上海人工智能实验室等机构提出ReSo框架,通过奖励驱动和自组织演化机制,提升多智能体系统在复杂推理任务中的协作效率和推理能力。
原文标题:基于奖励驱动和自组织演化机制,全新框架ReSo重塑复杂推理任务中的智能协作
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 ReSo 框架在 Math-MAS-Hard 和 SciBench-MAS-Hard 数据集上表现出色,但在其他数据集上的表现如何?这种框架在其他类型的复杂推理任务,例如代码生成、文本摘要等方面是否具有潜力?
3、ReSo 框架中动态智能体数据库(DADB)的设计,是如何平衡智能体的探索(少被用过的智能体)与利用(高评分智能体)的?在实际应用中,如何避免 DADB 中的智能体出现“马太效应”,即强者越强,弱者越弱?
原文内容

本文由上海人工智能实验室,悉尼大学,牛津大学联合完成。第一作者周恒为上海 ailab 实习生和 Independent Researcher 耿鹤嘉。通讯作者为上海人工智能实验室青年科学家白磊和牛津大学访问学者,悉尼大学博士生尹榛菲,团队其他成员还有 ailab 实习生薛翔元。
ReSo 框架(Reward-driven & Self-organizing)为复杂推理任务中的多智能体系统(MAS)提供了全新解法,在处理复杂任务时,先分解生成任务图,再为每个子任务匹配最佳 agent。将任务图生成与奖励驱动的两阶段智能体选择过程相结合,该方法不仅提升了多智能体协作的效率,还为增强多智能体的推理能力开辟了新路径。

-
论文标题:ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
-
论文链接:https://arxiv.org/abs/2503.02390
-
代码地址:https://github.com/hengzzzhou/ReSo
研究背景:LLM 推理能力的掣肘与突破口
近年来,增加推理时间(Inference Time Scaling)被广泛认为是提升大语言模型(Large Language Models, LLMs)推理能力的重要途径之一。一方面,通过在训练后阶段引入强化学习与奖励模型,可优化单一模型的推理路径,使其在回答前生成中间步骤,表现出更强的逻辑链构建能力;另一方面,也有研究尝试构建多智能体系统(Multi-Agent Systems, MAS),借助多个基座模型或智能体的协同工作来解决单次推理难以完成的复杂任务。
相较于单模型的推理时间扩展,多智能体方法在理论上更具灵活性与可扩展性,但在实际应用中仍面临诸多挑战:
(1)多数 MAS 依赖人工设计与配置,缺乏自动扩展与适应性的能力;
(2)通常假设所有智能体能力已知,然而 LLM 作为 “黑箱式” 的通用模型,在实际任务中往往难以预先评估其能力边界;
(3)现有 MAS 中的奖励信号设计较为粗糙,仅依赖结果反馈或自我评估,难以有效驱动优化过程;
(4)缺乏基于数据反馈的动态演化机制,限制了 MAS 系统在大规模任务中的表现与泛化能力。
上述限制提出了一个核心问题:能否构建一种具备自组织能力的多智能体系统,使其能够通过奖励信号直接从数据中学习协作策略,而无需大量人工干预?
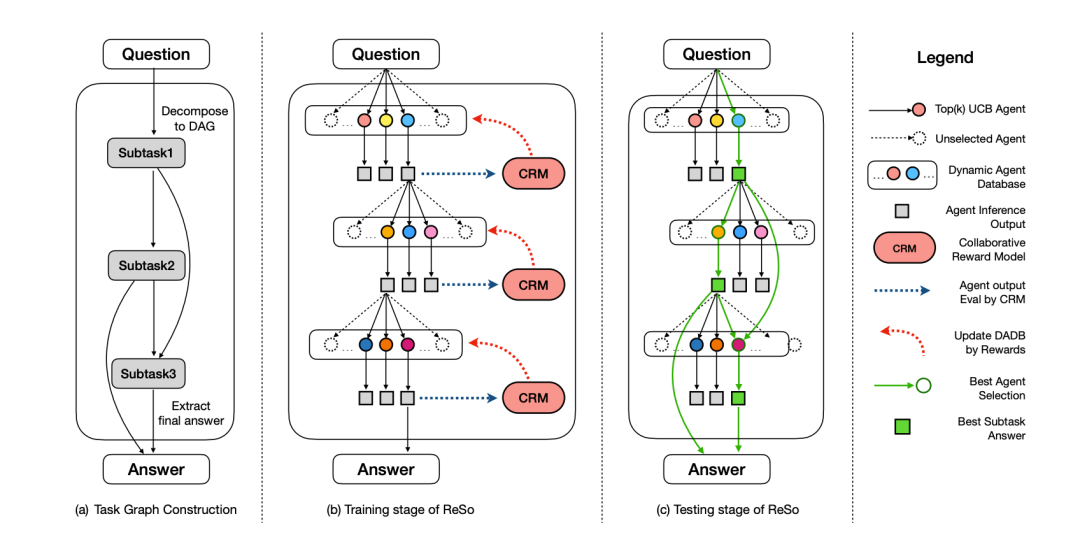
为应对这一挑战,作者提出了 ReSo—— 一个基于奖励驱动、自组织演化机制的多智能体系统架构。该方法通过引入协同奖励模型(Collaborative Reward Model, CRM),在任务图生成与智能体图构建之间建立反馈闭环,从而实现基于细粒度奖励的智能体动态优化与协作演化。与现有多智能体方案相比,ReSo 在可扩展性与优化能力上均具优势,并在多项复杂推理任务上达到了领先性能。
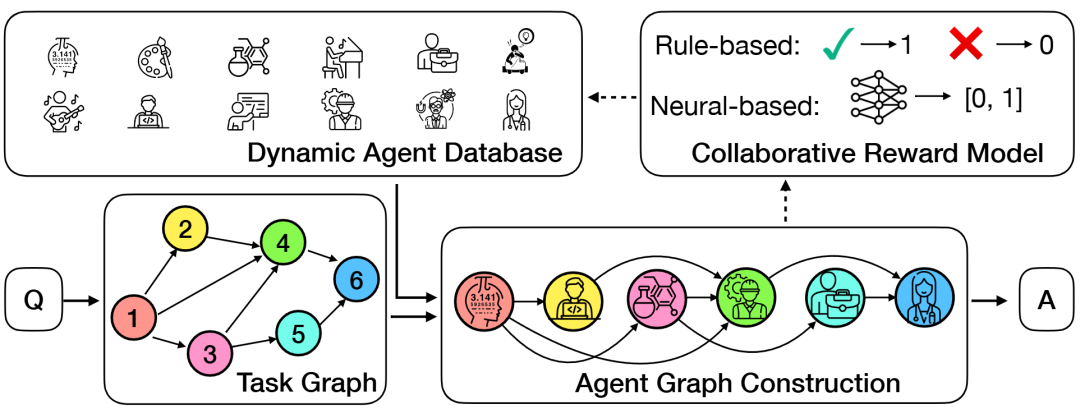
ReSo 框架流程图
ReSo 框架:Task Graph + Agent Graph,重塑 MAS 推理能力
具体来说,作者提出了两项核心创新:(1) ReSo,一个奖励驱动的自组织 MAS,能够自主适应复杂任务和灵活数量的智能体候选,无需手动设计合作解决方案。(2) 引入协作奖励模型 (CRM),专门用于优化 MAS 性能。CRM 可以在多智能体协作中提供细粒度的奖励信号,从而实现数据驱动的 MAS 性能优化。
1. 问题定义
对于一个解决任意问题 Q 的多智能体任务,作者将其定义为如下算法:
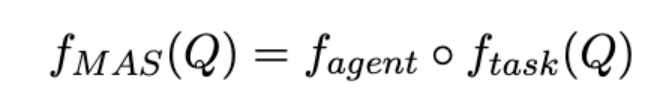
其中 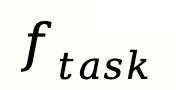 负责根据输入问题构建任务分解图,确保将问题结构化地分解为子任务及其依赖关系。
负责根据输入问题构建任务分解图,确保将问题结构化地分解为子任务及其依赖关系。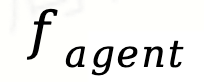 则动态地选择并分配合适的代理来解决已识别的子任务。这种模块化设计使得每个组件能够独立优化,从而实现更高的灵活性和可扩展性。
则动态地选择并分配合适的代理来解决已识别的子任务。这种模块化设计使得每个组件能够独立优化,从而实现更高的灵活性和可扩展性。
2. 任务图生成:明确子任务和依赖关系
ReSo 首先使用一个大语言模型将复杂问题分解,转化为分步骤的有向无环任务图 (DAG Task Graph),为后续智能体分配提供基础。
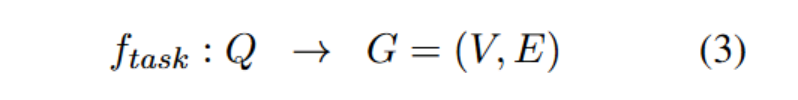
在实践中,对于任务分解,作者既测试了了已有的闭源模型(如 gpt4o),也在开源 LLM (如 Qwen-7b) 上进行监督微调 (SFT) 来执行更专业的任务分解。为了微调开源 LLM,作者构建了合成数据(见后文数据贡献章节),明确要求 LLM 将 Q 分解为逻辑子问题,指定它们的执行顺序和依赖关系,并以 DAG 格式输出。
3. 两阶段智能体选择:从粗到细,精挑细选
一旦获得任务图,作者就需要将每个子任务分配给最合适的代理。作者将此代理分配过程表示为 。从概念上讲,会根据大型代理池 A 中最合适的代理对任务图中的每个节点进行分类,从而构建一个代理图,将每个节点映射到一个或多个选定的代理。
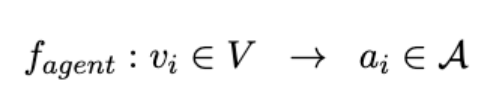
具体来说,作者提出了动态智能体数据库(DADB)作为 Agent 选择的代理池:通过构建一个动态数据库,存储智能体的基本信息、历史性能及计算成本,以供未来生成初步质量评分。
在 DADB 的基础上,对于使智能体选择算法具有可扩展性、可优化性,作者提出了两阶段的搜索算法:
-
粗粒度搜索(UCB 算法):利用上置信界(UCB)算法筛选候选智能体。
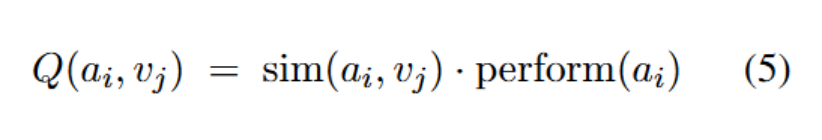
给定 DADB A 和一个子任务 vj,作者希望首先从所有智能体中筛选出一批有潜力的候选智能体(数量为 k)。
为此,作者采用了经典的上置信界(UCB)策略,该策略兼顾 “探索” 和 “利用” 的平衡:
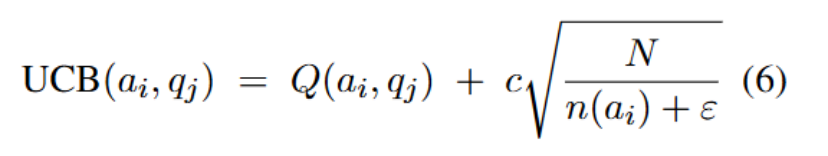
其中:Q ():DADB 给出的预评分,N:系统到目前为止分配过的智能体总数,n (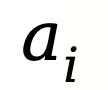 ):智能体被选中的次数,ε≪1:防止除以 0 的微小常数,c:超参数,控制探索(少被用过的智能体)与利用(高评分智能体)之间的平衡。
):智能体被选中的次数,ε≪1:防止除以 0 的微小常数,c:超参数,控制探索(少被用过的智能体)与利用(高评分智能体)之间的平衡。
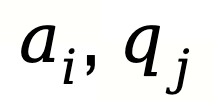
最后,作者按 UCB 分数对所有智能体排序,选择前 k 个作为当前子任务的候选集: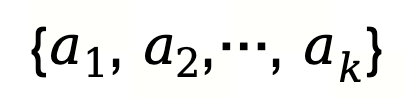
-
细粒度筛选(协作奖励模型 CRM):通过协作奖励模型对候选智能体进行细粒度评估,最终选择最优智能体。
在完成粗粒度筛选、选出了候选智能体集合之后,作者需要进一步评估这些智能体在当前子任务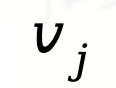 上的实际表现。这一步是通过一个协同奖励模型(Collaborative Reward Model, CRM) 来完成的。
上的实际表现。这一步是通过一个协同奖励模型(Collaborative Reward Model, CRM) 来完成的。
这个评估过程很直接:
每个候选智能体 ai 对子任务生成一个答案,记作 ();
然后作者通过奖励模型来评估这个答案的质量,得到奖励值 r (, ):
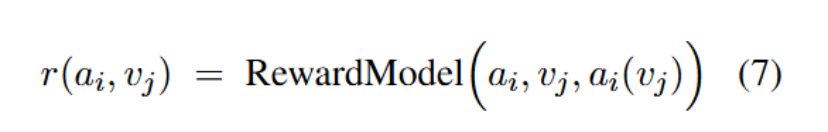
其中 RewardModel 会综合考虑以下因素来打分:
A. 当前智能体的角色与设定(即其 static profile);
B. 子任务的目标;
C. 以及该智能体在先前的推理过程中的上下文。
在所有候选智能体被评估后,作者将奖励值最高的智能体 a 分配给子任务,并将其生成的答案作为该子任务的最终解。这个评估与分配过程会对任务图中的每一个子任务节点重复进行,直到整张图完成分配。
1. 从训练到推理:动态优化与高效推理
-
训练阶段:利用 CRM 奖励信号动态更新 DADB,实现自适应优化。
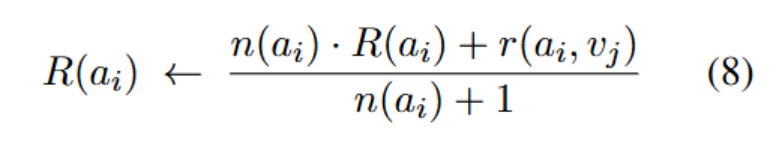
其中:R () 表示当前该智能体的平均奖励;n () 是它至今参与的任务次数;r (, ) 是它在当前子任务中的奖励。
类似地,作者也可以用同样的方式更新该智能体的执行开销(例如运行时间、资源消耗等),记作 c (, )。
通过不断迭代地学习和更新,DADB 能够动态地根据历史数据评估各个智能体,从而实现自适应的智能体选择机制,提升系统的整体性能和效率。
-
推理阶段:在测试阶段,作者不再需要奖励模型。此时,作者直接使用已经训练好的 DADB,从中选择最优的智能体候选者,并为每个子任务挑选最优解。
2. 从 MCTS 视角看 ReSo:降低复杂度,提升扩展性
任务图经过拓扑排序后,形成一棵决策树,其中每个节点代表一个子任务,边表示依赖关系。在每一层,作者使用 UCB 修剪树并选择一组有潜力的智能体,然后模拟每个智能体并使用 CRM 评估其性能。由此产生的奖励会更新智能体的动态配置文件,从而优化选择策略。MAS 的构建本质上是寻找从根到叶的最佳路径,最大化 UCB 奖励以获得最佳性能。
数据集生成:Mas-Dataset
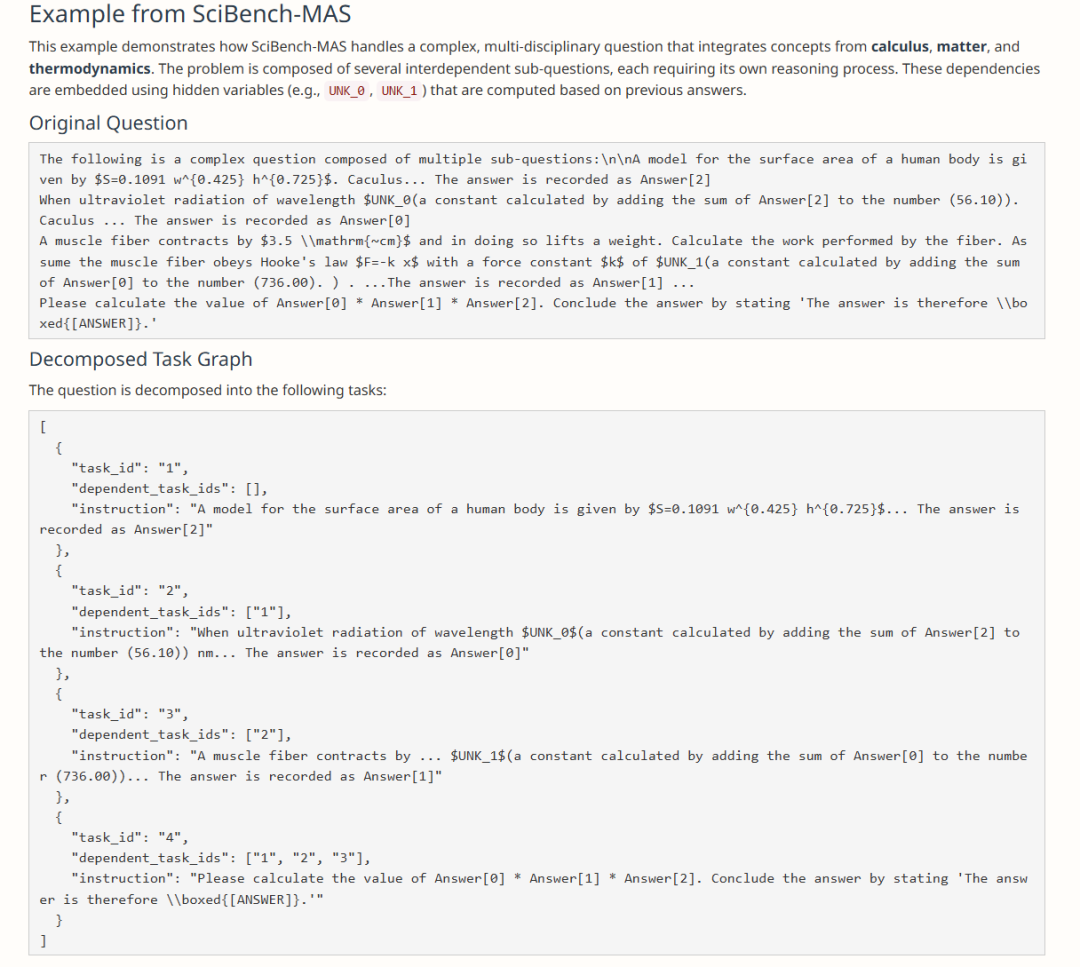
由于缺乏高质量的 MAS 数据集,作者提出了一种自动化方法来生成多智能体任务数据。这个过程包括随机生成任务图、填充子任务以及构建自然语言依赖关系。提出了一个单个 sample 就具有多学科任务的数据集。开源了数据合成脚本论文合成了 MATH-MAS 和 Scibench-MAS 数据集,复杂度有3,5,7。复杂度为 7 的意思为,单个题目中由7个子问题组成,他们来自不同的领域(数学,物理,化学)。子问题之间有依赖关系,评测模型处理复杂问题的能力。下图是个 Scibench-MAS 复杂度为 3 的例子:
实验结果
主要结果
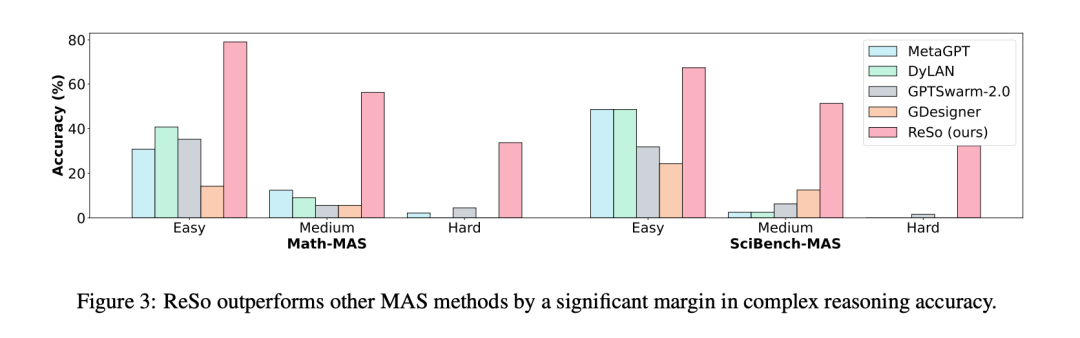
表 1 的实验结果实验表明,ReSo 在效果上匹敌或超越现有方法。ReSo 在 Math-MAS-Hard 和 SciBench-MAS-Hard 上的准确率分别达到 33.7% 和 32.3% ,而其他方法则完全失效。图 3 显示,在复杂推理任务中,ReSo 的表现全面优于现有 MAS 方法,展现了其卓越的性能和强大的适应性。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com