全球首款AI生成多人游戏Multiverse诞生!由Enigma Labs打造,成本低至1500美元,现已开源。开启AI模拟共享环境新纪元。
原文标题:全球首款AI生成多人游戏诞生,全部开源,单机可玩,成本不到1500美元
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Multiverse 通过将双方玩家的视角拼接成一张图像来解决多人游戏状态同步的问题,这样做有什么优点和缺点?还有没有其他更好的方案?
3、Enigma Labs 开源了 Multiverse 的所有代码、数据和模型,这对 AI 和游戏行业会产生什么影响?你觉得未来 AI 生成游戏会成为主流吗?
原文内容
机器之心编辑部
今天,又一个「世界首创」头衔被认领了。以色列创业团队 Enigma Labs 宣布造出了世上首个 AI 生成的多人游戏 Multiverse,即「多元宇宙」。
很显然,这是一个多人赛车游戏。「玩家可以超车、漂移、加速 —— 然后再次相遇。每一次行动都会为重塑这个世界。」
开发者 Jonathan Jacobi 表示,多人游戏曾是 AI 生成世界中缺失的拼图,而 Multiverse 成功补齐这一空白,而玩家能够实时地与这个 AI 模拟的世界进行交互并塑造它。
更让人吃惊的是,Multiverse 的训练和研发成本加起来还不到 1500 美元,其中包括数据收集、标注、训练、后训练和模型研究。并且,它还可以直接在个人电脑上运行!

Jonathan Jacobi 写到:「多人世界模型远远不止于游戏——它们是模拟的下一步,可解锁由玩家、智能体和机器人塑造的动态的、共同进化的世界。」
不仅如此,该团队也宣布将会开源与该研究成果相关的一切,包括代码、数据、权重、架构和研究。另外,Enigma Labs 也发布了一篇技术博客,介绍了 Multiverse 背后的一些故事和技术。
-
GitHub:https://github.com/EnigmaLabsAI/multiverse
-
Hugging Face:https://huggingface.co/Enigma-AI
-
技术博客:https://enigma-labs.io/blog
团队介绍
该团队来自以色列,成员包括以色列的前 8200 部队成员以及一些领先的创业公司成员,拥有丰富的研究和工程开发经验,涵盖漏洞研究、算法、芯片级研究和系统工程。
他们写到:「我们秉持第一性原理思维,解决了 AI 生成世界中的一项开放性挑战:多人世界模型。」
Multiverse 架构解读

单人游戏架构回顾
要了解多人世界模型的架构,首先回顾一下单人世界模型中使用的现有架构:

该模型接收视频帧序列以及用户的操作(如按键),并利用这些信息根据当前操作预测下一帧。
它主要由三个部分组成:
-
动作嵌入器——将动作转换为嵌入向量;
-
去噪网络——根据前一帧和动作嵌入生成一帧的扩散模型;
-
上采样器(可选)——另一个扩散模型,用于接收世界模型生成的低分辨率帧,并增加输出的细节和分辨率。
多人游戏架构
为了构建多人游戏世界模型,该团队保留了上面的核心构建模块,但对结构进行了拆解 —— 重新对输入和输出进行了连接,并从头开始重新设计了训练流程,以实现真正的合作游戏:
-
动作嵌入器——获取两个玩家的动作,并输出一个代表它们的嵌入;
-
去噪网络——一个扩散网络,它能基于两个玩家之前的帧和动作嵌入,以一个实体的形式同时生成两个玩家的帧;
-
上采样器——此组件与单人游戏组件非常相似。不过这里的上采样器会分别接收两个玩家的帧,并同时计算上采样后的版本。

为了打造多人游戏体验,模型需要收集双方玩家之前的帧和动作,并输出各自预测的帧。关键在于:这两个输出不能仅仅看起来美观——它们需要在内部保持一致。
这是一个真正的挑战,因为多人游戏依赖于共享的世界状态。例如,如果一辆车漂移到另一辆车前面或发生碰撞,双方玩家都应该从各自的视角看到完全相同的事件。
该团队提出了一个解决方案:将双方玩家的视角拼接成一张图像,将他们的输入融合成一个联合动作向量,并将这一切视为一个统一的场景。

于是问题来了:怎样才能最好地将两个玩家视图合并为模型可以处理的单一输入?
-
显而易见的做法是将它们垂直堆叠,就像经典的分屏游戏一样;
-
一个更有趣的选择是沿通道轴堆叠,将两帧图像视为具有两倍色彩通道的图像。

答案是方案 2,即沿通道轴堆叠。因为这里的扩散模型是一个 U 型网络,主要由卷积层和解卷积层组成,所以第一层只处理附近的像素。如果将两个帧垂直堆叠,那么直到中间层才会对帧进行处理。这就降低了模型在帧间产生一致结构的能力。
另一方面,如果将帧按通道轴堆叠,则网络的每一层都会同时处理两名玩家的视图。

车辆运动学和相对运动的高效上下文扩展
为了准确预测下一帧,模型需要接收玩家的动作(如转向输入)和足够的帧数,以计算两辆车相对于道路和彼此的速度。
在研究中,作者发现 8 帧(30 帧/秒)的帧数可以让模型学习车辆运动学,如加速、制动和转向。但两辆车的相对运动速度要比道路慢得多。例如,车辆的行驶速度约为 100 公里/小时,而超车的相对速度约为 5 公里/小时。
为了捕捉这种相对运动,需要将上下文的大小扩大近三倍。但这样做会使模型速度过慢,无法进行实时游戏,增加内存使用量,并使训练速度大大降低。
为了保持上下文大小,但又能提供更多的时间信息,作者为模型提供了前几帧和动作的稀疏采样。具体来说,他们向模型提供最近的 4 个帧。然后在接下来的 4 个帧中每隔 4 个帧提供一次。上下文中最早的一帧为 20 帧,即过去 0.666 秒,足以捕捉到车辆的相对运动。此外,这还能让模型更好地捕捉到与路面相比的速度和加速度,从而使驾驶的动态效果更加出色。

多人游戏训练
为了学习驾驶和多人互动,模型需要对这些互动进行训练。世界模型中的行走、驾驶和其他常见任务需要较小的预测范围,例如 0.25 秒的未来预测。
多人交互则需要更长的时间。在 0.25 秒内,玩家之间的相对运动几乎可以忽略不计。训练多人世界模型需要更长的预测时间。因此,作者对模型进行了训练,以预测未来 15 秒内的自回归预测(30 帧/秒)。
为了让模型能够执行如此长的预测范围,此处采用了课程学习的方法,并在训练过程中将预测范围从 0.25 秒增加到 15 秒。这样,在初始训练阶段,即模型学习汽车和赛道几何等低级特征时,就能进行高效训练。当模型学会生成连贯的帧和车辆运动学建模后,就可以对球员的行为等高级概念进行训练。
在增加预测范围后,模型的目标持久性和帧间一致性都有了显著提高。
高效的长视野训练
训练未来 100 帧以上的模型对 VRAM 提出了挑战。在批尺寸较大的情况下,将帧加载到 GPU 内存中进行自回归预测变得不可行。
为了解决内存不足的问题,作者以页面为单位进行自回归预测。
在训练开始时,加载第一批帧并进行预测。
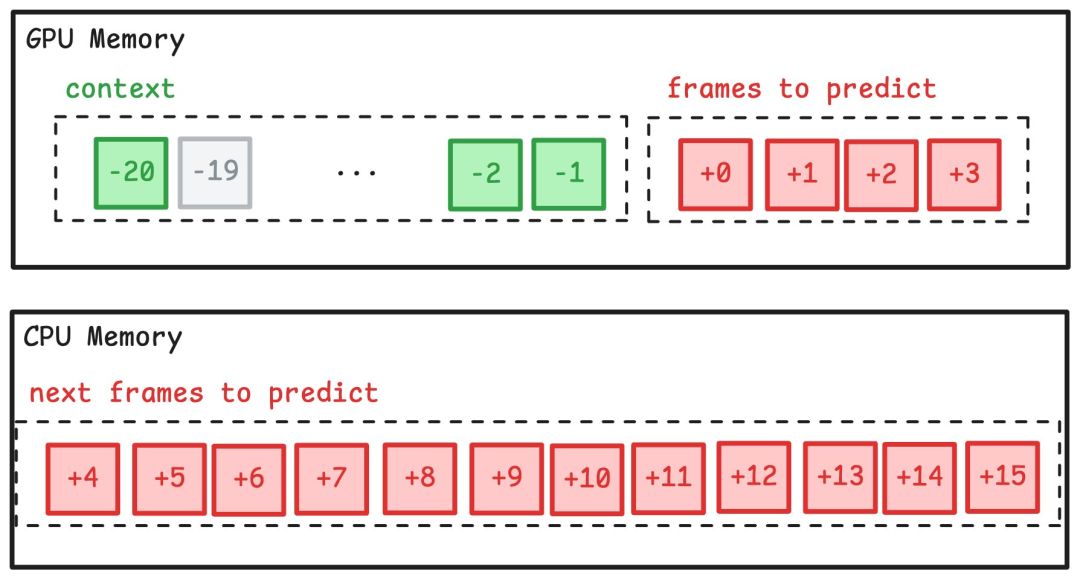
然后加载下一页,并放弃上下文窗口之外的帧。

Gran Turismo 数据集:生成与收集
该团队训练模型的数据收集自索尼的游戏《GT 赛车 4》(Gran Turismo 4)。他们打趣地表示:「这只是一个技术演示,我们是铁粉,所以请不要起诉我们。」
设置和游戏修改
他们使用了较为简单的测试用例:在筑波赛道(Tsukuba Circuit)上的 1v1 比赛,视角是第三人称。筑波赛道比较短,道路也简单,非常适合训练。
但问题也有:《GT 赛车 4》并不支持玩家以 1v1 模式全屏运行筑波赛道。该游戏仅支持 1v5 或分屏对战模式。因此,该团队对游戏进行了逆向工程和修改,从而可以真正的 1v1 模式启动筑波赛道:

数据收集
为了收集双方玩家的第三人称视频数据,该团队利用了游戏内置的回放系统 —— 每场比赛回放两次,并从每位玩家的视角进行录制。然后,该团队将两段录像同步,使其与原始的双人比赛画面一致,并将它们合并成一段两位玩家同时比赛的视频。
那么,该团队采用了什么方法来捕捉数据集中的按键动作,更何况其中一位玩家是游戏机器人而非人类?
幸运的是,该游戏会在屏幕上显示足够多的 HUD 元素(例如油门、刹车和转向指示灯);这些信息可用于准确地重建达到每个状态所需的控制输入:

该团队利用计算机视觉逐帧提取了这些方框中的信息,并解码了其背后的控制输入,进而重建得到了完整的按键操作,从而无需任何直接输入记录即可构建完整的数据集。
自动的数据生成
乍一看,我们似乎不得不坐下来手动玩游戏几个小时,为每场比赛录制两次回放 —— 这就有点痛苦了。
虽然 Multiverse 的部分开源数据集确实来自手动游戏,但作者发现了一种更具可扩展性的方法:B-Spec 模式。在这个模式下,玩家可以使用游戏手柄或方向盘来指示游戏机器人驾驶员代表他们进行比赛。

由于 B-Spec 的控制功能有限且简单,作者编写了一个脚本,向 B-Spec 发送随机输入,自动触发比赛。之后,同一个脚本会从两个视角录制回放画面,从而捕捉这些 AI 驱动比赛的第三人称视频。
作者还尝试使用 OpenPilot 的 Supercombo 模型来控制赛车,本质上是将其变成了游戏中的自动驾驶智能体。虽然这种方法有效,但最终显得多余 —— 因此,最终版本中还是使用 B-Spec 进行数据生成:

多人游戏世界模型不仅仅是游戏领域的一项突破,更是人工智能理解共享环境的下一步方向。通过使智能体能够在同一个世界中学习、响应和共同适应,这些模型开启了新的可能性。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]