LUFFY提出一种强化学习新范式,融合模仿学习与强化学习的优势,实现AI“边学边练”,在数学推理任务上取得显著提升。
原文标题:边学边练,推理觉醒:LUFFY让强化学习即学即用!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 LUFFY 在训练初期,推理路径长度会逐渐接近离策略轨迹,这说明了什么? 这种现象是好是坏?
3、LUFFY 强调通过策略塑形来保持模型的探索能力,但过度的探索是否也会影响模型的稳定性和收敛速度?
原文内容

破解 “只学不练” 与 “只练不学” 的难题
想象你准备参加一场高水平的数学竞赛。如果你只是反复背诵往年题目的标准答案,从不亲自动手解题,那么一旦遇到新题型,很可能束手无策;反过来,如果你闭门造车,只凭自己反复试错而从不参考老师和高手的解题经验,进步又会异常缓慢。这就好比 AI 模型训练中长期存在的两种极端:「模仿学习」 只顾照搬示范却缺乏自我实践,「强化学习」 一味自我探索却不借鉴现有经验。
这两种「只学不练」和「只练不学」的策略各有弊端:前者往往学得快但泛化差,后者可能探索勤但效率低。那么,有没有两全其美的办法,让模型既能借鉴高手经验又能保持自主探索?最近,上海 AI 实验室联合西湖大学、南京大学和香港中文大学的研究团队提出了一种全新的强化学习范式:LUFFY(Learning to reason Under oFF-policY guidance)。

-
论文链接:https://arxiv.org/abs/2504.14945
-
代码仓库:https://github.com/ElliottYan/LUFFY
LUFFY 的核心理念是:在训练过程中让模型同时借助高手的推理轨迹进行学习(离策略示范),又能继续独立地试错探索(在线推理),从而实现 「边学边练,学以致用」的目标。实验显示,LUFFY 在多个数学推理挑战任务中实现了平均 + 7.0 分的性能飞跃,并在分布外任务上展现出显著的泛化能力。
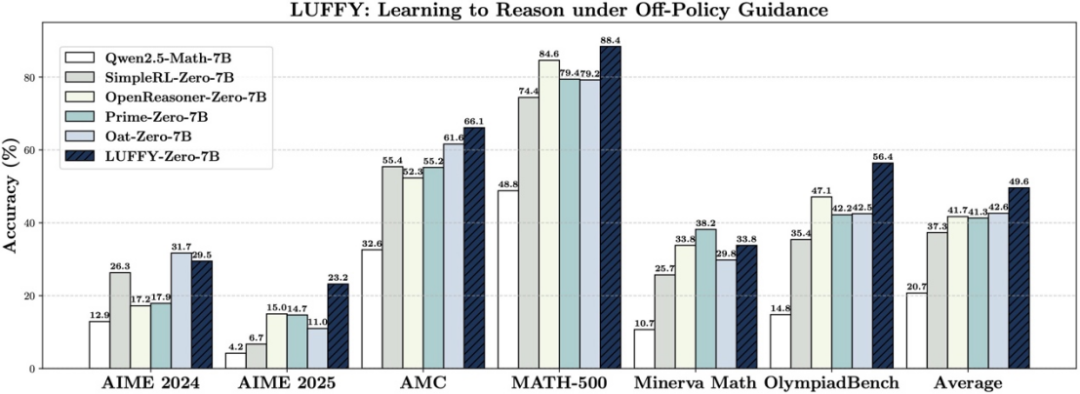
图表 1. 在六项竞赛级数学推理基准上的整体表现。在 AIME 2024、AIME 2025、AMC、MATH-500、Minerva Math 和 OlympiadBench 六个高难度基准测试中,LUFFY 取得了平均 49.6% 的准确率,较现有 Zero-RL 方法实现了超过 + 7.0 分的显著性能提升。
该工作一经发布,便登上 Hugging Face 社区的 Daily Papers 热榜第一,并在权威学术论坛 alphaXiv 上引起热烈讨论。


模仿学习与强化学习的两难困境
当前主流的大模型推理训练方法可分为两类:
-
模仿学习(SFT):模型参考专家解题轨迹进行学习,相当于「看答案抄题」,虽然能快速学习已知方法,但遇到新题可能难以适应,缺乏自主能力。

图表 2. 模仿学习(SFT):模仿专家模型生成的高质量推理轨迹。
-
强化学习(Zero-RL):模型通过不断试错获得奖励反馈并优化自身策略,虽然具备一定泛化能力,但如果起点策略弱,容易陷入局部最优,难以突破上限。

图表 3. 强化学习:与环境(如验证器)的交互反馈,不断优化自身策略。
这两种方法各有优势,却也各有短板。LUFFY 的提出,正是为了打破这种二元对立,融合两者优点,解决模型「既学得深,又练得广」的核心问题。
LUFFY 的直觉与机制:高手示范,模型探索
LUFFY 的关键思想是:在强化学习过程中引入 「离策略指导」,即使用来自更强模型或专家的推理轨迹来作为引导,这区别于当前主流的仅使用模型自身策略优化自己的主流强化学习范式。
这就像一个学生,一边借助老师提供的经典例题,一边继续独立完成练习题。在 LUFFY 中,模型通过混合使用两类轨迹进行训练:一是自己当前策略下生成的在线推理过程(on-policy),二是从强者那里借来的离线示范(off-policy)。这两类轨迹一起用于策略优化,让模型做到「边学边练」。

图表 4. LUFFY:边学边练的推理学习框架。LUFFY 在强化学习框架中引入外部优质推理轨迹,通过 「策略塑形」 机制,融合自身尝试(on-policy)与专家示范(off-policy)的优势。当模型自身推理失败时,它从专家示范中学习关键步骤;而当自身表现优异时,则保持独立探索。该机制在保持探索能力的同时,引导模型聚焦于低概率但关键的行动,从而实现推理能力的持续进化与泛化。
技术亮点:混合策略与策略塑形
LUFFY 的实现依托于 GRPO 算法框架,并围绕两项核心机制展开:
1. 混合策略训练:同时利用在线轨迹和离线示范,引导模型向高奖励动作靠拢,同时保留自身有效尝试。
2. 策略塑形函数(图 6):通过非线性加权机制强化对关键步骤的学习,防止模型过早收敛、策略熵降低,保持持续探索。图 5 展示了策略塑形对梯度更新的非线性权重以及对模型探索的影响。

图表 5. 策略塑形在 LUFFY 中的作用效果。左图:训练过程中的策略熵对比。中图:不同方法下损失函数基于决策概率的权重分配。右图:基于决策概率的梯度加权情况对比。LUFFY 通过非线性权重提升了对罕见(低概率)但重要行为的梯度响应,进而引导模型更有效地从 off-policy 示范中习得深层推理模式。

图表 6. 策略塑形函数 f () 可被看作正则约束下的重要性采样,鼓励模型关注低概率、但可能重要的行为决策。
实验结果:即学即练,举一反三

图表 7. 训练动态分析:训练初期,LUFFY 模型逐步适应外部指导,推理路径长度逐渐接近离策略轨迹,表现出有效的模仿与调整。同时,在整个训练过程中,LUFFY 始终保持了较高的策略熵,展现出持续探索的能力。而对比来看,传统 on-policy RL 的熵在早期迅速收敛,探索能力下降。
在六个公开数学推理基准中,LUFFY 相较于现有 Zero-RL 方法,平均提升达 + 7.0 分,并且在多个分布外测试集上也实现了领先表现。

图表 8. LUFFY 在六项高难度数学推理基准上的性能表现。
图表 9. 分布外测试集的性能表现(ARC-c,GPQA-diamond 和 MMLU-Pro)。
在其他模型,如更小的 1.5B 模型与指令对齐后的 Instruct 模型,LUFFY 也表现出显著优势:

图表 10. LUFFY 在 Qwen2.5-Math-1.5B 上的性能表现。

图表 11. LUFFY 在 Qwen2.5-Instruct-7B 上的性能表现。
不仅如此,LUFFY 在「推理路径长度」上也明显优于 SFT。在相同准确率下,LUFFY 能用更短的推理过程达成正确答案,减少无效展开;而在测试时调高温度以增加探索强度时,LUFFY 的性能依然保持稳定,而 SFT 则出现明显下降。

图表 12. 推理长度对比。

图表 13. 测试时探索能力对比。
展望:通用推理的新起点
LUFFY 提出了一种高效、稳定、具备泛化能力的推理训练方式,兼顾学习与实践,让模型真正掌握推理策略的内在逻辑。未来,该框架可扩展至代码生成、科学问答、自动规划等需要复杂推理的 AI 任务中,构建更具通用性和自主性的智能体。
目前项目已在 GitHub 开源,欢迎有兴趣的同学了解、复现或拓展。
作者介绍:

颜建昊,西湖大学张岳老师的博士三年级学生。主要研究兴趣在基于大模型的后训练技术,包括强化学习、在线学习以及模型编辑等。在读博之前,颜建昊曾在微信 AI 任研究员,曾赢得 WMT 机器翻译比赛。

李雅夫博士,现任上海人工智能实验室研究员,研究方向涵盖大语言模型推理、可信人工智能与机器翻译。他于浙江大学与西湖大学联合培养攻读博士学位,先后在爱丁堡大学与武汉大学获得人工智能硕士和电子信息工程学士学位。李雅夫博士在 ACL、EMNLP、ICLR 等顶级会议上发表多项研究成果,引用逾 1800 次,曾荣获 ACL 2023 最佳论文提名,并担任 ACL 领域主席及多个国际顶会与期刊的审稿人。博士期间,他曾获得国家奖学金,入选腾讯犀牛鸟精英人才计划并获得杰出奖学金。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com