HyCoCLIP利用双曲空间和组合蕴涵学习,提升视觉语言理解,零样本分类优于CLIP和MERU,更擅长场景理解和分层结构。
原文标题:ICLR 2025|Top3高分论文HyCoCLIP:双曲视觉语言模型的组合蕴涵学习
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、HyCoCLIP 在训练时需要生成边界框信息,这在实际应用中会带来哪些挑战?有没有可能在不依赖边界框信息的情况下实现类似的效果?
3、文章提到 HyCoCLIP 在大规模检索任务中可能表现不佳,这可能是由哪些因素导致的?未来有哪些改进方向?
原文内容


HyCoCLIP 简介
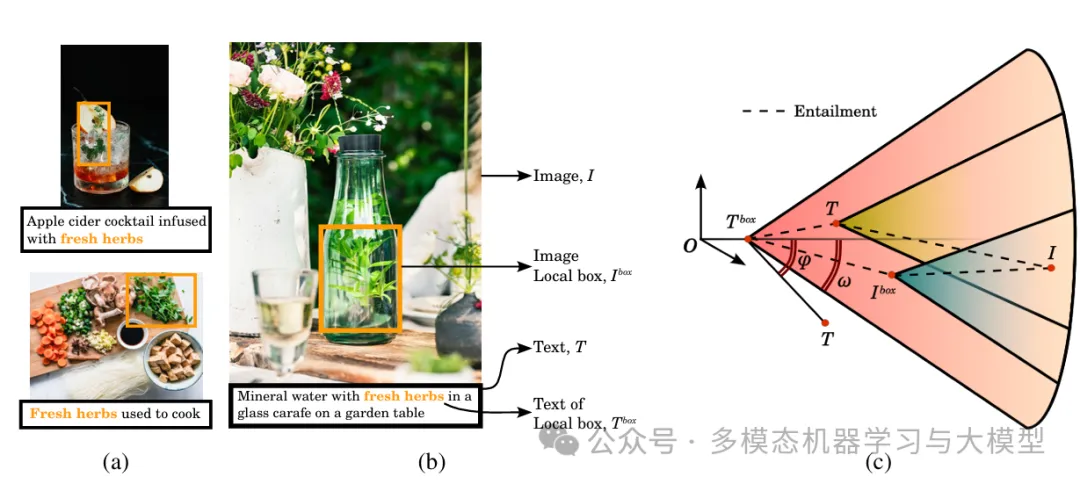
LLM 无法理解视觉和文本概念的固有层次性,因为传统模型(如 CLIP)主要关注欧几里得空间中的整体图像-文本对齐。本文提出了一种名为 HyCoCLIP 的新方法,该方法利用双曲空间(更适合表示层次结构),并引入了一种新颖的组合蕴涵学习方法,该方法同时考虑整个图像-文本对及其组合元素(如对象框及其文本描述)。
该方法不仅保留了图像和文本之间更广泛的上下文,而且还通过将更广泛的概念定位在双曲空间的原点附近并将更具体的概念定位在边界附近,保留了组件之间的层次关系(例如,单个对象与整体场景的关系)。这种方法旨在创建一种语义更丰富、层次意识更强的表示,可以更好地捕捉视觉和语言信息的自然结构。
HyCoCLIP 是什么?
HyCoCLIP 模型利用两个主要组件来学习双曲空间中图像和文本之间的层次关系。第一个组件使用对比学习方法,将完整图像与其完整文本描述对齐,将对象框(图像的裁剪区域)与其相应的文本描述对齐。重要的是,该模型旨在通过仅将整个图像与其他整个图像进行对比,将框级信息与适当的对应项进行对比,从而避免错误的负对,并认识到不同的图像可能包含相似的对象。
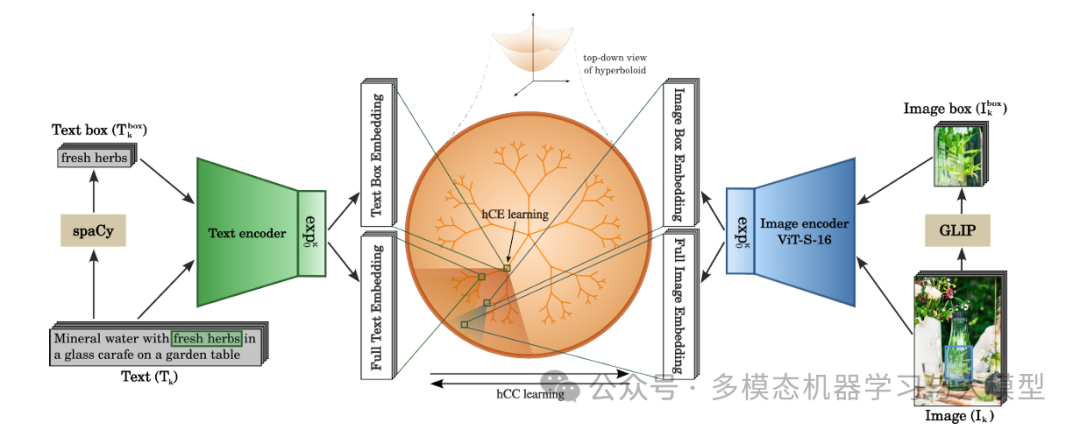
第二个组件引入了一种新颖的蕴涵学习机制,该机制可强化双曲空间中的层次关系。该模型将更一般的概念(如对象框及其描述)定位在更靠近空间原点的位置,而将更具体的概念(如具有完整上下文的完整图像)定位在离原点较远的位置。这是通过“蕴涵锥”实现的 - 双曲空间中定义概念之间父子关系的区域。
该模型使用这些锥体来维护模式间层次结构(图像和文本之间的关系)和模式内层次结构(整个图像与其部分之间的关系,或完整的文本描述与其组成部分之间的关系)。最终模型将这两个组成部分(对比学习和蕴涵学习)与适当的权重相结合,以全面理解视觉文本层次结构。
评估 HyCoCLIP
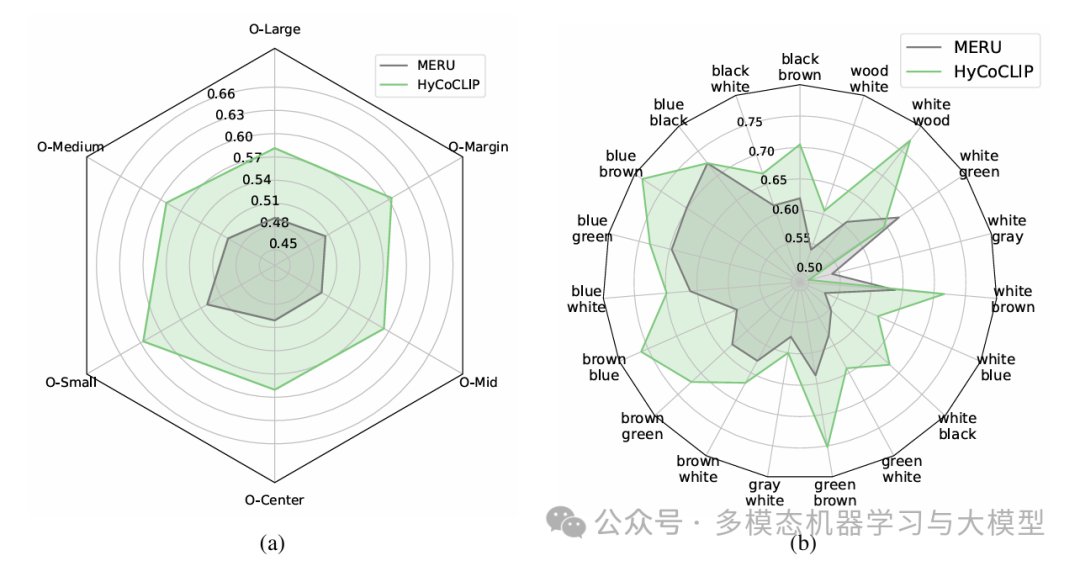
通过在 HyCoCLIP 学习到的双曲空间上应用直方图分析和降维技术(HoroPCA 和 CO-SNE),研究人员发现文本和文本框嵌入在双曲空间中表现出明显的层次分离。然而,由于对比损失收敛以及某些图像与其裁剪区域之间的固有相似性,图像和图像框嵌入往往具有相似的分布。在双曲空间中的点之间进行插值时(无论是在两幅图像之间还是从一幅图像到原点),该模型展示了合理的层次组织,这表明它成功地捕捉到了共享嵌入空间中有意义的语义关系。
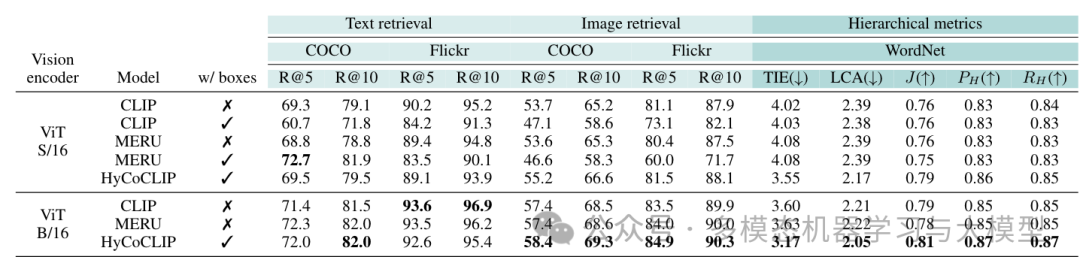
实验结果表明,HyCoCLIP在零样本分类任务中的表现优于标准 CLIP 和 MERU ,并且表现出更好的场景理解和分层结构,尽管它也面临一些限制,例如在训练期间需要生成边界框信息以及在大规模检索任务中可能表现不佳。
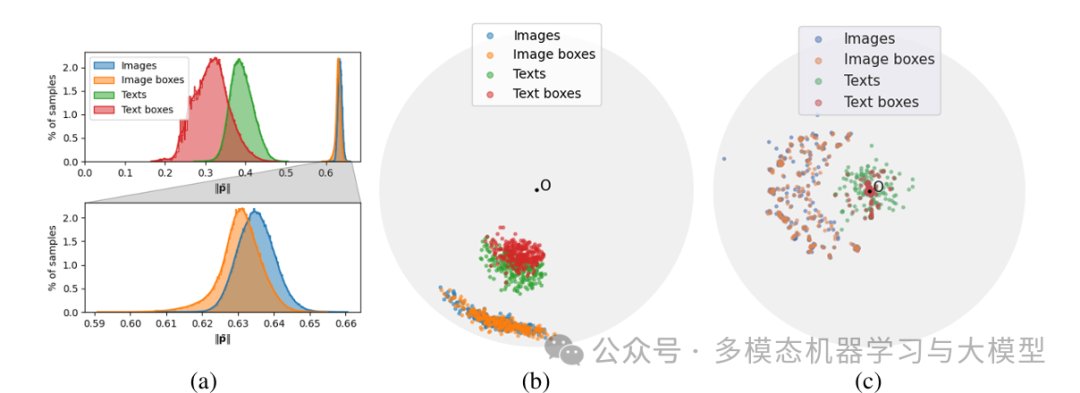
我们观察到,尽管由于处理额外的框级信息而增加了训练期间的计算开销,但该模型保持了与其前代模型相当的推理效率,同时通过嵌入空间中图像和文本的不同区域组织提供了增强的可解释性。
可视化和插值实验提供了强有力的证据,表明 HyCoCLIP 成功学习了视觉和文本内容之间有意义的层次关系,即使在明确分离图像级和框级表示方面存在一些挑战。