蚂蚁&人大提出ViLAMP,一种高效处理长视频的视觉语言模型,单卡可处理3小时视频,并在多个基准测试中超越现有方案。ICML 2025接收。
原文标题:ICML 2025 | 长视频理解新SOTA!蚂蚁&人大开源ViLAMP-7B,单卡可处理3小时视频
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 ViLAMP 在 VideoNIAH 任务上表现出色,这个任务的难点在哪里?为什么说它更能体现模型对视频内容深层次的理解能力?
3、ViLAMP 模型在实际应用中,比如在线教育、视频监控、直播分析等领域,可能会遇到哪些挑战?有什么可以进一步改进的方向?
原文内容

该工作第一作者为中国人民大学高瓴人工智能学院硕士生程传奇,目前于蚂蚁技术研究院实习,其主要研究领域为多模态大模型,蚂蚁技术研究院副研究员关健为共同第一作者。
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。当面对影视级的长视频内容时,传统解决方案的不足愈加凸显:粗放式的帧采样策略往往造成关键帧信息遗漏,而特征融合方法虽能降低数据维度,却不可避免地导致语义完整性受损。
近日,蚂蚁和人大的研究团队带来了一个创新性的解决方案。他们提出视觉语言大模型 ViLAMP(Video-Language Model with Mixed Precision),实现了对超长视频的高效处理。这个方法的核心在于其独特的 “混合精度” 策略:对视频中的关键内容保持高精度分析,而对次要内容进行强力压缩,就像人类在观看视频时会重点关注关键场景,而对过渡时空信息只做快速扫描一样。

-
论文标题:Scaling Video-Language Models to 10K Frames via Hierarchical Differential Distillation
-
论文地址:https://arxiv.org/abs/2504.02438
-
Github:https://github.com/steven-ccq/ViLAMP
实验结果令人振奋:ViLAMP 在 Video-MME 等五个主流视频理解基准上全面超越现有方案,特别是在处理长视频时展现出显著优势。更重要的是,它可以在单张 A100 GPU 上连续处理长达 1 万帧(按每秒 1 帧计算约 3 小时)的视频内容,同时保持稳定的理解准确率。这一突破不仅大大提升了视频处理效率,更为在线教育、视频监控、直播分析等实际应用场景带来了新的可能。相关论文已被 ICML 2025 接收。

横轴:处理的视频帧数(从 0 到 10,000 帧),纵轴: GPU 内存使用量(MB)。测试在单块 NVIDIA A100 GPU 上进行。

VideoNIAH(视频版本大海捞针任务)测试结果。横轴:视频总长度(2K-10K 帧);纵轴:表示目标视频在完整视频中的相对位置(0% 表示在开头,100% 表示在结尾)。
视频信息在时空维度均呈现稀疏性与冗余性
为解决长视频处理的效率问题,研究团队首先对主流视觉语言模型(包括 LLaVA-OneVision、LLaVA-Video、Qwen2-VL 和 LongVA)进行了系统性分析,发现了视频信息在时间和空间上均存在显著的稀疏性和冗余性:
-
帧间注意力分析:在现有模型中,用户 Query 对相应视频的注意力高度集中 ——90% 的注意力仅分布在不到 5% 的视频帧上(称为关键帧)。更重要的是,这 5% 的关键帧之间往往存在很强的视觉相似度。
-
帧内注意力分析:在每一帧的内部,模型的注意力也展现出相似的稀疏性质 ——50% 的 patch(帧划分的最小单位)就承载了 80% 的模型注意力,但这些受关注的 patch 与关键帧中的对应 patch 具有远超随机基线水平的相似度。
这一发现表明现有模型在处理视频时存在大量计算资源的浪费。实际上,处理长视频不需要对每一帧、每个 patch 都投入同样的计算量。基于此,研究团队提出 “差分蒸馏原则”(Differential Distill Principle):识别并保留重要的视频信息,同时压缩那些虽然相关但高度冗余的信息。其中,重要信息应该同时满足两个条件:(1)高查询相关性:与当前用户 Query 高度相关;(2)低信息冗余性:包含独特的视频信息。这一原则为后续设计高效的视频处理算法奠定了理论基础。
ViLAMP: 基于差分蒸馏的双层混合精度架构
前文的注意力分析揭示了一个关键问题:现有视觉语言模型对视频中所有帧和 patch 都采用相同的处理方式,导致大量计算资源的浪费。基于这一认识,研究团队提出了专门面向长视频处理的高效架构 ViLAMP,它能够根据信息的重要程度自适应地分配计算资源。

ViLAMP 模型结构图
ViLAMP 通过层次化的压缩框架实现这一策略:在帧级别,对重要的关键帧保留完整的视觉 token 表示,以捕获关键信息;而对于非关键帧,则采用强力压缩策略;在 patch 级别,通过差分机制增大重要 patch 的权重。
模型具体包含两个核心机制:
1. 差分关键帧选择(Differential Keyframe Selection,DKS)
为实现关键帧的高效识别,ViLAMP 采用了基于贪心策略的选择算法。该算法在最大化与用户 Query 的相关性的同时,通过差分机制降低帧间冗余,确保选中的关键帧既重要又多样化。
2. 差分特征合并(Differential Feature Merging,DFM)
针对非关键帧的处理,ViLAMP 创新性地通过差分加权池化,将每个非关键帧压缩为单个信息量最大化的 token。在压缩过程中,模型赋予那些与用户 Query 相关且具有独特性的 patch 较高的权重,同时降低与相邻的关键帧有显著重复的 patch 的权重,从而在大幅降低计算量的同时保留关键信息。
这种双层混合精度架构既确保了模型能够准确捕获视频中的关键信息,又显著降低了计算开销。
突破性性能:全面超越现有方案
在五个主流视频理解基准上的实验表明:
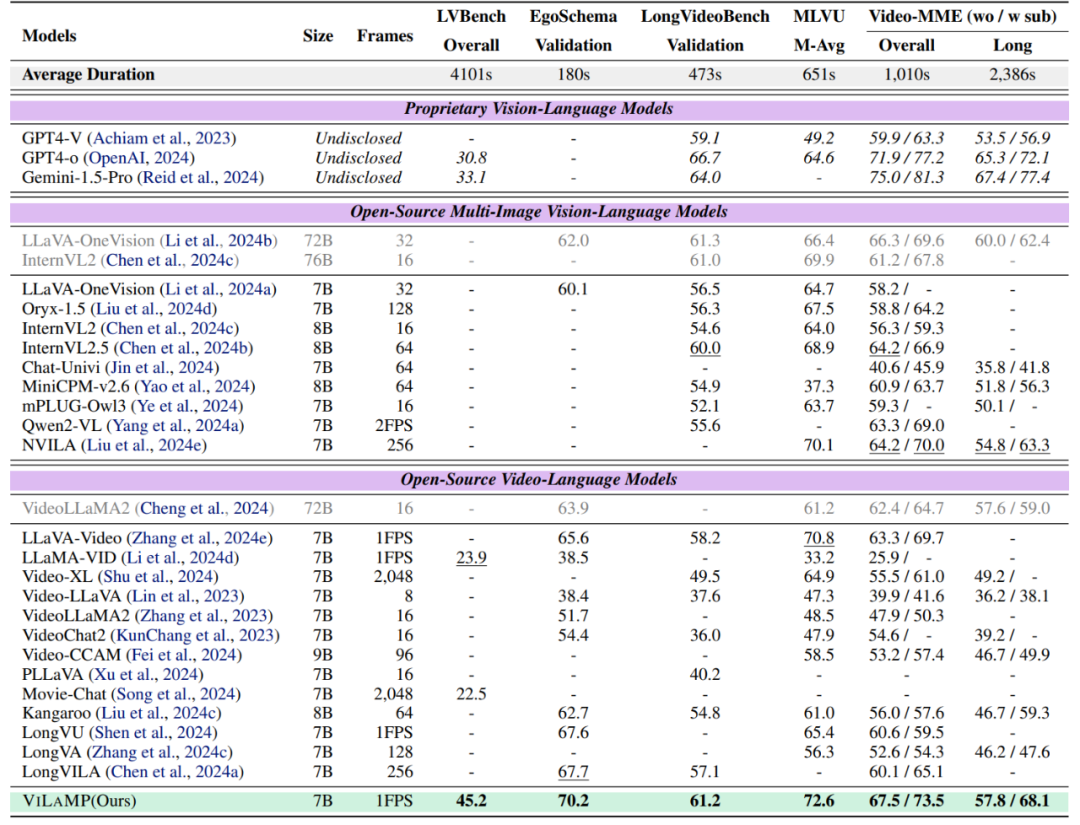
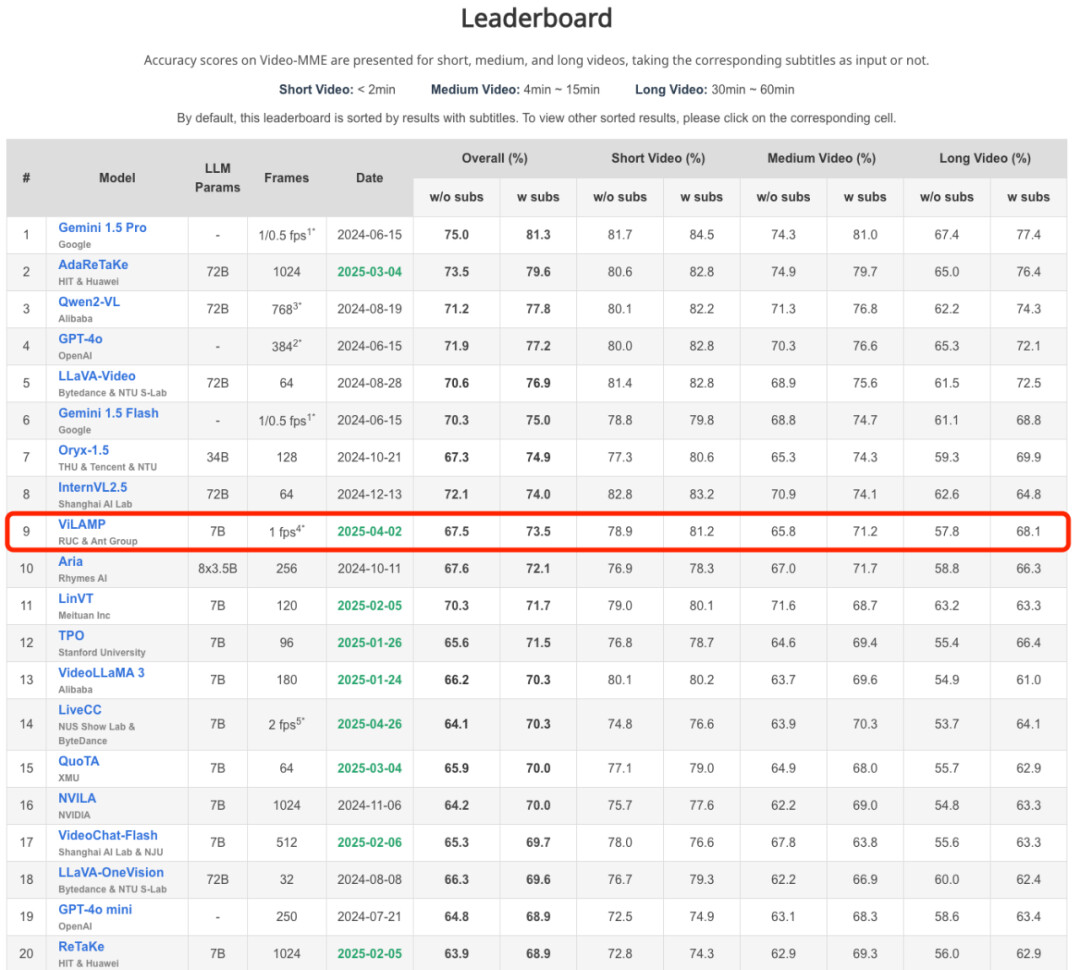
1.ViLAMP 以 7B 参数量达到或超越了部分 70B 量级模型的表现,特别是在 Video-MME 长视频子集上比现有最优模型提升 4.8%。
2. 针对当前视频理解基准中视频长度不足的问题,本文提出了面向视频理解场景的 “大海捞针” 任务 ——VideoNIAH。该任务将一段目标短视频(1 分钟以内)插入到小时级别的长视频中,要求模型在不依赖先验信息的情况下,从超长视频上下文中定位并理解该片段,进而回答相关问题。与传统基于文本的 NIAH 任务不同,VideoNIAH 中的答案无法直接从视频对应的文本描述中提取。因此,该任务本质上更具挑战性,难以达到语言模型在文本 NIAH 任务中所表现出的近乎完美的准确率(例如 99%)。VideoNIAH 任务的性能上限受限于模型对目标短视频原始 QA 的理解水平,进一步凸显了该任务对视频内容深层次理解能力的严格要求。在这一新提出的超长视频理解基准上,ViLAMP 在处理包含 10K 帧(约 3 小时)的视频时仍能保持 58.15% 的准确率(原始 QA 数据集准确率 78.9%),超越 VideoChat-Flash 基线模型 12.82%,展现出较强的长视频建模能力。
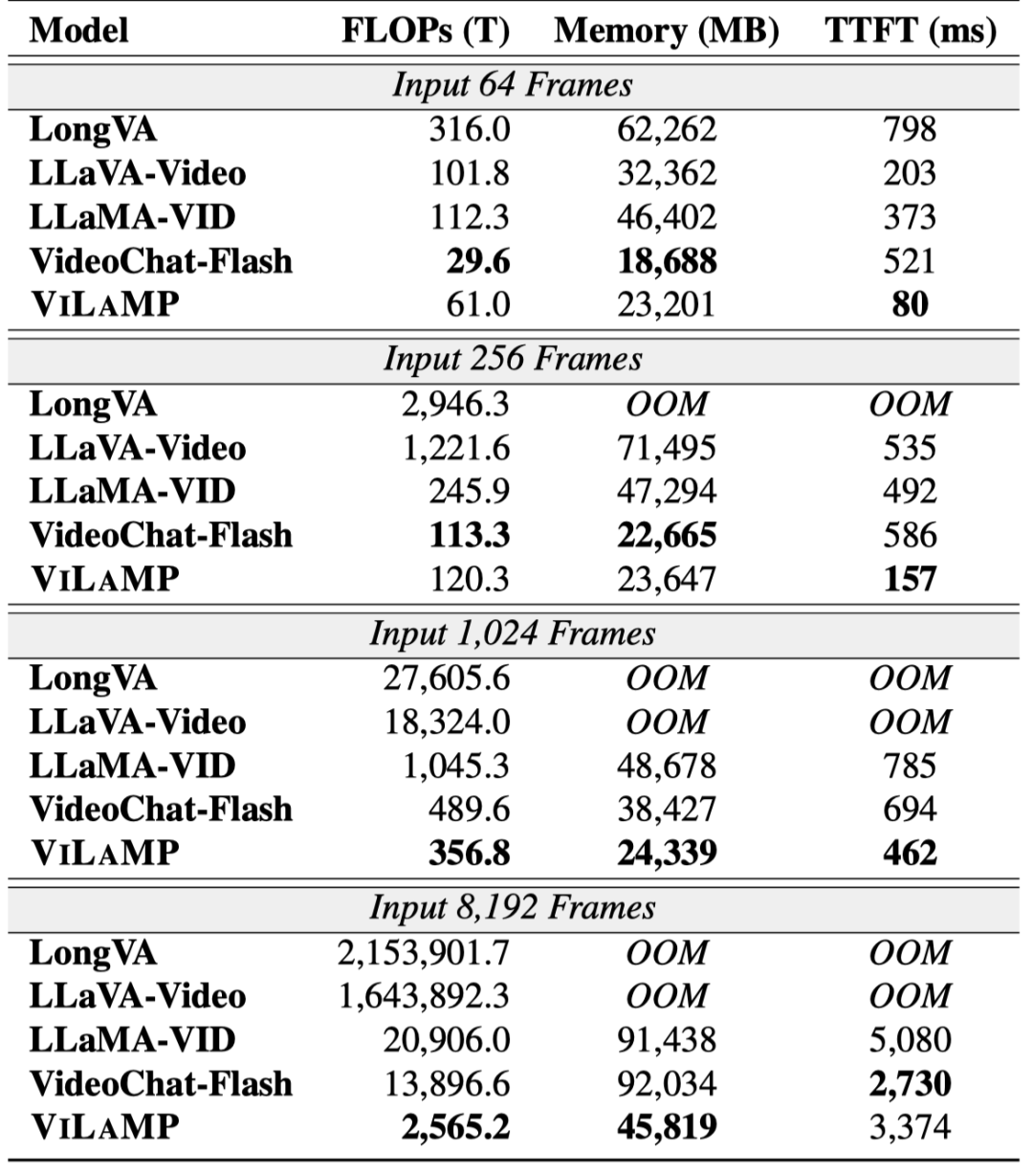
3. 计算效率显著提升:内存消耗相比 LLaMA-VID 基线降低约 50%,在 8,192 帧情况下计算量减少 80% 以上。
4. 深入的消融实验表明:与已有的关键帧选择方案相比,DKS 在长视频场景下表现出明显优势;与 Q-former 和平均池化等特征融合方案相比,DFM 在所有数据集上都展现出 3 个百分点以上的性能优势。
模型表现
Video-MME 排行榜
计算效率对比
结语
ViLAMP 通过创新的差分蒸馏框架成功突破了长视频处理的计算瓶颈,不仅在性能上实现了飞跃,更为视频理解领域提供了新的研究思路。该工作的原理性贡献和实用价值将推动视频理解技术在更多实际场景中的落地应用。期待未来看到更多基于此框架的创新发展。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com