中科院提出MCA-Ctrl,一种无需微调的图像定制化方法,通过多方协同注意力控制,实现AIGC时代图像的精准定制,有效解决复杂视觉场景中的特征混淆问题。
原文标题:CVPR2025|MCA-Ctrl:多方协同注意力控制助力AIGC时代图像精准定制化
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到MCA-Ctrl在主题替换任务上表现优异,但在主题生成任务上与DreamBooth等方法相比略有逊色,经过参数优化后才达到相当水平。这说明了什么?参数优化对MCA-Ctrl这类模型有多重要?
3、MCA-Ctrl是一种无需微调的方法,这在实际应用中有哪些优势?与需要大量训练数据的模型相比,MCA-Ctrl在成本和效率方面有哪些考量?
原文内容

本文由中国科学院计算技术研究所研究团队完成,第一作者为硕士生杨晗,通讯作者为副研究员安竹林,助理研究员杨传广。

-
论文标题:Multi-party Collaborative Attention Control for Image Customization
-
论文地址:https://arxiv.org/abs/2505.01428
-
论文代码:https://github.com/yanghan-yh/MCA-Ctrl
背景
近年来,生成式人工智能(Generative AI)技术的突破性进展,特别是文本到图像 T2I 生成模型的快速发展,已经使 AI 系统能够根据用户输入的文本提示(prompt)生成高度逼真的图像。从早期的 DALL・E 到 Stable Diffusion、Midjourney 等模型,这一领域的技术迭代呈现出加速发展的态势。
在基础 T2I 模型能力不断提升的背景下,图像定制化(Image Customization)需求日益凸显。所谓图像定制化,是指在对参考图像中的主体(subject)保持身份特征和本质属性的前提下,根据文本或视觉条件生成该主体的新表现形式。这一技术对于电子商务(如虚拟试衣)、数字内容创作(如个性化角色设计)、广告营销等应用场景具有重要价值。
当前,主流的图像定制化方法主要沿着三个技术路线发展:基于反演优化(inversion-based)的方法、基于多模态编码器(multimodal encoder-based)的方法,以及新兴的基于注意力控制(attention control-based)的方法。
尽管这些方法在特定场景下都取得了一定成效,但通过系统的实验评估和实际应用验证,我们发现现有技术方案仍然面临着若干关键性技术瓶颈。
1. 可控性不足:主流文本驱动方法难以精确控制背景、布局等元素。虽然 PhotoSwap 等新技术尝试引入图像条件,但仍局限于单一功能(替换或添加),无法实现统一控制。
2. 复杂视觉场景处理困难:面对多物体交互、遮挡等复杂场景时,常出现主体特征扩散问题,这源于模型在高响应区域生成的不准确性。
3. 背景融合不自然:在图像条件控制下,生成结果与原始背景的融合往往不自然。
方法
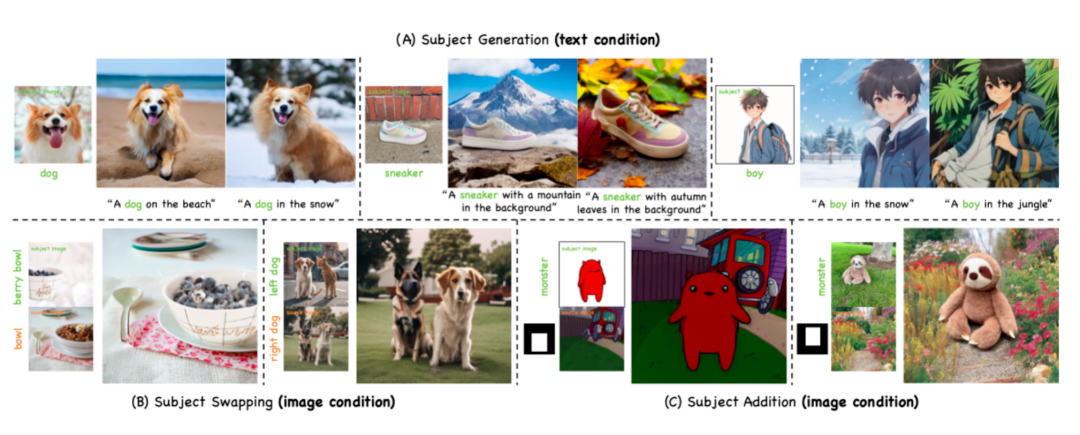
本文提出了一种无需微调的通用图像定制方法 — 多主体协同注意力控制 MCA-Ctrl,该方法利用扩散模型内部知识实现图像定制。其核心创新在于将条件图像 / 文本提示的语义信息与主体图像内容相结合,实现对特定主体的新颖呈现。MCA-Ctrl 主要针对三类任务:主题替换、主题生成和主题添加。
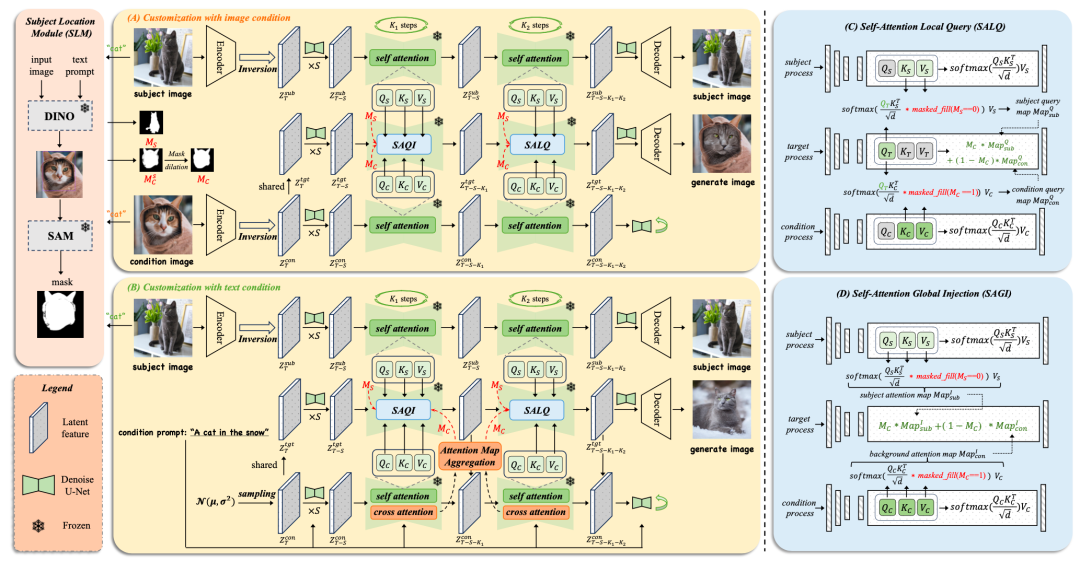
本方法分为通过条件图像和条件文本进行图像定制化,如下图(A)和(B)所示。具体而言,本方法首先引入主体定位模块(Subject Location Module,SLM)对图像进行精准定位,然后通过三个并行扩散过程中的自注意力注入与查询机制,在保持条件信息语义空间布局的同时捕获特定主体的视觉特征表示。
具体来说,MCA-Ctrl 在每个扩散步骤中,系统执行以下关键操作:
1)通过自注意力局部查询(Self-Attention Local Query,SALQ)目标过程从主体和条件信息中检索外观与背景内容,如图(C);
2)通过自注意力全局注入(Self-Attention Global Injection,SAGI)将主体和条件信息的注意力图直接注入目标过程,如图(D)。
1. 自注意力局部查询
从任务视角看,我们的目标是从主体图像提取外观特征,并从条件中查询背景内容与语义布局。受 MasaCtrl 启发,我们利用自注意力层的键值特征表征图像内容。如上图(C)所示,目标过程通过查询特征 Q 从主体和条件中检索前景 / 背景内容,并使用主题、背景掩码约束查询区域。这种设计既能确保布局一致性,又能实现特定对象的外观替换与背景对齐。
2. 自注意力全局注入
经过 SALQ 操作后,生成图像常存在两个问题:(1)细节真实性不足,和(2)特征轻微混淆。我们认为这是由于查询过程本质上是原始特征与查询特征的局部融合,难免导致特征交叉。为此,我们提出全局注意力混合注入机制来增强细节真实性与内容一致性。如上图(D)所示,首先计算条件与主体图像的完整注意力矩阵,再通过掩码过滤获得主体特征和背景特征,最后将其注入目标扩散过程。这种重构式特征替换直接增强了前景 / 背景细节表现,同时有效降低了特征混淆。
实验
下图展示了 MCA-Ctrl 的编辑和生成能力。前三行主要展示了主体编辑性能,包括主体替换、主体添加以及复杂视觉场景中的主体替换,充分证明了 MCA-Ctrl 在主体与背景定制方面的高度一致性和真实感表现。第四行重点呈现了 MCA-Ctrl 的零样本定制生成能力,在物体、动物和人物等不同类别上均能实现高质量、高一致性且富有创意的再现效果。

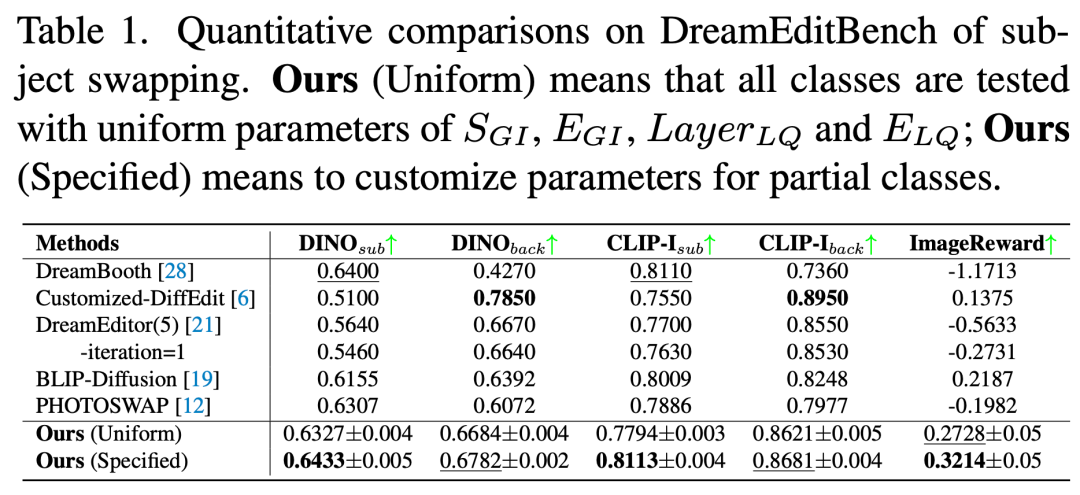
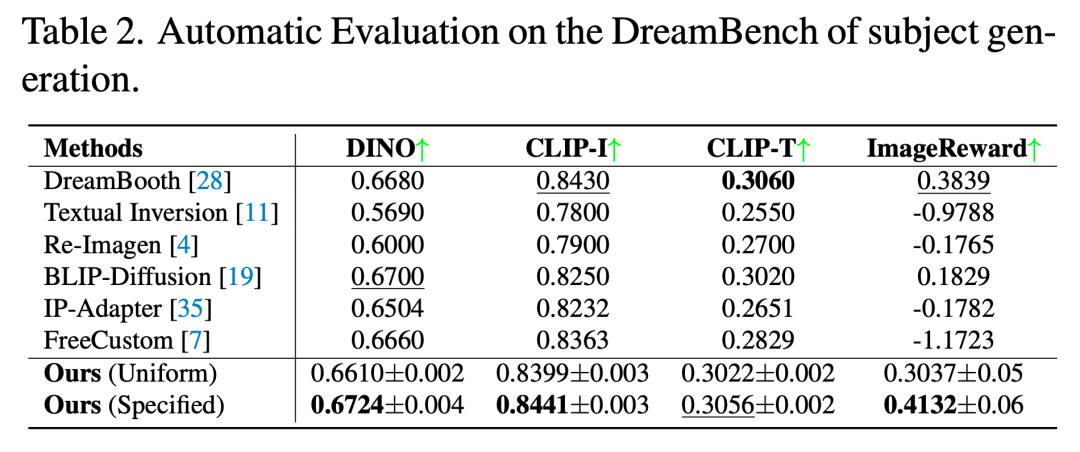
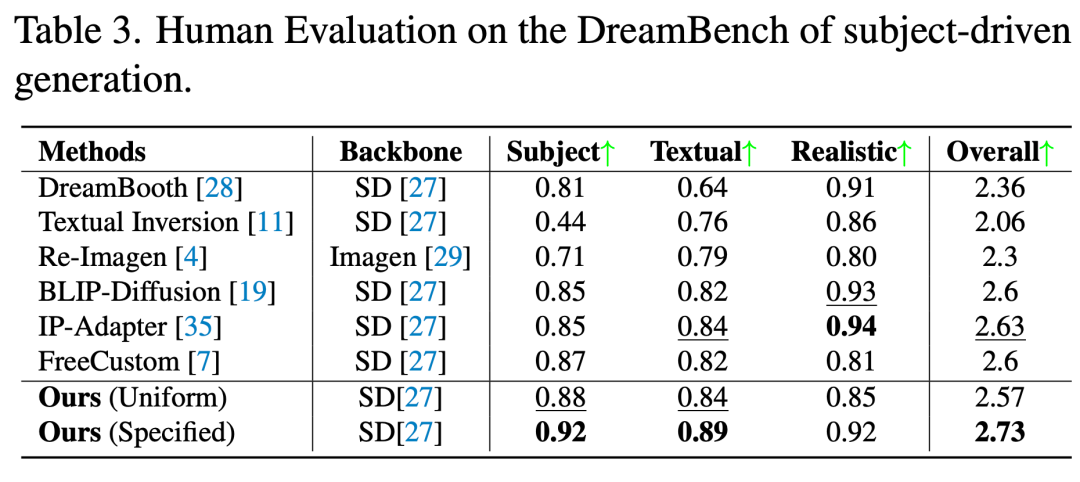
表 1 展示了基于 DreamEditBench 的主题替换任务量化评估结果。相较于 BLIP-Diffusion、DreamBooth 和 PHOTOSWAP 等方法,MCA-Ctrl 在各项指标上均展现出相当或更优的性能表现。表 2 呈现了 DreamBench 上主题生成任务的评估结果。统一参数测试时,MCA-Ctrl 表现优于 Text Inversion、Re-Imagen 和 IP-Adapter,但略逊于 DreamBooth 和 BLIP-Diffusion。经过参数优化后,MCA-Ctrl 取得了与 BLIP-Diffusion 和 DreamBooth 相当的结果。此外,表 3 的人工评估结果表明,MCA-Ctrl 在主体对齐度和文本对齐度方面均表现突出。
我们在下图中展示了对图像生成的影响。实验表明,在复杂场景下,若完全省略 SAGI 操作,会导致目标定位失败和全局特征混淆等问题。随着的逐步增加,主体特征会呈现越来越清晰的表现。但值得注意的是,当超过总去噪步骤的 60%(此为大多数案例的经验阈值)后,继续增加 SAGI 执行步数对图像质量的提升效果将趋于饱和。具体而言,这一现象揭示了两个重要发现:(1)在去噪过程的前期阶段,SAGI 能有效建立主体与背景的语义关联;(2)在去噪后期,过度的全局特征注入反而可能破坏已形成的细节特征。这种 “边际效应递减” 特性为算法参数优化提供了重要指导。

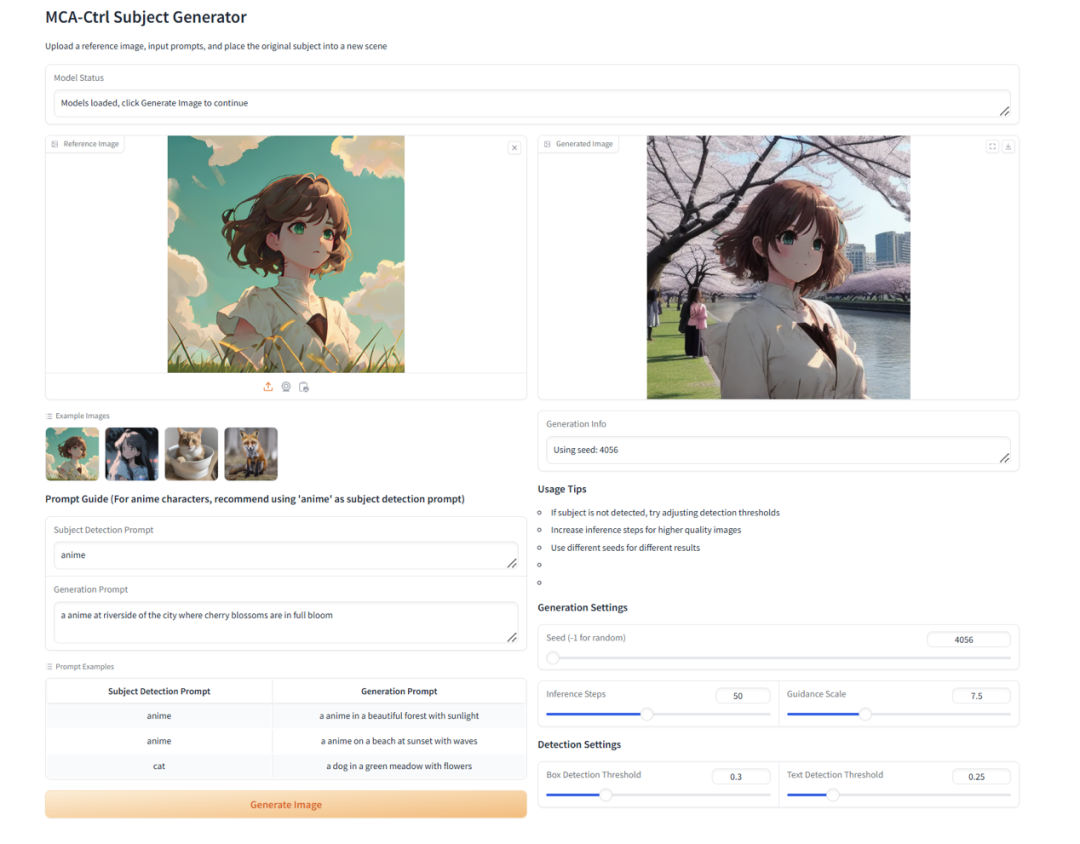
我们也在代码仓库中构建了图像定制化的演示系统,如下所示,用户可以方便地根据自身的需求使用本文提出的方法完成图像定制化任务。
总结
综上所述,该文章提出了一种无需训练的图像定制化生成方法 ——MCA-Ctrl。该模型通过三个并行扩散过程间的协同注意力控制,实现了高质量、高保真度的主体驱动编辑与生成。此外,MCA-Ctrl 通过引入主题定位模块,有效解决了复杂视觉场景中的特征混淆问题。大量实验结果表明,相较于大多数同期工作,MCA-Ctrl 在编辑和生成任务上表现更优。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com