研究者提出 SICA,一个能够自我改进代码的智能体,实验表明其在特定任务上性能提升显著,并开源了实现。
原文标题:成熟的编程智能体,已经学会升级自己的系统了
原文作者:机器之心
冷月清谈:
SICA 的核心运行循环与之前的 ADAS 类似,都保留了历史智能体的档案和基准结果。但 SICA 会从档案中选取表现最佳的智能体作为元智能体,并指示其查看档案,确定改进方案并实施。研究者使用一个效用函数来评估智能体的性能,该函数综合考虑了基准性能、运行时间和成本等因素。实验结果表明,SICA 在文件编辑、符号导航等任务上取得了显著进展,但在推理能力较强的领域,改进幅度较小,这突出了基础模型和智能体系统之间相互作用的重要性。
怜星夜思:
2、论文中提到 SICA 在推理能力较强的任务上改进不明显,你觉得是什么原因导致的?如何改进?
3、SICA 的开源,对于 AI 领域的开发者来说,意味着什么?你觉得它在哪些方面具有应用潜力?
原文内容
编辑:蛋酱
编程智能体,几乎成为了 2025 年最热门的话题之一。不管是学术机构还是工业界,都在寻找更高效的落地路径。
机器学习领域的历史经验表明,手工设计的解决方案最终会被学习到的解决方案所取代。我们好奇一个问题:智能体本身是否可以通过发现新的提示方案或工具,无需人工设计和实施,就自主修改和改进自己的代码?
2024 年,《Automated Design of Agentic Systems》(Hu et al., 2024) 一文率先尝试了使用元智能体来优化智能体实现,将智能体系统自动设计(ADAS)这一领域往前推了一步。不过,该研究并未探索「自我改进」,因为其中有两个独立的智能体:执行任务的目标智能体和改进目标智能体的元智能体。
而来自布里斯托大学和 iGent AI 的研究者认为,完全自我参照式的元智能体编程方式在今天是可实现的,并提供了一种合理的替代方案。

-
论文标题:A SELF-IMPROVING CODING AGENT
-
论文链接:https://arxiv.org/pdf/2504.15228
-
代码地址:https://github.com/MaximeRobeyns/self_improving_
具体来说,这项研究贡献如下:
-
自我改进编码智能体(SICA)消除了元智能体和目标智能体之间的区别,能够编辑自己的代码库,在成本、速度和基准性能方面进行自我改进。
-
自我参照智能体可有效改进自身的实现。研究者发现,即使考虑到安全限制和资源效率,在 SWE Bench 验证的随机子集上,性能也能提高 17% 到 53%。
-
研究者与社区分享了自我改进编码智能体(SICA)的实现。SICA 是用标准 Python 实现的,没有特定领域的语言,它为构建新的 SICA 系统提供了一个参考智能体框架,也为那些寻求在工具使用和其他智能体任务方面对 LLM 进行后训练的人提供了一个参考智能体框架。
方法概览
SICA 的主要运行循环类似于 Hu et al. (2024) 的 ADAS 循环。特别是,SICA 和 ADAS 都保留了以前智能体的档案及其基准结果。
第一步,SICA 从存档中选取到目前为止表现最好的智能体作为元智能体,指示元智能体查看存档,确定改进方案并加以实施。
算法 1 展示了这一高级方案:

请注意,这与 ADAS 不同,ADAS 有一个固定的元智能体,因此不会从档案中选择元智能体(ADAS 中的档案是目标智能体档案,而不是元智能体档案)。
其次,ADAS 和 SICA 都会在一组评估基准上对新智能体进行评估,并存储评估结果。
研究者用一个效用函数来定义性能「最佳」的智能体,该函数包含了一个优秀智能体的共同期望值:标准化基准性能分数 p_score ∈ [0,1]、以秒为单位的挂钟时间 p_time,以及美元成本 p_cost。基本效用的计算公式为
其中,研究者将系数设为 w_score = 0.5、w_cost = 0.25 和 w_time = 0.25。此处将每个问题的最差成本设定为 10 美元,并规定 300 秒的超时时间,超时后将取消智能体。为了对超时前所做的工作给予部分奖励,按以下方法计算最终效用,超时惩罚为 τ = 0.5:

需要注意的是,由于不进行任何权重更新,这个数字分数只用于挑选下一个元智能体以及下一次迭代的基础智能体。
首先介绍初始编码智能体,然后介绍基准运行框架,以及该框架如何自然而然地允许我们创建一个自我参照任务(即改进编码智能体)。
智能体上下文的结构至关重要,它包含打开的文件内容等,而不仅仅是提示。在初始编码智能体中,上下文结构如图 3 所示。

首先呈现的是包含智能体定义的系统提示,列出了智能体可用工具的定义以及可调用的子智能体。系统提示的最后是系统信息,例如如何跳出智能体循环并返回调用流程的说明。
接下来是「核心提示」,它被设置为聊天模板格式中的第一条用户信息,包含呼叫者指定的要处理的问题陈述(呼叫者可能是调用智能体的用户,也可能是呼叫子智能体的智能体)。在这里,研究者还插入了智能体已打开文件的视图以及当前工作目录的表示。
最后,LLM 智能体上下文的其余部分是运行助理信息。其中包含对问题的一连串推理、工具调用及其响应、子智能体调用及其响应,以及来自异步监督系统的任何通知或评论。
LLM 上下文以这种方式布局,允许添加新内容,从而保留 KV 缓存,以减少工具调用之间的延迟和成本。对于基础智能体,此处采用了一种简单的方案,即文件编辑内容以差异形式添加,并在累积到一定数量后定期重新合并到陈旧文件视图中。智能体可以编写更复杂的 KV 缓存保存方案,以降低成本。
实验结果
研究者首先展示了在基准集中包含相对长周期任务的运行,选取了 SWE Bench Verified,包括测试问题分解、代码导航以及快速高效的文件编辑,研究者从中选择了 50 个问题的固定随机子集;他们还从 LiveCodeBench 中随机抽取了 50 个问题,这些问题类似于竞技编程,通常包含更多理论推理。此外,研究者还选取了两个「合成」基准任务示例,它们完全是在智能体的代码库中定义和策划的。
大多数智能体中使用 Sonnet 3.5 (v2) (Anthropic) 运行智能体系统,只有一个「推理智能体」使用 o3 mini。结果如图 3 所示,更详细的迭代级性能数据见表 1。
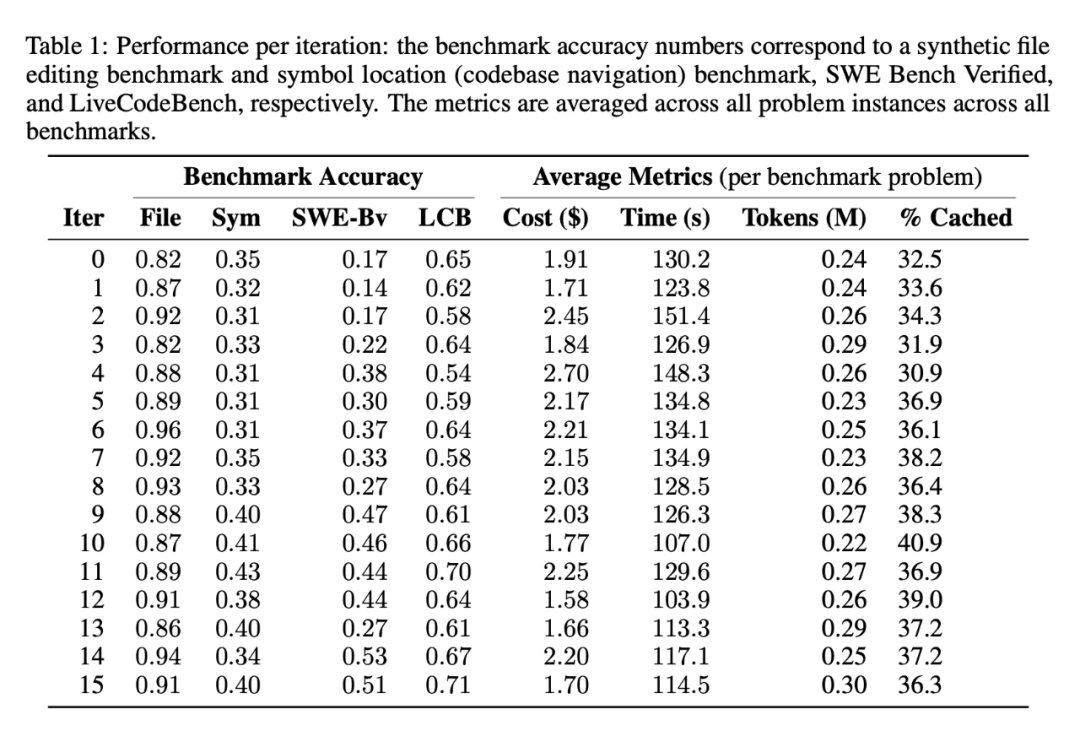
结果数据显示了令人鼓舞的进展。在文件编辑基准测试中,智能体最初只具备覆盖文件的能力,这不仅速度慢,而且 token 效率低下,但它很快就实现了基于差异和范围的自称「智能」的编辑工具;在符号导航任务中,智能体在第 9 次迭代时实施了基于 AST 的简单符号定位器(也许是利用了基准测试主要基于 Python 的事实),取得了良好的改进,这也反映在其他任务中。LiveCodeBench 的得分也有细微提高,但不如其他一些基准测试明显。
研究者还评估了自我参照智能体系统在提高推理能力较强的领域的任务性能方面的有效性。他们使用基准集中的两个问题解答任务进行了另一项实验: 图 4 显示了实验结果。这里的结果显示改进较少,并突出了基础模型和「脚手架系统」之间的重要相互作用。
图 4 中迭代 0 的基础智能体系统使用 Sonnet 3.5,「推理」子智能体使用 o3-mini。o3-mini 模型本身在 AIME 和 GPQA Diamond 上的得分分别为 87% 和 79%,具有「高」推理能力,而整个智能体系统在这两个基准测试中的平均得分为 76%。

通过观察轨迹,研究者发现,在许多运行中,主智能体只是将问题委托给基于 o3-mini 的推理智能体,并没有充分利用智能体系统的全部能力。对于 o1、o3-mini 或 DeepSeek-R1 等「推理模型」,研究者怀疑加入旨在诱导推理行为的粗糙组件(如图 4 中迭代 4 和 6 中的组件)实际上可能会打断在智能体系统之外训练的推理模型的推理思维链,从而导致性能下降。
更多研究细节,可参考原论文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com