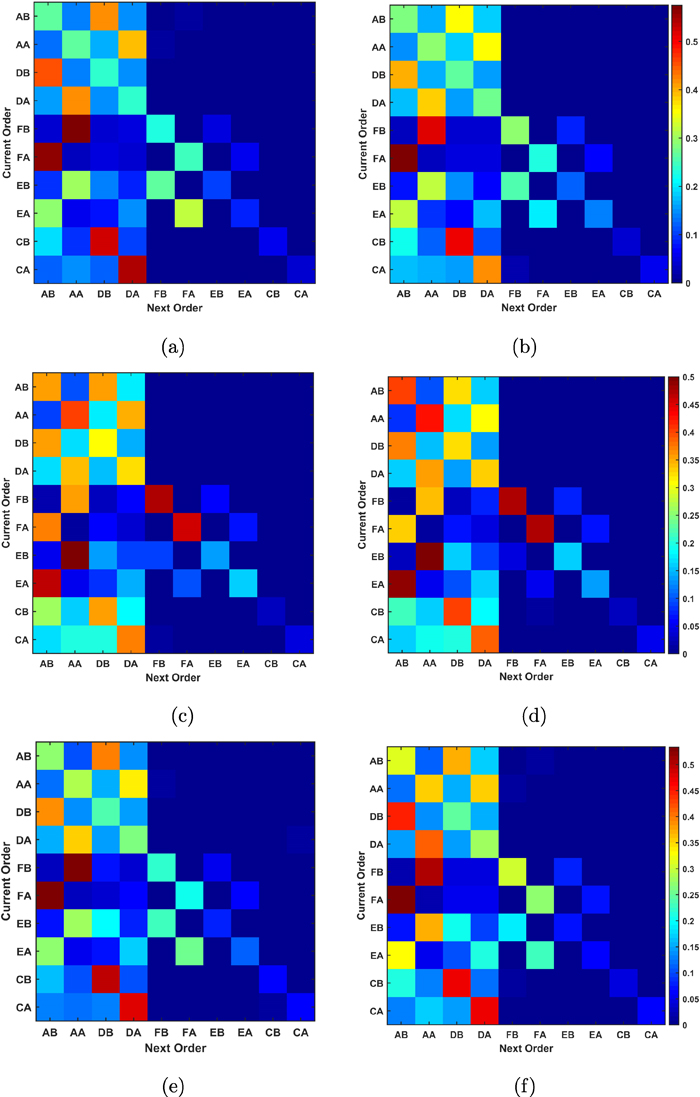
高低波动日的概率转移矩阵(热图)
文章使用一阶离散时间马尔可夫链模型对中美贸易战期间股票高频订单数据进行统计分析,揭示了高波动日中交易者频繁下限价单并大规模删除订单以操控市场,同时发现高低波动期策略在谱间隙和熵率上具有相似性,而金融板块则呈现出持续完整执行订单的模式,显示其较强的市场韧性。
主题:数据处理,社会科学,统计模型,概率论,人类记忆,估计理论,马尔科夫过程,随机过程
地址:https://pubs.aip.org/aip/cha/article/34/1/013118/2933757/High-frequency-stock-market-order-transitions?searchresult=1
编辑:黄继彦
