DeepSeek 开源 DeepSeek-Prover-V2-671B 模型,参数量 671B,基于 Deepseek-V3 架构,上下文长度达 163,840。
原文标题:刚刚,DeepSeek-Prover-V2-671B开源模型来了
原文作者:机器之心
冷月清谈:
DeepSeek 在近期开源了 DeepSeek-Prover-V2-671B 模型。该模型参数量高达 671B,基于 Deepseek-V3 架构,拥有超大上下文处理能力,最大可处理 163,840 长度的上下文。模型采用 MoE 架构,每层都为 MoE 层,包含一个共享专家和 256 个路由专家,每个 token 激活 8 个专家。更多技术细节还有待官方技术报告的发布。
怜星夜思:
1、DeepSeek-Prover-V2-671B 采用了 MoE 架构,MoE 架构具体有什么优势?
2、DeepSeek-Prover-V2-671B 的上下文窗口达到了 163,840,这么长的上下文窗口在实际应用中有什么价值?会带来哪些新的可能性?
3、DeepSeek-Prover-V2-671B 开源后,你认为哪些开发者或者研究者会最先尝试使用它?他们可能会用它来做什么?
2、DeepSeek-Prover-V2-671B 的上下文窗口达到了 163,840,这么长的上下文窗口在实际应用中有什么价值?会带来哪些新的可能性?
3、DeepSeek-Prover-V2-671B 开源后,你认为哪些开发者或者研究者会最先尝试使用它?他们可能会用它来做什么?
原文内容
左右滑动查看更多图片
果然,还是这个节奏。
一到假期,DeepSeek就要搞事!但不是DeepSeek-R2
刚刚,DeepSeek开源了新模型:DeepSeek-Prover-V2-671B。
链接:https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B/tree/main
不到一个小时就收获了123个 like。
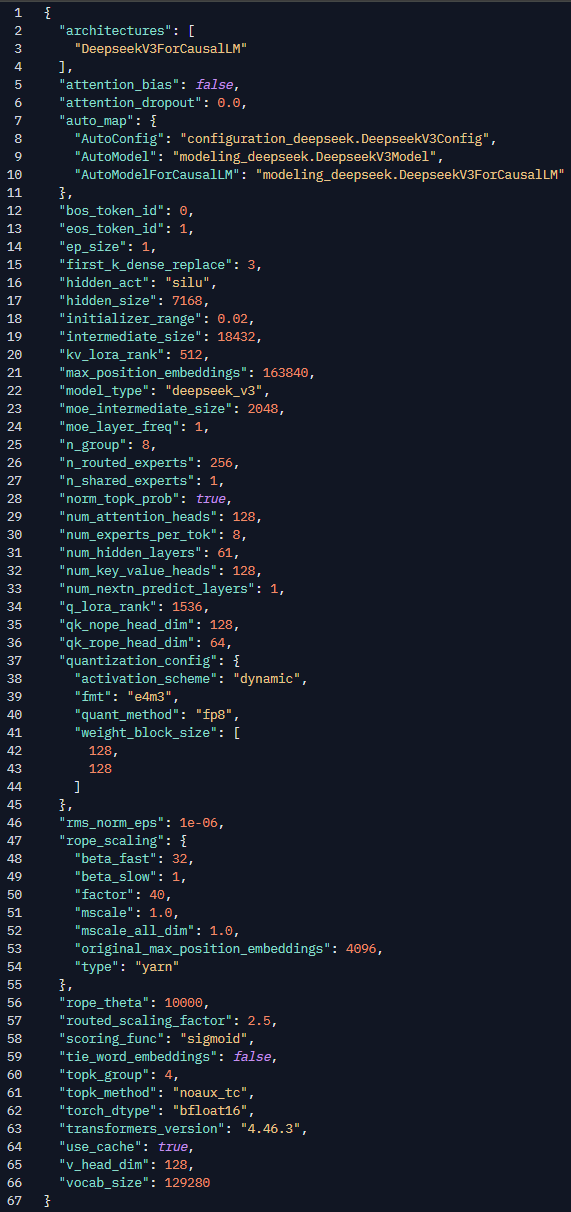
根据DeepSeek-Prover-V2-671B的config.json配置文件,我们能读到有关该模型的一些信息。
首先,从名字也能看出,该模型的参数量为 671B,采用的基础模型架构为 Deepseek-V3,也因此,很多配置都与 DeepSeek-V3 一样。比如MoE 中间层大小为 2048, moe_layer_freq 设置为1,表明每层都是 MoE 层,每个MoE 层包含1 个共享专家和256 个路由专家,每个 token 会激活 8 个专家。最大可处理 163,840 长度的上下文。
更多信息,我们就等技术报告了。