《百面大模型》不仅是面试题集,更是一次知识体系重建。一线面试官编写,覆盖95%高频考点,助你突破大模型技术瓶颈。
原文标题:他说大模型面试全靠玄学,结果我看到他桌上这本书都快被翻烂了!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、书中提到了FlashAttention和PagedAttention等提效技术,这些技术对大模型推理速度的提升有多大帮助?在哪些场景下效果更明显?
3、书中提到了RAG(Retrieval-Augmented Generation),你认为RAG在哪些场景下最有价值?它有哪些局限性?如何克服这些局限性?
原文内容
-
面试官一张口就是“除了 PPO 和 DPO,还有哪些进行偏好对齐的算法?它们各是怎样进行优化的?”。你一脸懵!
-
知道 RLHF 是个大热的术语,但 DPO、GRPO 又是什么鬼?到底怎么答才显得自己不是在背八股文?
-
ChatGPT、DeepSeek、Kimi 天天用,但面试时怎么把“用”变成“懂”?
一本书,攻克整个大模型面试体系


总之,如果你不想再“乱学一气”,也不想面试被问得一脸懵,强烈建议你从读这本书开始!
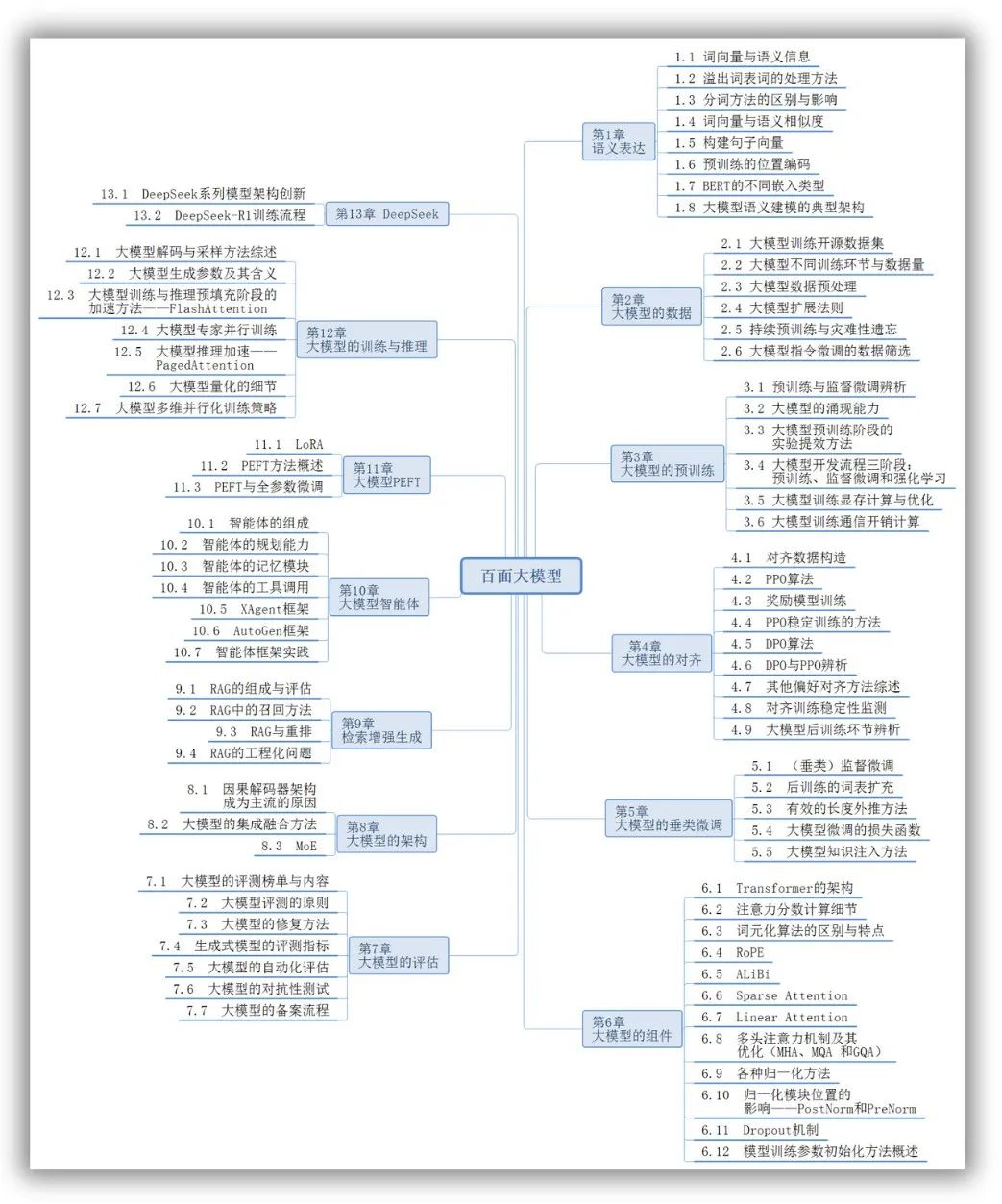
全书共 13 章,覆盖内容包括:
-
从预训练到微调:讲清楚了 MoE、PEFT、SFT、RLHF、DPO、GRPO 背后的方法论和工程实现;
-
从架构到推理优化:系统介绍 FlashAttention、PagedAttention等关键提效技术;
-
从模型评估到对齐技术:分析大模型自动化评估、对抗测试、PPO/DPO 调优;
-
从 RAG 到智能体:涵盖 RAG 的全流程实操、XAgent/AutoGen 框架的原理与场景;
-
从 DeepSeek 案例到国产大模型解析:解读 MLA 架构,分析其如何从“万卡训练”走到推理落地。
为何说它“面试有效”?因为它来自真实面试现场!
书里的这些面试题,基本都是真实的大厂现场题,不是随便拼凑的练习题。作者团队在 2024 年秋招期间,特地选了 3 位硕士实习生,把书中的题目作为训练材料,系统刷完题后去参加头部大厂的面试——结果他们都拿到满意的 Offer!
更厉害的是,书里不少题目和真实面试题几乎一字不差,命中率超高,真的很“对口”。
这套题不是靠“编”出来的,作者本身就是经验丰富的一线面试官,知道哪些知识点会反复被问,也知道面试官到底在考察什么。所以你看到的不是死板的“标准答案”,而是结合出题逻辑、思维方式给出的系统拆解。
这本书更像是一次知识结构的重构过程,不是让你死记硬背,而是让你真正理解“怎么被问、该怎么答”。
相比于死记硬背的对答,这本书做到了三点:
-
“讲原理”:每道题不仅都给出答案,更是从模型、算法、训练流程等角度深入拆解;
-
“讲差异”:DPO vs PPO?LoRA vs PEFT?FlashAttention vs PagedAttention?都给你对比分析;
-
“讲趋势”:大模型领域新兴解决问题的方法或者是对已有方法的演进,背后的动因和选择路径都有详解。
从知识本质出发,不仅仅是面试题
很多人觉得自己“面试经验不足”,但其实这只是表象,背后真正的原因往往是:对底层逻辑的掌握不牢。作者正是意识到了这一点,才决定换一种方式,从知识本质出发,把大模型里那些关键又容易忽略的知识点,转化成一道道清晰的问答题。
这不是简单地刷题,而是通过提问与回答,帮助你一点点把底层打牢。
所以说,这本书不只是一本以面试为导向的习题集,更像是一个系统梳理大模型知识的“小型知识库”。对开发者来说,它提供了一种全新的复习方式,也是一种更本质、更有效的学习路径。
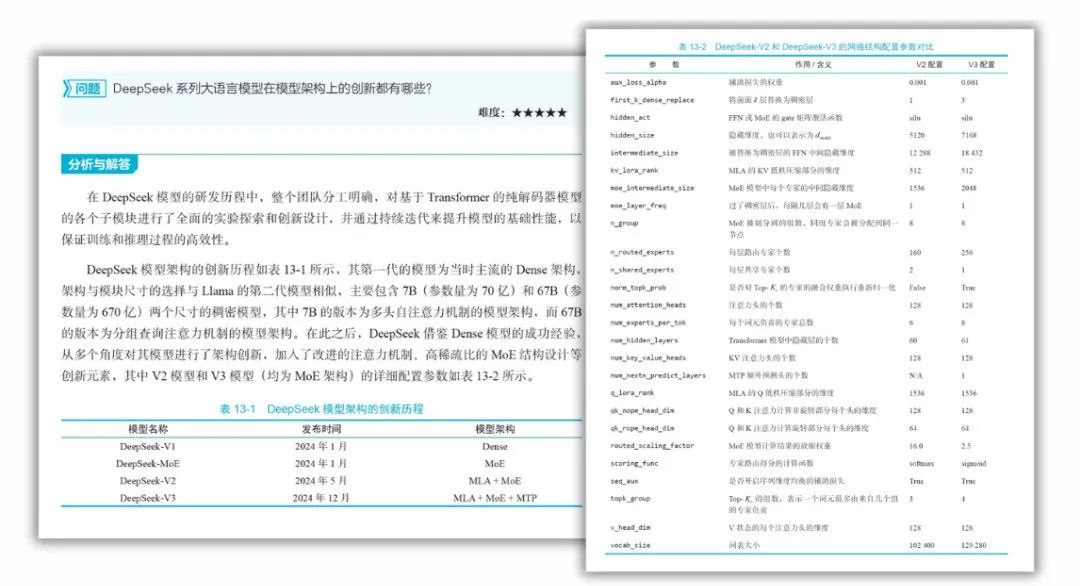
(注:截图仅展示问答过程,该题目还有分析过程,篇幅原因未能一一展示)
如果你是刚上手的初学者,或者已经有一定经验的中高级选手,想更顺利地阅读本书中的代码内容,建议你具备基本的自然语言处理知识,同时也需要掌握一定的 Python 编程基础,最好还有一些 PyTorch 的使用经验。
当然,如果你对其中某些知识点还不熟悉,也不用担心——书中的讲解尽量做到通俗易懂,代码配有详细注释,边读边查边实践,同样能跟得上节奏。
包梦蛟,北京航空航天大学硕士,美团北斗计划高级算法专家,负责大众点评大模型应用落地开发,曾获得 Kaggle Grandmaster 称号、KDD CUP 2024 冠军,业余时间撰写知乎专栏和公众号“包包算法笔记”,全网关注数 5 万+。
刘如日,北京航空航天大学硕士,研究兴趣为机器学习与自然语言处理。曾以第一作者身份发表顶会论文并多次在顶会竞赛中取得冠军等优异成绩。现于美团从事大模型相关技术研究与产业应用。
朱俊达,北京航空航天大学硕士,研究兴趣为大模型架构优化方向,有多家大厂实习经历,发表了多篇大模型相关论文。
