香港大学提出OverLoCK视觉基础模型,模仿人类视觉“纵观全局 - 聚焦细节”机制,在图像分类、检测和分割任务上表现卓越。
原文标题:卷积网络又双叒叕行了?OverLoCK:一种仿生的卷积神经网络视觉基础模型
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中说ContMix 动态卷积模块能够自适应不同输入分辨率,那么在实际部署时,如果输入图像的分辨率差异很大,会不会对模型的性能和稳定性造成影响?有什么应对策略?
3、OverLoCK 模型在多个数据集上都取得了优秀的成果,但文章中也提到了 Top-down Attention 机制与人类视觉的相似性。那么,这个模型在面对与人类视觉差异较大的特殊图像(如红外图像、医学图像)时,性能会受到影响吗?如何改进?
原文内容

前言
近期,香港大学将这种认知模式引入到了 Vision Backbone 的设计中,从而构建了一种全新的基于动态卷积的视觉基础模型,称为OverLoCK(Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels)。
作者是香港大学俞益洲教授与博士生娄蒙。
你是否注意过人类观察世界的独特方式?
当面对复杂场景时,我们往往先快速获得整体印象,再聚焦关键细节。这种「纵观全局 - 聚焦细节(Overview-first-Look-Closely-next)」的双阶段认知机制是人类视觉系统强大的主要原因之一,也被称为 Top-down Attention。
虽然这种机制在许多视觉任务中得到应用,但是如何利用这种机制来构建强大的 Vision Backbone 却尚未得到充分研究。
近期,香港大学将这种认知模式引入到了 Vision Backbone 的设计中,从而构建了一种全新的基于动态卷积的视觉基础模型,称为 OverLoCK (Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels)。该模型在 ImageNet、COCO、ADE20K 三个极具挑战性的数据集上展现出了强大的性能。例如,30M 的参数规模的 OverLoCK-Tiny 模型在 ImageNet-1K 达到了 84.2% 的 Top-1 准确率,相比于先前 ConvNet, Transformer 与 Mamba 模型具有明显的优势。

-
论文标题:
OverLoCK: An Overview-first-Look-Closely-next ConvNet with Context-Mixing Dynamic Kernels
-
论文链接:
https://arxiv.org/abs/2502.20087
-
代码链接:https://github.com/LMMMEng/OverLoCK
动机
Top-down Attention 机制中的一个关键特性是利用大脑获得的反馈信号作为显式的信息指导,从而在场景中定位关键区域。然而,现有大多数 Vision Backbone 网络(例如 Swin, ConvNeXt, 和 VMamba)采用的仍然是经典的金字塔架构:从低层到高层逐步编码特征,每层的输入特征仅依赖于前一层的输出特征,导致这些方法缺乏显式的自上而下的语义指导。因此,开发一种既能实现 Top-down Attention 机制,又具有强大性能的卷积网络,仍然是一个悬而未决的问题。
通常情况下,Top-down Attention 首先会生成较为粗糙的全局信息作为先验知识,为了充分利用这种信息,token mixer 应该具备强大动态建模能力。具体而言,token mixer 应当既能形成大感受野来自适应地建立全局依赖关系,又能保持局部归纳偏置以捕捉精细的局部特征。然而我们发现,现有的卷积方法无法同时满足这些需求:不同于 Self-attention 和 SSM 能够在不同输入分辨率下自适应建模长距离依赖,大核卷积和动态卷积由于固定核尺寸的限制,即使面对高分辨率输入时仍局限于有限区域。此外,尽管 Deformable 卷积能在一定程度上缓解这个问题,但其可变的 kernel 形态会牺牲卷积固有的归纳偏置,从而会弱化局部感知能力。因此,如何在保持强归纳偏置的前提下,使纯卷积网络获得与 Transformer 和 Mamba 相媲美的动态全局建模能力,同样是亟待解决的关键问题。
方法
让 Vision Backbone 网络具备人类视觉的「两步走」机制
研究团队从神经科学获得关键启发:人类视觉皮层通过 Top-down Attention,先形成整体认知再指导细节分析(Overview-first-Look-Closely-next)。据此,研究团队摒弃了先前 Vision Backbone 网络中经典的金字塔策略,转而提出了一种新颖的深度阶段分解(DDS, Deep-stage Decomposition) 策略来构建 Vision Backbone 网络,该机制构建的 Vision Backbone 具有 3 个子模型:
-
Base-Net:聚焦于提取中低层特征,相当于视觉系统的「视网膜」,利用了 UniRepLKNet 中的 Dilated RepConv Layer 来作为 token mixer,从而实现高效的 low-level 信息感知。
-
Overview-Net:提取较为粗糙的高级语义信息,完成「第一眼认知」。同样基于 Dilated RepConv Layer 为 token mixer,快速获得 high-level 语义信息作为 Top-down Guidance。
-
Focus-Net:在全局先验知识的引导下进行精细分析,实现「凝视观察」。基于一种全新的动态卷积 ContMix 和一种 Gate 机制来构建基本 block,旨在充分利用 Top-down Guidance 信息。
来自 Overview-Net 的 Top-down Guidance 不仅会在特征和 kernel 权重两个层面对 Focus-Net 进行引导,还会沿着前向传播过程在每个 block 中持续更新。具体而言,Top-down Guidance 会同时参与计算 Gate 和生成动态卷积权重,还会整合到 feature map 中,从而全方位地将 high-level 语义信息注入到 Focus-Net 中,获得更为鲁棒的特征表示能力。
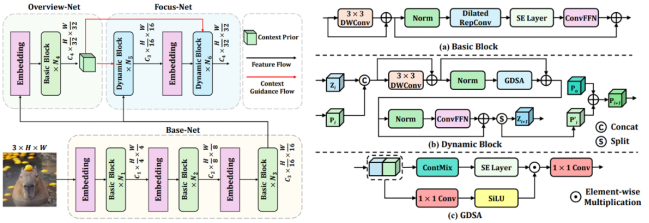

具有强大 Context-Mixing 能力的动态卷积 --- ContMix
为了能够更好地适应不同输入分辨率,同时保持强大的归纳偏置,进而充分利用 Overview-Net 提供的 Top-down Guidance,研究团队提出了一种新的动态卷积模块 --- ContMix。其核心创新在于通过计算特征图中每个 token 与多个区域的中心 token 的 affinity map 来表征该 token 与全局上下文的联系,进而以可学习方式将 affinity map 转换为动态卷积核,并将全局上下文信息注入到卷积核内部的每个权重。当动态卷积核通过滑动窗口作用于特征图时,每个 token 都会与全局信息发生调制。简言之,即便是在局部窗口进行操作,ContMix 仍然具备强大的全局建模能力。实验中,我们发现将当前输入的 feature map 作为 query,并将 Top-down Guidance 作为 key 来计算动态卷积核,相较于使用二者级联得到的特征生成的 query/key pairs 具有更好的性能。
实验结果
图像分类
OverLoCK 在大规模数据集 ImageNet-1K 上表现出了卓越的性能,相较于现有方法展现出更为出色的性能以及更加优秀的 tradeoff。例如,OverLoCK 在近似同等参数量的条件下大幅超越了先前的大核卷积网络 UniRepLKNet。同时,相较于基于 Gate 机制构建的卷积网络 MogaNet 也具有非常明显的优势。

目标检测和实例分割
如表 2 所示,在 COCO 2017 数据集上,OverLoCK 同样展示出了更优的性能。例如,使用 Mask R-CNN (1× Schedule) 为基本框架时,OverLoCK-S 在 APb 指标上相较于 BiFormer-B 和 MogaNet-B 分别提升了 0.8% 和 1.5%。在使用 Cascade Mask R-CNN 时,OverLoCK-S 分别比 PeLK-S 和 UniRepLKNet-S 提升了 1.4% 和 0.6% APb。值得注意的是,尽管基于卷积网络的方法在图像分类任务中与 Transformer 类方法表现相当,但在检测任务上却存在明显性能差距。以 MogaNet-B 和 BiFormer-B 为例,两者在 ImageNet-1K 上都达到 84.3% 的 Top-1 准确率,但在检测任务中前者性能明显落后于后者。这一发现有力印证了我们之前的论点 — 卷积网络固定尺寸的卷积核导致有限感受野,当采用大分辨率输入时可能会性能下降。相比之下,我们提出的 OverLoCK 网络即使在大分辨率场景下也能有效捕捉长距离依赖关系,从而展现出卓越性能。


语义分割
如表 3 所示,OverLoCK 在 ADE20K 上也进行了全面的评估,其性能在与一些强大的 Vision Backbone 的比较中脱颖而出,并且有着更优秀的 tradeoff。例如,OverLoCK-T 以 1.1% mIoU 的优势超越 MogaNet-S,较 UniRepLKNet-T 提升 1.7%。更值得一提的是,即便与强调全局建模能力的 VMamba-T 相比,OverLoCK-T 仍保持 2.3% mIoU 的显著优势。
消融研究
值得注意的是,所提出的 ContMix 是一种即插即用的模块。因此,我们基于不同的 token mixer 构建了类似的金字塔架构。如表 4 所示,我们的 ContMix 相较于其他 mixer 具有明显的优势,这种优势在更高分辨率的语义分割任务上尤为明显,这主要是因为 ContMix 具有强大的全局建模能力(更多实验请参见原文)。

可视化研究
不同 vision backbone 网络的有效感受野对比:如图 3 所示,OverLoCK 在具有最大感受野的同时还具备显著的局部敏感度,这是其他网络无法兼备的能力。
Top-down Guidance 可视化:为了直观呈现 Top-down Guidance 的效果,我们采用 Grad-CAM 对 OverLoCK 中 Overview-Net 与 Focus-Net 生成的特征图进行了对比分析。如图 4 所示,Overview-Net 首先生成目标物体的粗粒度定位,当该信号作为 Top-down Guidance 注入 Focus-Net 后,目标物体的空间定位和轮廓特征被显著精细化。这一现象和人类视觉中 Top-down Attention 机制极为相似,印证了 OverLoCK 的设计合理性。


本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
