南京大学提出UniAP算法,可联合优化层内和层间并行策略,大模型训练最高加速3.8倍,并适配国产AI计算卡。
原文标题:CVPR Oral | 南京大学李武军教授课题组推出分布式训练算法UniAP,大模型训练最高加速3.8倍
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 UniAP 算法可以降低大模型训练成本,加速训练过程。那么,如果让你来设计一个降低大模型训练成本的方案,除了优化分布式训练算法之外,你还会考虑哪些方面?
3、UniAP 算法适配了国产 AI 计算卡,你认为这对于国产 AI 产业的发展有什么意义?
原文内容

训练成本高昂已经成为大模型和人工智能可持续发展的主要障碍之一。
大模型的训练往往采用多机多卡的分布式训练,大模型的分布式训练挑战巨大,即使硬件足够,不熟悉分布式训练的人大概率(实验中验证有 64%-87% 的概率)会因为超参数设置(模型怎么切分和排布、数据怎么切分和排布等)不合理而无法成功运行训练过程。
此外,不熟悉分布式训练的人在碰到大模型训练慢时容易只想到增加 GPU 硬件等横向拓展(scale-out)方法,而忽略了分布式训练算法的纵向拓展(scale-up)作用。
实际上,分布式训练算法会极大地影响硬件的算力利用率。高效能分布式训练算法具有高算力利用率。用同样的硬件算力训练同一个模型,高效能分布式训练算法会比低效能分布式训练算法速度快,最高可能会快数倍甚至数十倍以上。
也就是说,训练同一个模型,高效能分布式训练算法会比低效能分布式训练算法成本低,最高可能会节省数倍甚至数十倍以上的算力成本。很多已有的分布式训练算法的效能较低,甚至可能导致机器和 GPU 卡越多、训练速度越慢的结果。
南京大学计算机学院李武军教授课题组研发了高效能分布式训练算法 UniAP,并基于 UniAP 研发了相应的大模型分布式训练平台和框架。

-
论文标题:UniAP: Unifying Inter- and Intra-Layer Automatic Parallelism by Mixed Integer Quadratic Programming
-
论文地址:https://arxiv.org/abs/2307.16375
UniAP 是首个能实现层内并行策略(张量并行等)和层间并行策略(流水线并行等)联合优化的工作。给定模型和硬件平台,UniAP 能够通过自动搜索找到高效能的分布式训练方案,既解决了效率和成本问题(实验中,比已有的最好方法最高快 3.8 倍,比不采用并行策略优化的算法最高快 9 倍),也解决了很多人在大模型分布式训练时因为超参数设置(模型怎么切分和排布、数据怎么切分和排布等)不合理而无法成功运行训练过程的问题,即易用性问题。
此外,还实现了 UniAP 跟国产 AI 计算卡的适配。相关工作为大模型训练的降本增效提供了核心技术、(国产)平台和框架。
论文被 CVPR 2025 录用为 Oral(所有投稿论文的 0.7%,所有录用论文的 3.3%)。
-
层内并行策略:仅切分模型的层内张量,包括以数据并行、张量并行、全分片数据并行等为代表的并行策略;
-
层间并行策略:仅切分模型的层为多个互斥子集,包括流水线并行等并行策略。
基于已有的并行策略,大量的研究工作集中于并行方法的设计。这些并行方法可以按照是否需要用户手动指定并行策略划分为两类:手动并行方法和自动并行方法。传统的手动并行方法不仅耗时耗力,而且难以适应复杂的硬件环境。
而现有的自动并行方法存在的问题是它们要么只考虑层内或层间两类并行策略中的一类并行策略,要么把两类并行策略做分阶段优化而不是联合优化,求解得到的并行策略的训练效率存在提升空间。
UniAP 使用混合整数二次规划进行建模,实现对层内与层间并行策略的联合优化。这种联合优化使得 UniAP 有更大的策略探索空间。
UniAP 的架构图如下:
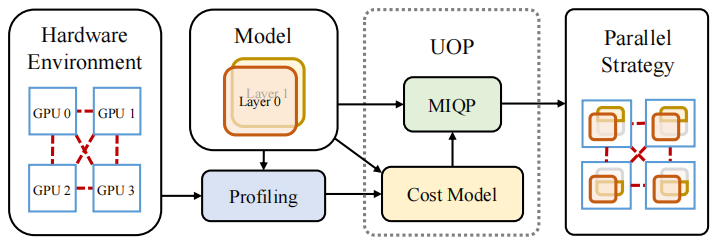
UniAP 首先对硬件和模型进行性能评估。然后,UniAP 会根据性能评估的结果和模型的计算图构建代价模型。根据代价模型和模型的计算图,UniAP 将优化问题建模为一个混合整数二次规划问题并进行优化。最后,UniAP 会将优化结果由向量转化成以计算图形式表达的并行计划,交由已有深度学习平台(如 PyTorch)进行训练。
性能评估和代价模型
因为自动并行框架要求在执行分布式训练前优化并行策略,所以框架需要对分布式训练的性能和开销进行模拟,再在模拟的结果上进行优化。
因此,对环境和任务进行性能评估是自动并行框架的重要组成部分。具体地,在性能评估部分,UniAP 将收集硬件和模型的性能信息,如 P2P 通信效率、All-Reduce 集合通信效率、模型每一层的前向计算的时间开销和显存开销等。
出于时间效率考虑,一个自动并行框架只能完成有限的性能评估任务,然后根据性能评估的结果构建代价模型。UniAP 的代价模型分为时间代价模型和显存代价模型。前者用于估计模型采用不同并行策略的时间开销,包括计算时间开销和通信时间开销;后者用于估计模型采用不同并行策略的显存占用开销。
混合整数二次规划形式
UniAP 的混合整数二次规划的目标是设定并行策略,使得训练中每次迭代所消耗的时间(Time-Per-Iteration,简称 TPI)最小化。
设模型的计算图为 ![]() 。层间并行策略可以由流水线的度 pp_size、流水线的微批量数量 𝑐,计算图的层 𝑢 是否放置在第 𝑖 级流水线上的放置策略
。层间并行策略可以由流水线的度 pp_size、流水线的微批量数量 𝑐,计算图的层 𝑢 是否放置在第 𝑖 级流水线上的放置策略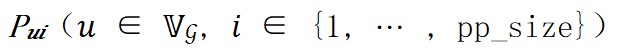 表示,
表示,![]() ;层内并行策略可以由层 𝑢 的层内并行策略集合
;层内并行策略可以由层 𝑢 的层内并行策略集合![]() 和层 𝑢 是否选择第 𝑘 个层内并行策略的
和层 𝑢 是否选择第 𝑘 个层内并行策略的![]() 表示,
表示,![]() 。
。
为方便描述,需要引入如下额外记号:对于一个给定的层![]() ,
,![]() 表示它的第 𝑘 个层内并行策略的前向传播和反向传播时间代价之和,
表示它的第 𝑘 个层内并行策略的前向传播和反向传播时间代价之和,![]() 代表了该层的第 𝑘 个层内并行策略在训练中占用的峰值显存量。对于一个给定的边
代表了该层的第 𝑘 个层内并行策略在训练中占用的峰值显存量。对于一个给定的边![]() ,如果该边的源点和终点位于同一个流水线的计算阶段中,那么它的通信代价为
,如果该边的源点和终点位于同一个流水线的计算阶段中,那么它的通信代价为![]() 。否则,如果该边的源点和终点位于不同流水线的计算阶段中,那么它的通信代价为
。否则,如果该边的源点和终点位于不同流水线的计算阶段中,那么它的通信代价为![]() 。此处,
。此处,![]() 均由 UniAP 的代价模型给定,在 UniAP 算法的优化过程中始终为常量。
均由 UniAP 的代价模型给定,在 UniAP 算法的优化过程中始终为常量。
流水线阶段内的时间开销:流水线某个阶段内部的时间开销由该流水线阶段每一层内部的时间开销和层间通信时间组成。记流水线的第 i 个阶段在一个微批量上的时间代价为![]() ,
,![]() 。可建立如下约束(原论文公式 3):
。可建立如下约束(原论文公式 3):
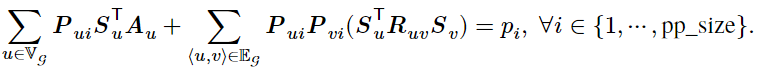
跨流水线阶段的时间开销:跨流水线阶段时间开销由通信开销组成。记跨第 i 个流水线阶段和第 i+1 个流水线阶段的时间开销为![]() ,
,![]() 。可建立如下约束(原论文公式 4):
。可建立如下约束(原论文公式 4):
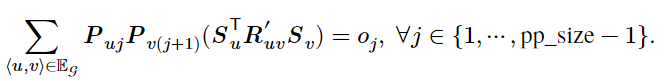
式中![]() 指示计算图中相邻的层 𝑢 和层 𝑣 是否放置在相邻的计算阶段上,
指示计算图中相邻的层 𝑢 和层 𝑣 是否放置在相邻的计算阶段上,![]() 则指示了层 𝑢 和层 𝑣 之间的通信代价。
则指示了层 𝑢 和层 𝑣 之间的通信代价。
目标函数:有了 和
和![]() ,就可以得到
,就可以得到![]() ,形式根据不同的流水线调度而有所不同,以 GPipe 调度为例,则目标函数为(原论文公式 2):
,形式根据不同的流水线调度而有所不同,以 GPipe 调度为例,则目标函数为(原论文公式 2):
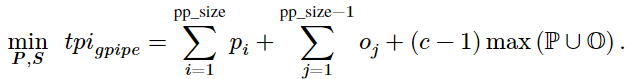
详细解释可见原文 3.3.1。
显存约束:因为分布式机器学习系统要求在训练深度学习模型时不能发生显存溢出(Out-of-Memory,简称 OOM)异常,所以 UniAP 为混合整数二次规划表达式引入显存约束。对于同构集群,因为所有工作设备均同构,所以它们的显存容量相同,记作 𝑚。UniAP 方法的显存约束如下(原论文公式 5):
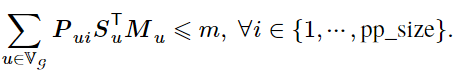
除显存约束外,还需要建立流水线保序约束、放置策略约束、策略选择约束。详情可见原论文。
统一优化过程
根据混合整数二次规划的表达式,现有的优化器可以直接解得给定流水线的度 pp_size 和微批量数量 𝑐 的情况下最优的并行策略组合。但因为 pp_size 和 c 是流水线并行的超参数,所以 UniAP 也需要统一优化这两个变量才能求得最优的并行策略组合。UniAP 通过枚举这两个变量来解决这个问题,算法伪代码如下(原文算法 1):

首先是在 NVIDIA GPU 上和其他自动并行方法(Galvatron 和 Alpa)的对比(原论文表 1):
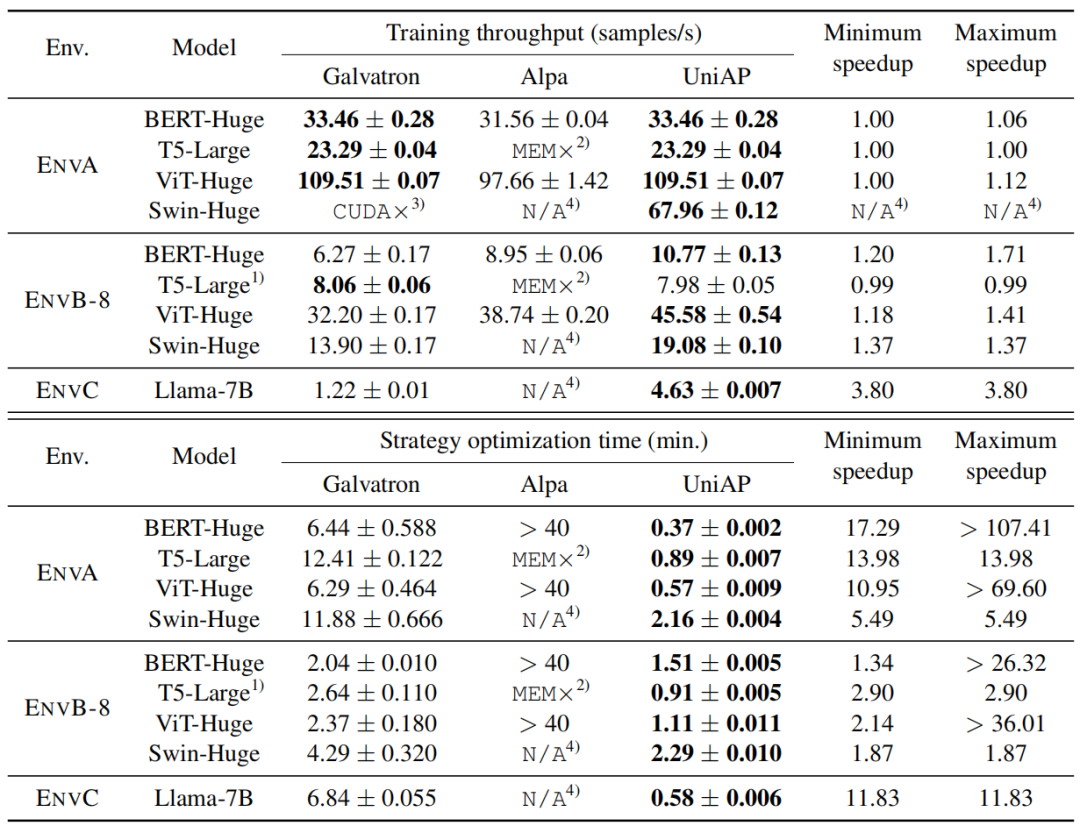
其中 ENVA 是一台 8 卡 V100,ENVB-8 是两台 4 卡 TITAN XP,ENVC 是一台 8 卡 A100。可以发现,在这 3 种硬件环境下,UniAP 的吞吐量均不差于两个 baseline,最大的提升达到 3.8 倍;而 UniAP 的策略优化时间更是远远小于两个 baseline,最大缩短 107 倍。
然后是在国产 AI 计算卡上和手动并行方法的对比。选取的 baseline 是国际主流的大模型训练框架 Megatron 和 DeepSpeed。两个框架中均有分布式训练的相关参数需要设置,实验中,枚举所有可能的设置,每个设置实际跑一定的轮次记录吞吐量,选取性能最好的做为吞吐量结果,选取整个过程的时间为策略优化时间。结果如下(原论文表 2):

其中硬件设置是 8 个 4 卡 DCU 节点。从表中可见,UniAP 找到了所有可行策略中的最优解,同时相较于手动暴力搜索,大大节约了策略优化时间。
在可拓展性方面,论文在最大 64 卡的集群上进行实验,验证了近线性拓展性(原论文图 5 和表 4):
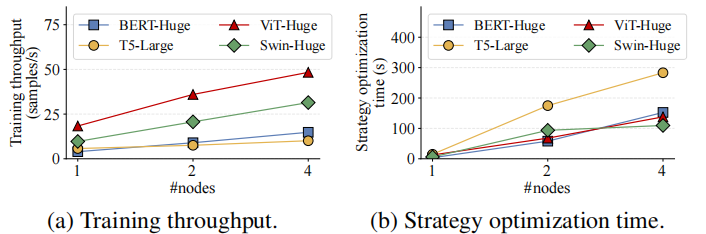
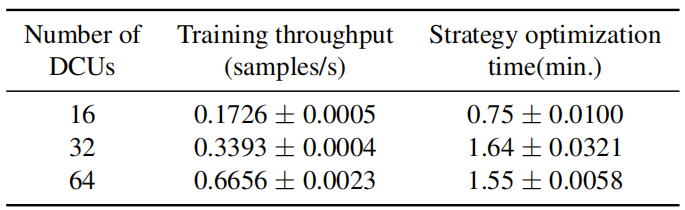
另外,论文还通过对实验中 Megatron 的策略空间的分析深度探讨了自动并行的必要性(原论文表 3):
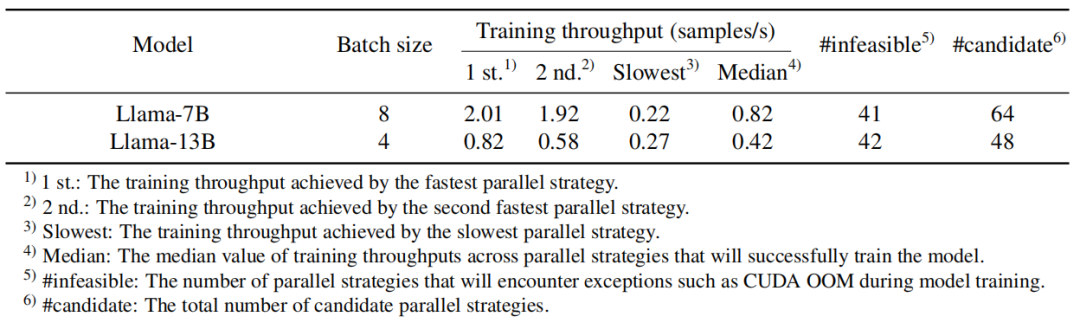
从表中可以看出,对于一个没有分布式训练经验的人来说,从所有支持的并行策略中随机选择一个,有 64.1%(41/64)到 87.5%(42/48)的概率会因为策略选择不合理而导致模型无法成功运行训练过程(出现显存溢出等);即使选择到了能成功运行训练过程的策略,最快的策略和最慢的策略间的速度最大相差了 2.01/0.22≈9 倍。更多讨论可见原文。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com