清华朱军团队提出DBIM算法,无需额外训练即可加速扩散桥模型推理20倍,显著提升图像翻译和修复效率。
原文标题:ICLR 2025 | 无需训练加速20倍,清华朱军组提出用于图像翻译的扩散桥模型推理算法DBIM
原文作者:机器之心
冷月清谈:
怜星夜思:
2、DBIM中提到的“启动噪声”(booting noise)机制是为了解决确定性采样过程中的初始奇异性问题,那么除了这种方式,还有没有其他方法可以避免或缓解这个问题?
3、文章实验部分,DBIM在ImageNet图像修复任务中取得了很好的效果,那么这项技术在实际的图像处理领域有哪些潜在的应用场景?除了图像修复,还能应用到哪些其他领域?
原文内容

论文有两位共同一作。郑凯文为清华大学计算机系三年级博士生,何冠德为德州大学奥斯汀分校(UT Austin)一年级博士生。
扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。

为了解决这一问题,一种名为去噪扩散桥模型(Denoising Diffusion Bridge Models, DDBMs)的变种应运而生。DDBM 能够建模两个给定分布之间的桥接过程,从而很好地应用于图像翻译、图像修复等任务。然而,这类模型在数学形式上依赖复杂的常微分方程 / 随机微分方程,在生成高分辨率图像时通常需要数百步的迭代,计算效率低下,严重限制了其在实际中的广泛应用。
相比于标准扩散模型,扩散桥模型的推理过程额外涉及初始条件相关的线性组合和起始点的奇异性,无法直接应用标准扩散模型的推理算法。为此,清华大学朱军团队提出了一种名为扩散桥隐式模型(DBIM)的算法,无需额外训练即可显著加速扩散桥模型的推理。

-
论文标题:Diffusion Bridge Implicit Models
-
论文链接:https://arxiv.org/abs/2405.15885
-
代码仓库:https://github.com/thu-ml/DiffusionBridge
方法介绍
DBIM 的核心思想是对扩散桥模型进行推广,提出了一类非马尔科夫扩散桥(non-Markovian Diffusion Bridges)。这种新的桥接过程不仅与原来的 DDBM 拥有相同的边缘分布与训练目标,而且能够通过减少随机性,实现从随机到确定性的灵活可控的采样过程。
具体而言,DBIM 在模型推理过程中引入了一个方差控制参数 ρ,使得生成过程能够在随机采样与确定性采样之间自由切换。当完全采用确定性推理模式时,DBIM 能够直接以隐式的形式表示生成过程。这种思想是标准扩散模型的著名推理算法 DDIM 在扩散桥模型上的推广与拓展。
更进一步,DBIM 算法可以导出扩散桥的一种全新的常微分方程(ODE)表达形式,相较于 DDBM 论文中的常微分方程形式更加简洁有效。

在此基础上,作者首次提出了针对扩散桥模型的高阶数值求解方法,进一步提升了推理的精度与效率。

此外,为了避免确定性采样过程中出现的初始奇异性问题,作者提出了一种「启动噪声」(booting noise)机制,即仅在初始步骤中加入适当随机噪声,从而保证了模型的生成多样性,并同时保留了对数据的编码与语义插值能力。
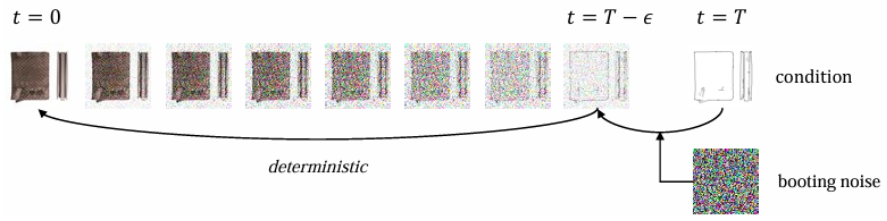
实验结果
作者在经典的图像翻译和图像修复任务上进行了如下实验:
-
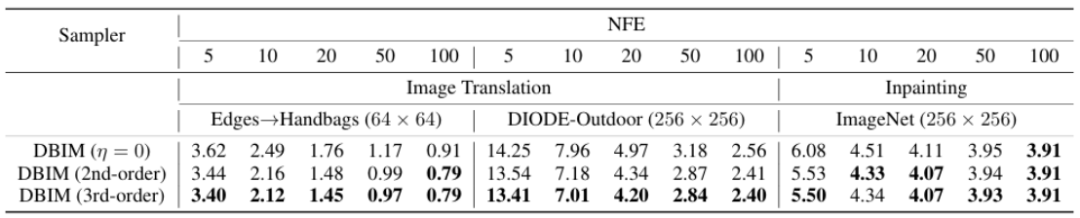
在 Edges→Handbags(64×64)和 DIODE-Outdoor(256×256)图像翻译任务中,DBIM 仅需 20 步推理即可达到甚至超越 DDBM 模型 118 步推理的生成质量。当推理步数增至 100 步时,DBIM 进一步提升生成质量,在更高分辨率任务上全面领先。
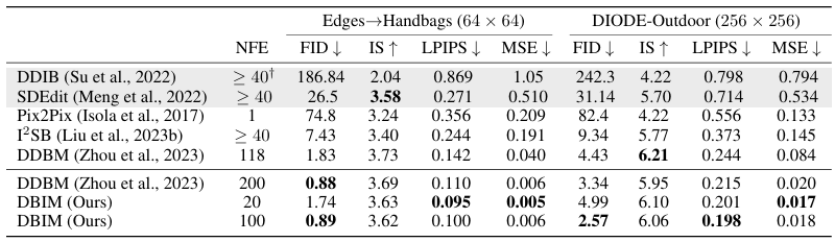
-
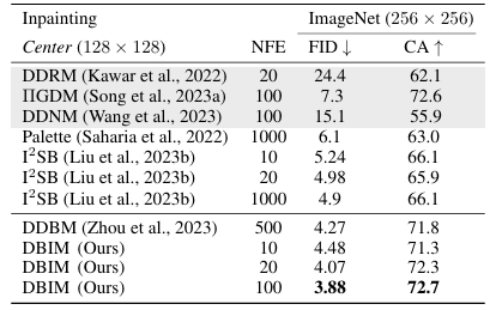
在更具挑战的 ImageNet 256×256 图像修复任务中,DBIM 仅需 20 步推理便显著超越了传统扩散桥模型 500 步推理的效果,实现了超过 25 倍的推理加速。在 100 步推理时,DBIM 进一步刷新了这一任务的 FID 记录。

通过参数 η 控制采样过程中的随机性大小,论文发现确定性采样模式在低步数时具备显著优势,而适当增加随机性能够在较高步数下进一步提升生成多样性与 FID 指标。这与标准扩散模型推理的性质相似。
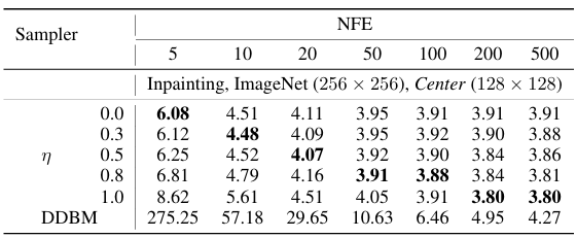
此外,高阶采样器能够在不同采样步数下一致提升生成质量,增强图像细节。
论文所用训练、推理代码及模型文件均已开源。如果你对 DBIM 感兴趣,想要深入了解它的技术细节和实验结果,可访问论文原文和 GitHub 仓库。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com