华为诺亚提出MoLE,一种新型端侧大模型架构,通过查找表替代矩阵运算,显著降低内存搬运代价,提升推理效率,尤其在批量解码场景中表现出优势。
原文标题:ICML 2025 Spotlight|华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍
原文作者:机器之心
冷月清谈:
怜星夜思:
2、MoLE 架构通过查找表避免了矩阵运算,显著降低了传输开销。那么,查找表本身是否存在优化的空间?例如,查找表的压缩或者索引方式的优化?
3、MoLE 的设计思路是针对端侧部署优化的,那么,这种架构在云端或者数据中心等资源更充足的环境下,是否还有应用价值?
原文内容

Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
现有的主流解决方案是专家卸载(Expert Offloading),即将专家模块存储在下层存储设备(如 CPU 内存甚至磁盘)中,在推理时按需加载激活的专家到显存进行计算。但这一方法存在两大主要缺陷:
-
由于不同 token 通常激活的专家不同,每一步推理都需要频繁加载不同的专家,导致显著的推理延迟;
-
在批量解码场景中,各 token 可能需要不同的专家,在最坏情况下,甚至需要将一整层的所有专家加载到显存中,进一步加剧显存压力并带来额外的推理延迟。
为了解决上述问题,来自北大和华为诺亚的研究人员提出了 Mixture-of-Lookup-Experts(MoLE),一种在推理阶段可重参数化的新型 MoE 架构。

-
论文链接:https://arxiv.org/pdf/2503.15798
-
代码链接:https://github.com/JieShibo/MoLE
思考
本文的核心思考是,在专家卸载方案中,需要将专家模块加载到显存,主要是为了在 GPU 上执行高效的矩阵运算。换句话说,如果专家的计算过程能够绕过矩阵运算的需求,就可以避免将专家权重加载到显存,从而根本上规避频繁加载带来的开销。直观来看,专家模块本质上是一个神经网络,用于建模输入到输出的映射。如果能够在推理前预先计算出所有可能的输入 - 输出对应关系,并将其存储为查找表,那么在推理时即可用简单的查找操作代替矩阵运算。
一般而言,神经网络所建模的映射通常涉及无限多的输入 - 输出对,因此,要实现查找表替代矩阵运算,首先需要确保专家模块的输入来自一个离散且有限的集合,并且这一离散化方法能够适配大规模预训练任务。其次,由于查找操作发生在 GPU 之外,还需要保证检索过程本身不依赖密集计算,避免引入新的性能瓶颈。
基于这一思考,作者注意到,大规模语言模型(LLM)中的 embedding token(即 embedding 层的输出)天然具备离散且有限的特性,其数量与词表大小一致,满足了离散有限要求。并且 embedding token 可以通过 token ID 唯一确定,因此查找表的检索可以采用高效的直接寻址。因此,MoLE 设计中将专家的输入由中间特征改为 embedding token,从而满足了查找表构建的所有要求。
训练阶段
在训练阶段,MoLE 相较于传统的 MoE 架构存在三个主要区别:
-
输入调整:将所有路由专家(routed experts)的输入由上一层的输出,改为浅层的 embedding token,以确保专家模块可以被预计算并存储为查找表。
-
激活策略:由于查找表检索在推理时无需额外计算,MoLE 无需依赖稀疏激活来控制推理计算量,因此在训练中选择激活所有路由专家。
-
损失设计:鉴于不再需要通过稀疏激活实现负载均衡,MoLE 训练时仅使用语言建模损失,不再引入额外的负载均衡损失项。
除此之外,MoLE 的其他设计与标准 MoE 保持一致,包括路由(router)模块和共享专家(shared experts),依然使用上一层的输出作为输入。计算流程如下


推理阶段
在推理前,MoLE 通过预先构建查找表来完成专家模块的重参数化。具体而言,embedding 层的权重矩阵本身即包含了所有 embedding token 的向量表示,因此可以直接以该权重矩阵作为专家模块的输入,并通过各个路由专家分别计算对应的输出。这样,便可以高效地获得完整的 token id 到专家输出的映射集合,用于后续的查找操作。具体过程如下所示:


在查找表构建完成后,所有原始的路由专家模块将被删除,查找表则被存储在下层存储设备中。在推理阶段,对于每个 token,根据其 token ID 直接在查找表中检索对应的专家输出,并将检索到的输出加载到显存中,用于后续的推理计算。整体计算流程如下所示:

复杂度分析
如表所示,在推理阶段,MoLE 的计算过程中仅保留了共享专家模块,因此只有共享专家被激活并参与计算,其整体计算量与具有相同激活参数量的 Dense 模型和传统 MoE 模型相当。相比之下,MoLE 在推理时仅需传输专家输出的结果向量,而传统 MoE 需要传输中间维度 D_r 的专家权重矩阵,因此 MoLE 的传输开销相比 MoE 减少了数个量级。在存储开销方面,对于端侧部署的模型,词表大小 | V | 通常在数万左右,与 D_r 为相同数量级,因此 MoLE 查找表的存储需求与单个专家模块的大小处于同一数量级,不会带来显著额外的存储负担。

实验结果
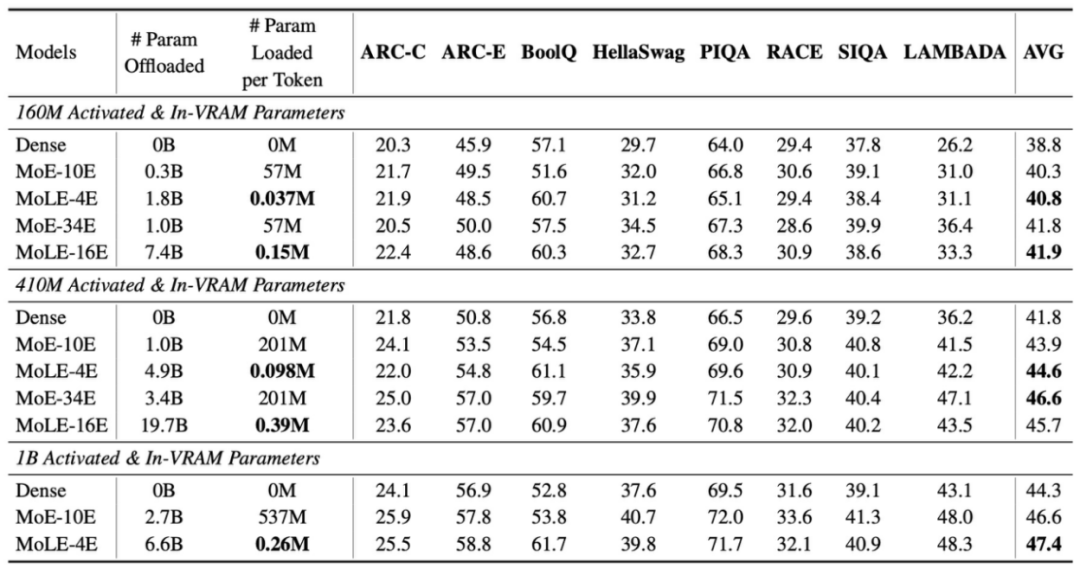
本文在 Pile 数据集的 100B-token 子集上训练了 160M、410M、1B 激活参数量的 Dense、MoE 和 MoLE 模型。对于 MoE 和 MoLE 模型,控制两者的训练阶段参数量相等。由于实验中以及近期 OLMoE 的结果都发现共享专家会降低 MoE 的性能,我们对 MoE 只采用了路由专家。MoLE 的专家大小与 Dense 的 FFN 保持一致,而 MoE 由于需要激活两个专家,其专家大小为 dense FFN 的一半,但专家数量是 MoLE 的两倍。

实验结果表明 MoLE 在相同训练参数量和推理激活参数量(即显存使用量)下,具有与 MoE 相当的性能,相比 Dense 有显著提升。与专家卸载的 MoE 相比,MoLE 减少了千倍以上的传输开销。
在 V100 上进行的评测结果表明,在显存用量一定的前提下,MoLE 的推理延迟与 Dense 基本一致,显著优于专家卸载的 MoE。在批量解码场景下,随着 batch size 的增加,MoE 的推理延迟迅速上升,而 MoLE 与 Dense 模型的延迟则基本保持稳定,进一步展现了 MoLE 在高吞吐量推理任务中的优势。


此外,消融实验表明,MoLE 的训练确实不需要辅助损失。
在专家数量提升时,模型性能也会提升

然而,如果仅增大专家的隐层维度,由于查找表的大小保持不变,当专家规模增大到一定程度时,推理性能将受限于查找表的固定大小,最终达到饱和。

作者通过将一个 MoE 模型逐步修改为 MoLE 模型,系统性地探索了 MoLE 各组成部分对性能的影响。实验结果表明,使用浅层的 embedding token 作为专家输入确实会削弱模型的表达能力,这是由于输入中缺乏丰富的上下文信息所致。然而,激活所有专家有效弥补了这一损失,使得 MoLE 最终能够达到与 MoE 相当的性能水平。

需要注意的是,路由专家的输入不包含上下文信息,并不意味着专家无法影响模型对上下文的处理。实际上,专家可以通过改变其输出,从而间接影响后续注意力层的输入,实现对上下文的建模。此外,共享专家和路由仍然接收包含上下文信息的输入,进一步保障了模型对上下文理解能力的保留。
最后,作者发现查找表中仍然存在较大程度的冗余。即使将查找表压缩至 3-bit 精度(例如使用 NF3 格式),模型性能依然能够基本保持不变。这表明查找表在存储开销上仍具有进一步压缩和优化的潜力。

总结
综上,本文提出了 MoLE,一种面向端侧部署优化的新型 MoE 架构。通过将专家输入改为浅层的 embedding token,并采用查找表替代传统的矩阵运算,MoLE 有效解决了传统 MoE 在推理阶段面临的显存开销大、传输延迟高的问题。实验结果表明,MoLE 在保持与 MoE 相当性能的同时,大幅降低了推理延迟,尤其在批量解码场景中展现出显著优势。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com