OpenAI科学家预测,随着强化学习扩展,9年后AI可能具备媲美爱因斯坦的科学发现能力,关键在于扩大规模和优化提问方式。
原文标题:9年实现爱因斯坦级AGI?OpenAI科学家Dan Roberts谈强化学习扩展的未来
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 "提问的方式比研究过程和答案更重要",在AI辅助科学发现的过程中,你认为应该如何引导AI提出有价值的问题?
3、文章提到未来AI可能具备8年的思考时间,你认为长时间的思考对于AI进行科学发现有多重要?是否存在“思考时间越长,发现越多”的线性关系?
原文内容
编辑:陈萍、Panda
近日,在红杉资本主办的 AI Ascent 上,OpenAI 研究科学家 Dan Roberts 做了主题为「接下来的未来 / 扩展强化学习」的演讲,其上传到 YouTube 的版本更是采用了一个更吸引人的标题:「9 年实现 AGI?OpenAI 的 Dan Roberts 推测将如何模拟爱因斯坦。」

在这场演讲中,Dan Roberts 介绍了预训练和强化学习的 Scaling Law,并预测强化学习将在未来的 AI 模型构建中发挥越来越大的作用,而随着强化学习继续扩展,我们最终将造出有能力发现新科学的模型。
https://www.youtube.com/watch?v=_rjD_2zn2JU
Dan Roberts,Open AI 研究科学家,强化学习科学团队负责人,同时也是 MIT 理论物理中心访问科学家。他还曾与 Sho Yaida 合著了《The Principles of Deep Learning Theory(深度学习理论的原理)》一书,该书有发布在 arXiv 上的免费版本:https://arxiv.org/abs/2106.10165 。他还曾在 Facebook AI 研究中心担任过研究科学家,之后他参与创立了一家为国防、情报和金融服务客户提供协作情报文本挖掘产品的公司 Diffeo—— 该公司后来被 Salesforce 收购,Dan Roberts 也一并加入了 Salesforce。后来,他又加入了红杉资本,成为了一位 AI Fellow。去年,他离开红杉资本,加入了 OpenAI。
机器之心整理了 Dan Roberts 的演讲内容。
正如你们许多人知道的,去年 9 月,OpenAI 发布了一个名为 o1 的模型。
我这里展示的是一张图表,y 轴代表模型在某种数学推理基准测试上的表现,但真正有趣的是 x 轴。
左边的图表显示,随着训练时间的增加,模型性能随之提升。这种走势是每个训练 AI 模型的人都熟悉的。
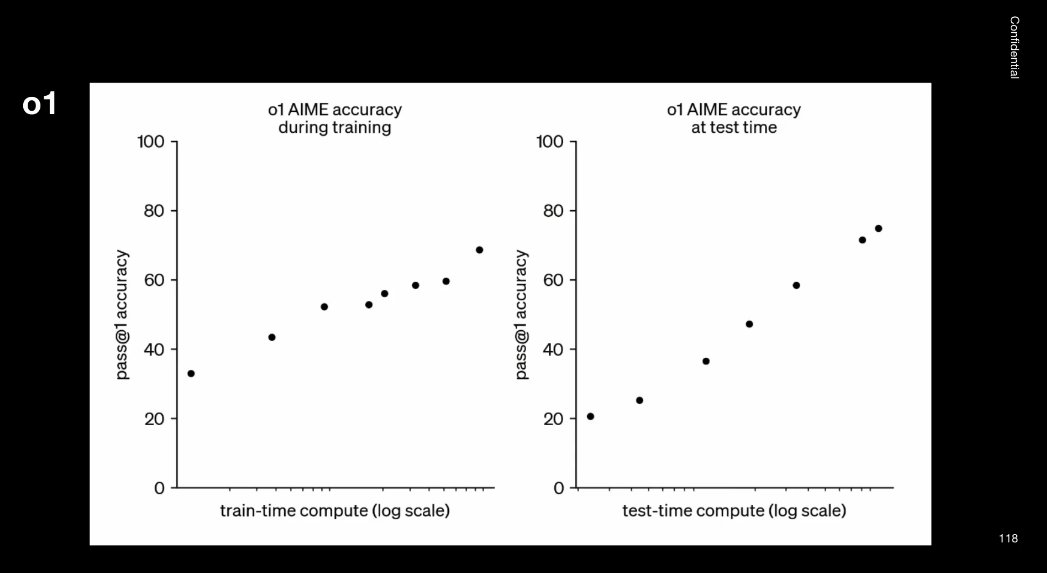
但真正令人兴奋的是右边的图表:它表明在「测试时间」增加时,模型的表现也会得到改善。模型学会了思考,思考的时间越多,进步就越大。
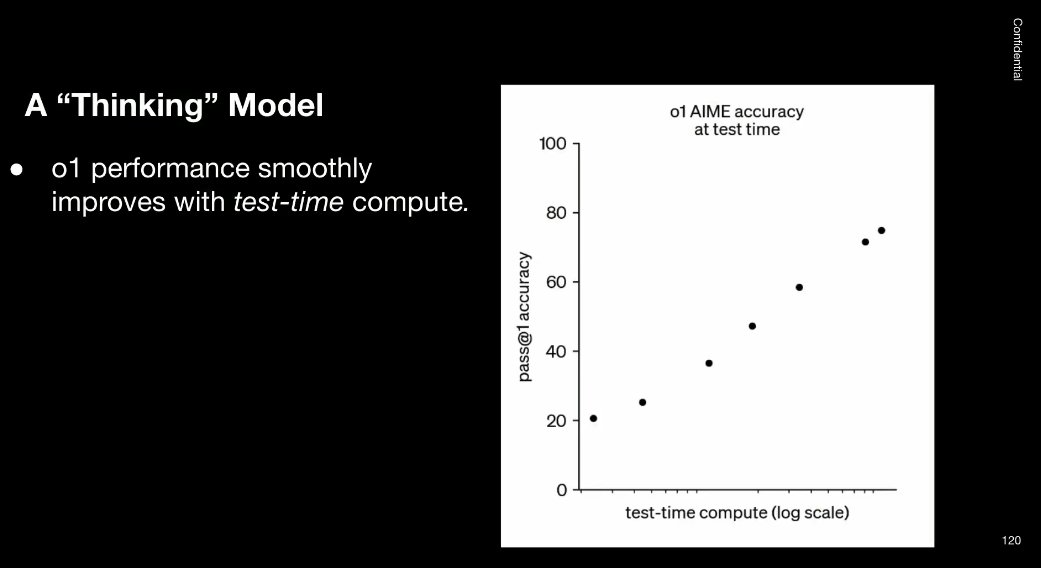
这个发现太重要了,我们甚至把它印在了 T 恤上。因为这代表了一个全新的扩展维度 —— 不仅仅是训练时间扩展,还包括测试时间扩展。

这种发现意味着什么呢?意味着我们有了一个会思考的模型。
上个月,我们发布了一个更强大的推理模型 o3,比如图中展示的一张草稿图,你可以提问「Solve the QED problem on the left(解决左边的量子电动力学问题)」。

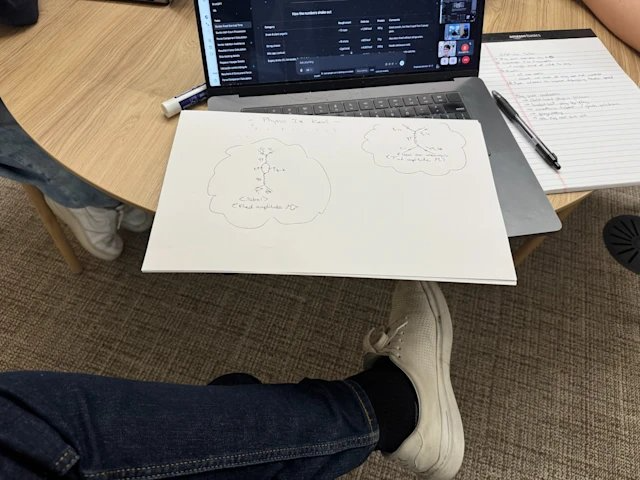
这类模型在测试时,能进行思考,分析图像,并放大图像细节(过程如下)。

其实这张纸上有个费曼图(一种用于表示量子场论计算的图示),模型经过分析后,最终给出正确答案 —— 整个过程大约花了一分钟。

顺便提个趣事:在发布这篇博客前,一位同事让我验证这个计算。尽管这是教科书级别的题目,但我花了 3 个小时才搞定 —— 我得一步步追踪它的推导,确保所有正负号都正确,最后才能确认答案是对的。
那么,我们现在能做什么?模型思考一分钟,就能完成一些相当复杂的计算 —— 但我们的目标远不止于此。
不如做个思维实验吧!说到思维实验,谁最擅长?阿尔伯特・爱因斯坦。
让我们以爱因斯坦为对象做个假设:如果回到 1907 年(他刚开始研究广义相对论之前),让他回答一道广义相对论的期末考题 —— 这题目其实是 GPT-4.5 编的,但我可以保证,这确实是你会遇到的那种典型问题。
我们设想爱因斯坦在 1907 年被问到以下问题:问题 1:黑洞与施瓦西度规。

当然,作为 OpenAI,我们不会直接问爱因斯坦,而是问「爱因斯坦 v1907-super-hacks」。
我认为爱因斯坦是个视觉型思考者。他总爱用电梯和自由落体来举例 —— 学广义相对论时肯定会碰到这些概念,还有那些橡胶膜上的小球的比喻。不过看起来他中途走神去琢磨量子力学了……(我们的模型也经常这样分心!)。

看起来「爱因斯坦 v1907-super-hacks」的思考逐渐接近黑洞的概念了…… 不过我也不知道为什么他会把自己代入到这些场景里。但答案是正确的。
但事实证明,GPT-4.5 没能答对这道题,我们得靠 o3 才能解决。
我在 OpenAI 的工作大概就是专门验证这些物理计算,而不是搞 AI 研究。
不过重点在于:模型给出了正确答案,而爱因斯坦当然也能答对 —— 只是他花了 8 年时间。
目前,我们的模型已经可以通过一分钟的思考重现教科书级别的计算及其衍生问题。但我们的目标远不止于此 —— 我们希望它们能为人类知识与科学的前沿做出重大贡献。

我们在回到这张图表(左边),如何才能实现这一目标?通过图表可以看出,模型的性能会随着训练量的增加而提升,而我们的训练方法主要是强化学习(Reinforcement Learning, RL)。

这次演讲我最想传达的核心信息是:我们需要持续扩大强化学习的规模。一年前,我们发布了 GPT-4o,当时所有的计算资源都投入在预训练(pre-training)上。

但随后,我们开始探索新方向,这才有了如今测试阶段的「思考」能力 —— 比如在 o1 模型 中,我们额外增加了强化学习计算量(RL compute)。

当然,这只是一个卡通演示,比例不一定对,但其方向是对的。o3 用到了一些强化学习,但未来强化学习计算的比重会更大。到某个时候,强化学习计算可能会成为主导。

这是我从 Yann LeCun 的幻灯片借的一张图,大概是他 2019 年的一场演讲。这张幻灯片有点复杂,难以理解。其中关键在于:预训练就像这个大蛋糕,强化学习应该像上面的小樱桃。我们实际上要做的是颠覆这个迷因。我们的蛋糕大小可能不会变化,但我们可能会有一颗超大的强化学习樱桃。

那么,我们计划怎么做呢?但我不能泄漏我们的计划。我一开始担心我的幻灯片会被删减一些,但一切都还好。

我们的计划其实很明显:大规模扩展计算。

什么意思呢?我们将筹集 5000 亿美元,在德克萨斯州的阿比林买一些地,建一些建筑,在里面放一些计算机。我们也将训练一些模型,然后希望能借此获得大量收入,然后我们会建更多建筑并在里面放更多计算机。这就是我们扩展计算的方式。与此同时,我们也将发展 scaling 科学,这就是我在 OpenAI 所做的事情。
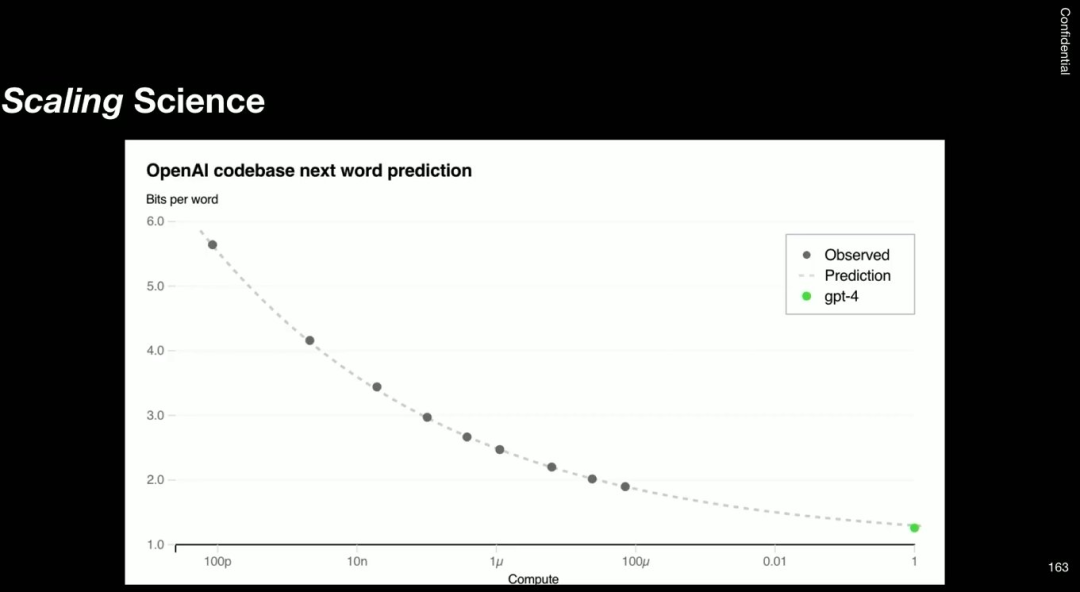
这张图来自介绍 GPT-4 的博客文章,那时候我还没有加入 OpenAI,但这张图确实振奋人心。下面的绿点是 GPT-4 的最终损失性能,前面的灰点是训练过程中记录的性能。而这张图采用了对数尺度。
将这些点连起来,可以得到一条趋势线,我们可以借此预测未来:训练前所未有的大模型确实能带来好处。
现在我们有了测试时间计算和强化学习训练的新方向。我们是否必须抛弃一切,重新发明应用于扩展计算的含义?所以我们需要扩展科学。

这张图来自播客主理人 Dwarkesh。他问,既然现在 LLM 已经记住了如此多的知识,为什么还没有做出什么科学发现呢?
原因可能是我们提问的方式不正确。在研究中,很多时候提问的方式比研究过程和答案更重要。所以关键在于问对问题。
还有一个可能原因是,我们现在过于关注竞赛数学等问题了,这就导致模型在不同问题上的能力参差不齐。

总之,我认为真正会发生的事情是扩大规模。我们需要进一步扩大规模,这是有用的。
总结一下,这就是接下来会发生的事情。这是去年 AI Ascent 上的一张图,其中 Y 轴是半对数的。可以看到,智能体 / AI 所能处理的任务的长度每 7 个月就会翻一倍。根据这张图,他们可以执行长达一个小时的测试了,但明年呢?大概会在 2 到 3 小时之间。
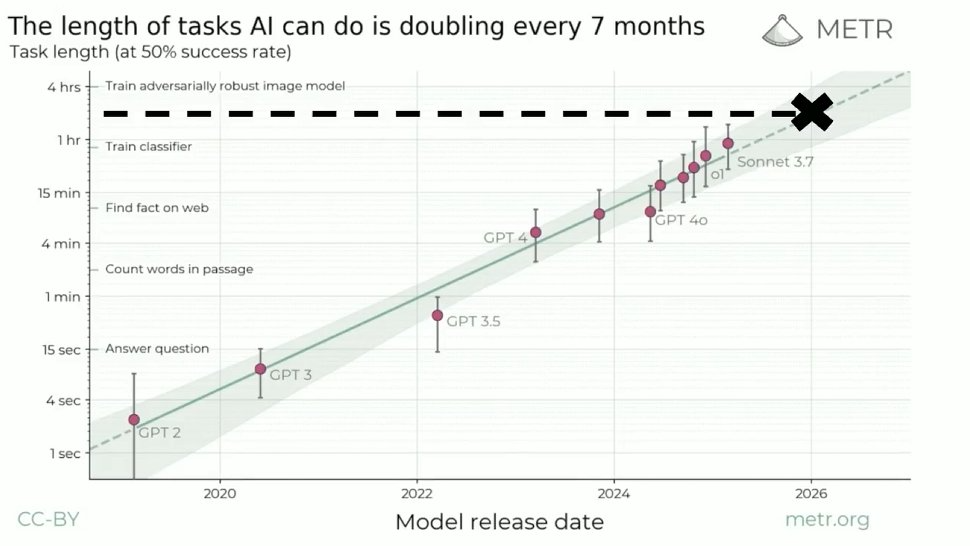
不过,预测 AI 的发展并不容易,大家总是错的。但假如这张图的预测是对的,沿着其趋势,到 2034 年 AI Ascent 时,AI 将有能力进行长达 8 年的计算和思考 —— 而 8 年正是爱因斯坦发现广义相对论所用的时间。
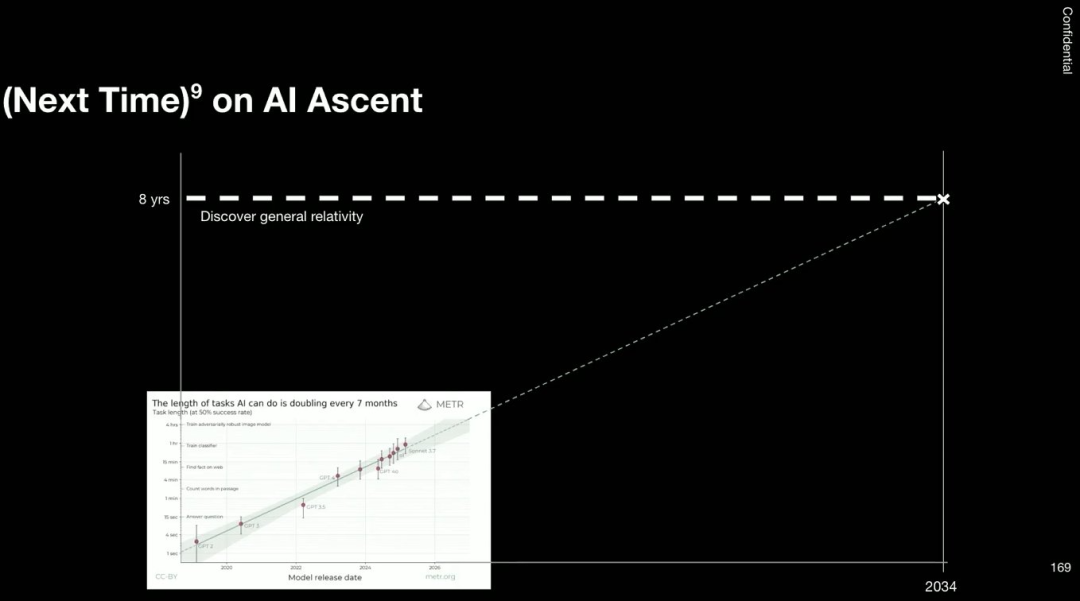
我想,或许 9 年后,我们就将有能发现广义相对论的模型。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com