ICLR 2025论文介绍:ECI通过平滑分位数损失函数,改进在线共形推断在时间序列预测中的性能,能快速适应分布变化,并生成更紧凑的预测区间。
原文标题:ICLR 2025 | ECI:一种能改善时序共形推断性能的损失函数
原文作者:数据派THU
冷月清谈:
本文介绍了一篇被 ICLR 2025 接收的论文,该论文提出了一种名为误差量化共形推断(Error-quantified Conformal Inference, ECI)的新方法,旨在提升时间序列预测中不确定性量化的性能。ECI 通过引入平滑分位数损失函数,构建连续的反馈机制,更准确地捕捉覆盖误差的动态变化,从而改进在线共形推断在时间序列预测中的表现。
文章首先指出现有不确定性量化方法,如传统参数模型、复杂机器学习模型以及分位数回归模型等,在处理时间序列数据时存在局限性。而共形推断虽然可以在不依赖数据分布假设的情况下保证预测区间的覆盖率,但在时间序列数据中因其强相关性和潜在的分布变化而面临挑战。针对这些问题,论文提出了 ECI 方法,其核心在于通过平滑分位数损失函数量化覆盖误差,并引入连续反馈机制,以便更快地适应时间序列中的分布变化,生成更紧凑的预测区间。
论文还介绍了 ECI 的两个扩展版本,ECI-cutoff 和 ECI-integral,分别通过引入截断阈值避免小误差导致的过度调整,以及整合多步误差信息提高覆盖稳定性。此外,论文还提供了 ECI 的分布无关覆盖保证,并通过在多个真实世界和合成数据集上的大量实验,验证了 ECI 及其变体在保持目标覆盖水平的同时,能够生成比现有方法更紧凑的预测区间。
文章首先指出现有不确定性量化方法,如传统参数模型、复杂机器学习模型以及分位数回归模型等,在处理时间序列数据时存在局限性。而共形推断虽然可以在不依赖数据分布假设的情况下保证预测区间的覆盖率,但在时间序列数据中因其强相关性和潜在的分布变化而面临挑战。针对这些问题,论文提出了 ECI 方法,其核心在于通过平滑分位数损失函数量化覆盖误差,并引入连续反馈机制,以便更快地适应时间序列中的分布变化,生成更紧凑的预测区间。
论文还介绍了 ECI 的两个扩展版本,ECI-cutoff 和 ECI-integral,分别通过引入截断阈值避免小误差导致的过度调整,以及整合多步误差信息提高覆盖稳定性。此外,论文还提供了 ECI 的分布无关覆盖保证,并通过在多个真实世界和合成数据集上的大量实验,验证了 ECI 及其变体在保持目标覆盖水平的同时,能够生成比现有方法更紧凑的预测区间。
怜星夜思:
1、ECI方法中提到的“平滑分位数损失函数”具体是如何实现“平滑”的?这种平滑处理对最终的预测结果产生了什么样的影响?
2、ECI 方法的两个扩展版本 ECI-cutoff 和 ECI-integral 分别从哪些角度改进了原始的 ECI 方法?在实际应用中,我们应该如何选择使用哪个版本?
3、文章中提到 ECI 具有“分布无关的覆盖保证”,这是什么意思?这种保证在实际应用中有多大的价值?
2、ECI 方法的两个扩展版本 ECI-cutoff 和 ECI-integral 分别从哪些角度改进了原始的 ECI 方法?在实际应用中,我们应该如何选择使用哪个版本?
3、文章中提到 ECI 具有“分布无关的覆盖保证”,这是什么意思?这种保证在实际应用中有多大的价值?
原文内容

来源:时序人本文共2700字,建议阅读10分钟
本文介绍一篇 ICLR 2025 接收的工作,该工作提出的 Error-quantified Conformal Inference(ECI)方法通过平滑分位数损失函数。
时间序列预测中的不确定性量化是一个重要问题,尤其是在金融、气候科学、流行病学等高风险领域。本文介绍一篇 ICLR 2025 接收的工作,该工作提出的 Error-quantified Conformal Inference(ECI)方法通过平滑分位数损失函数,引入连续的反馈机制,能够更准确地捕捉覆盖误差的动态变化,改进在线共形推断在时间序列预测中的性能。

【论文标题】
Error-quantified Conformal Inference for Time Series
【论文地址】
https://arxiv.org/abs/2502.00818
【论文源码】
https://github.com/creator-xi/Error-quantified-Conformal-Inference
研究背景
时间序列预测中的不确定性量化对于许多领域(如金融、气候科学、流行病学、能源、供应链和宏观经济等)至关重要,尤其是在高风险领域。理想的模型应该能够持续输出校准良好的预测区间,即随着时间的推移,包含真实标签的预测区间的比例应与预期置信水平一致。然而,现有的不确定性量化方法存在以下局限性:
-
传统方法:依赖于时间序列模型的严格参数假设(如 ARMA 模型),难以适应复杂的数据分布。
-
复杂机器学习模型:如贝叶斯循环神经网络和深度高斯过程难以自行校准。
-
分位数回归模型:可能在估计不确定性时“过拟合”。
-
Transformer 等复杂模型:虽然预测准确,但无法提供有效的预测区间。
共形推断作为一种评估机器学习模型不确定性的工具,能够在不依赖数据分布参数假设的情况下,保证预测区间以指定概率包含真实标签。然而,共形推断在时间序列数据中面临挑战,因为时间序列数据通常不满足可交换性假设,而是存在强相关性和潜在的分布变化。
近年来,研究者们提出了在线共形推断方法,如 Adaptive Conformal Inference(ACI)。这些方法通过在线学习技术动态调整预测区间的大小,但它们仅使用二元反馈(即是否覆盖真实标签),忽略了误差量化(即非一致性分数与当前阈值之间的距离)。这种简单的二元反馈无法精确捕捉覆盖误差的大小,导致在面对分布变化时,模型需要更长时间来纠正错误。

图1:在谷歌股票数据集上,采用Prophet模型时,在线(次)梯度下降法(OGD)与误差置信区间(ECI)方法的对比结果
为了克服现有方法的局限性,本文提出了 Error-quantified Conformal Inference(ECI)方法。ECI 的核心思想是通过平滑分位数损失函数,引入连续的反馈机制,从而更准确地捕捉覆盖误差的动态变化。具体贡献包括:
-
提出 ECI 方法:基于自适应更新和额外的平滑反馈,量化覆盖误差的程度。ECI 不仅使用二元反馈,还引入了误差量化(EQ)项,能够快速适应时间序列中的分布变化。
-
扩展版本:提出了 ECI 的两个变体,ECI-cutoff 和 ECI-integral。ECI-cutoff 通过引入截断阈值来避免小误差导致的过度调整;ECI-integral 通过整合多步误差信息来提高覆盖的稳定性。
-
理论保证:提供了 ECI 的分布无关覆盖保证。在固定学习率的情况下,证明了 ECI 能够实现长期覆盖误差的控制。此外,对于任意学习率,本文还给出了平均覆盖误差的有限样本上界。
-
实验验证:通过在多个真实世界数据集(包括金融、能源和气候领域)和合成数据集上的广泛实验,验证了 ECI 及其变体在保持目标覆盖水平的同时,能够生成比现有方法更紧凑的预测区间。
ECI方法
01 通过平滑反馈进行误差量化
在时间序列预测中,现有的在线共形推断方法(如 ACI)通过在线梯度下降(OGD)更新预测区间的阈值,但这些方法仅使用二元反馈(即是否覆盖真实标签),忽略了误差量化(即非一致性分数与当前阈值之间的距离)。为了更准确地利用覆盖误差的动态变化,本文提出了 ECI 方法。

图2:EQ函数随变量x的动态变化,其中f(x)为Sigmoid函数,且c=1
ECI 的核心思想是通过平滑分位数损失函数,引入连续的反馈机制。具体来说,ECI 不仅使用二元反馈,还引入了误差量化(EQ)项,用于评估误差的大小。通过这种方式,ECI 能够更快速地适应时间序列中的分布变化,并生成更紧凑的预测区间
02 扩展版本
为了进一步优化 ECI 的性能,本文提出了两个扩展版本:
-
ECI-cutoff:通过引入截断阈值来避免小误差导致的过度调整。当误差较小时,ECI-cutoff 会限制 EQ 项的影响,从而避免过度调整。
-
ECI-integral:通过整合多步误差信息来提高覆盖的稳定性。这种方法考虑了过去多个时间步的误差,从而在动态调整阈值时更加稳健。
03 分布无关的覆盖保证
在这一部分,作者提供了 ECI 的理论覆盖保证。具体来说,提出了两个假设:
-
假设1:对于任意的正整数 t,存在一个正数 B,使得 st∈[0,B]。这假设了分数的有界性。
-
假设2:对于任意的实数 x,有 ∣x∇f(x)∣≤λ 和 ∣∇f(x)∣≤c,其中 λ,c>0 是常数。这假设了平滑函数的梯度有界。
在这些假设下,作者证明了 ECI 的两个主要理论结果:
-
定理1:在固定学习率的情况下,ECI 能够实现长期覆盖误差的控制。具体来说,每个误覆盖步骤都将至少跟随 N−1 个覆盖步骤,其中 N=⌊α−1⌋。这保证了 ECI 在任意时间窗口内的误覆盖率不超过 α。
-
定理2:对于任意学习率序列,ECI 的平均误覆盖误差的上界为:

其中,
这表明 ECI 在任意学习率下都能保持良好的覆盖性能。
实验结果
实验涉及多个真实世界数据集,包括股票价格(Amazon 和 Google)、电力需求和德里温度数据以及一个合成数据集。作者使用了多种基预测器(如 Prophet、AR 模型和 Theta 模型)和多种基线方法(如 ACI、OGD、SF-OGD 等)进行比较。
01 金融领域结果
在股票价格预测任务中,ECI 及其变体在控制预测区间宽度方面表现出色,同时保持了较高的覆盖精度。例如,在 Amazon 股票数据集上,ECI-cutoff 实现了最窄的平均宽度和中位宽度,同时保持了接近目标水平的覆盖精度。

表1:在亚马逊股票数据集上的实验结果(名义水平α = 10%)

表2:在谷歌股票数据集上的实验结果(名义水平α = 10%)
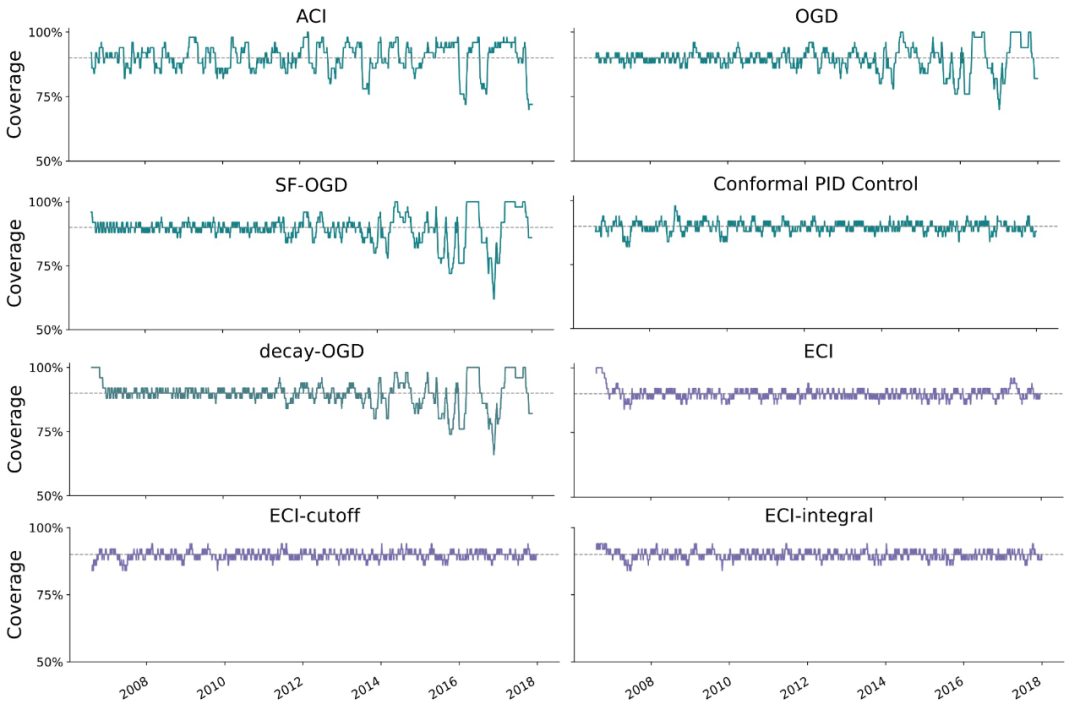
图3:在亚马逊股票数据集上与Prophet模型进行的覆盖率对比结果

图4:在亚马逊股票数据集上,使用Prophet模型得到的预测集对比结果

在德里温度预测任务中,ECI-cutoff 在所有方法中表现最佳,实现了最窄的预测区间宽度,同时保持了较高的覆盖精度。

表4:在德里温度数据集上的实验结果(名义水平α = 10%)
04 合成数据集结果
在合成数据集上,ECI-cutoff 和 ECI-integral 在覆盖精度和预测区间宽度方面均优于其他基线方法。

表5:在合成数据集上的实验结果(名义水平α = 10%)
总结
不少在线共形推断方法都存在一个显著局限,即未对过度/不足覆盖的程度进行量化。在本研究中,作者提出误差量化共形推断(Error-quantified Conformal Inference, ECI),用于构建时间序列数据的预测集。
与自适应共形推断(ACI)及其变体相比,ECI 通过测量误差 st−qt 的幅度,引入了额外的平滑反馈。ECI 能够快速适应时间序列中的分布变化,并生成更紧凑的共形预测集。从理论上来看,作者在短区间内为固定学习率的 ECI 建立了有限样本覆盖保证,并证明了在任意学习率下的误覆盖界限。从实证角度来看,作者在大量数据集上验证了该方法的有效性和效率。
编辑:王菁
