告别死记硬背!《图解算法和数据结构》用图解+代码带你高效学习算法,提升编程内功,建立自己的解题模型库!
原文标题:看图学算法,原来可以这么高效!
原文作者:图灵编辑部
冷月清谈:
怜星夜思:
2、书中提到了排序算法的重要性,也介绍了很多排序算法。在实际开发中,面对不同的数据规模和场景,我们应该如何选择合适的排序算法?有没有一套通用的“选择指南”?
3、书中将迪杰斯特拉算法可视化成“拉紧绳子的操作”,帮助理解算法逻辑。大家有没有其他类似的算法,可以用形象的比喻或者具象化的方式来帮助理解?
原文内容
程序员之间,拼的从来不是谁写得快,而是谁想得清楚!
但遗憾的是,我们很多人学编程,学语法、写项目,却很少有人系统地教过我们该怎么用算法,把一个实际问题解得更好、更快。
《图解算法和数据结构》这本书,正是从这个角度出发:不只是教你怎么写代码,而是让你学会用算法“思考和解决问题”。

这是一本“能想清楚 + 写得出”的算法书!
作者大槻兼资是来自 AtCoder 的资深竞赛选手,现就职于 NTT 数据数理系统公司。他写这本书的初衷并不是“再出一本算法教材”,而是把算法的思维方式和解题模型拆解给你看。
书中很多例题都来自 AtCoder 平台,内容以动手画图 + 推理过程 + C++ 代码实现为主轴,非常适合:
-
想从“写得出代码”走向“设计得出解法”的读者;
-
准备技术面试,想补齐算法功底的开发者;
-
正在准备算法竞赛、蓝桥杯、NOI 或者 AtCoder 的学生;
-
对 C++ STL 用法还不熟练的刷题党。
书中几个实用又印象深刻的例子!
一、迷宫寻路问题,理解广度优先搜索
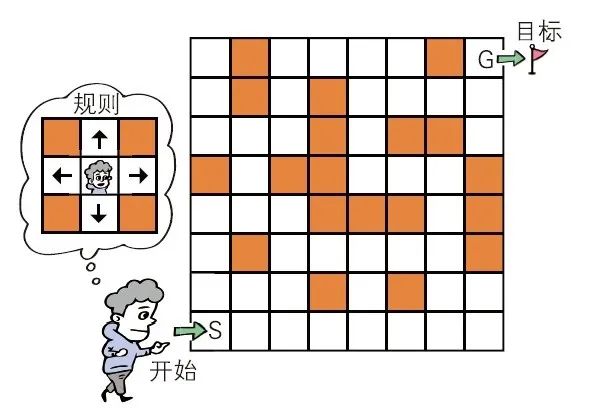
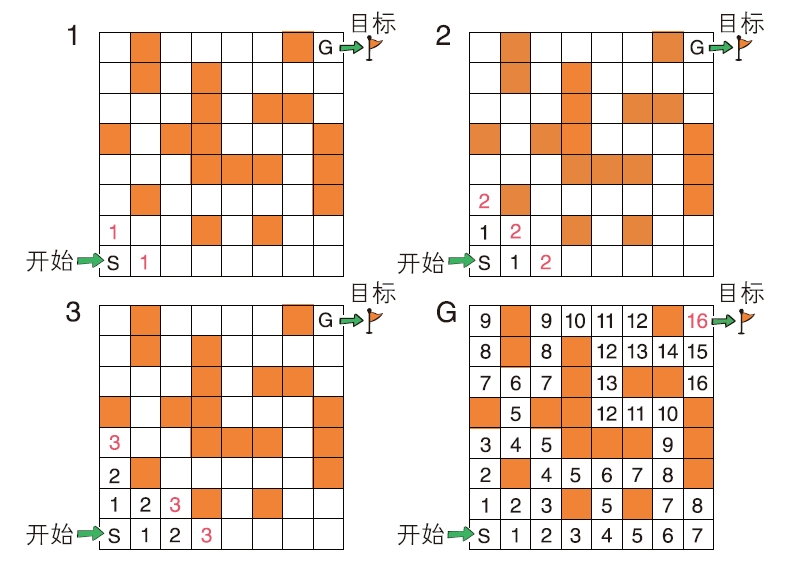
书里用这样一个“从迷宫入口走到出口”的例子作为切入,不只是讲算法流程,而是让你动手画图、观察节点状态、写出判断逻辑,把抽象算法变成可推演的现实过程。
二、排序不仅是基础,更是性能关键
排序常常被认为是“学过就会”的基础内容,它不仅在实际场景中应用广泛,还是学习分治法、堆等数据结构以及随机算法等各种算法技巧的重要基础。作者总结了各种排序算法的特点和区别,让读者重新认识排序的多样性与实用性。
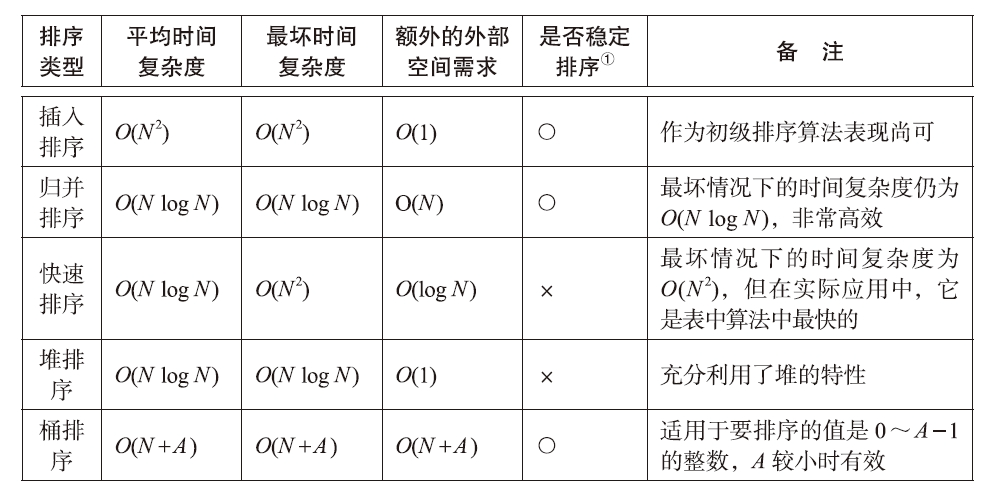
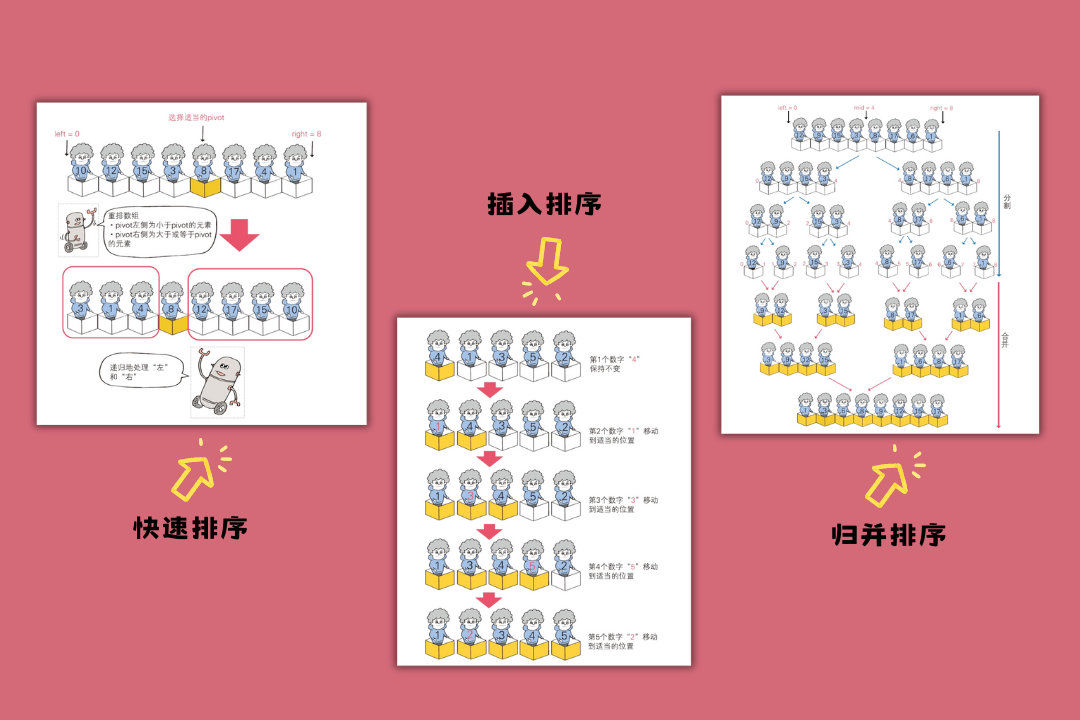
作者还将各种排序的步骤可视化出来,让人清晰明了!
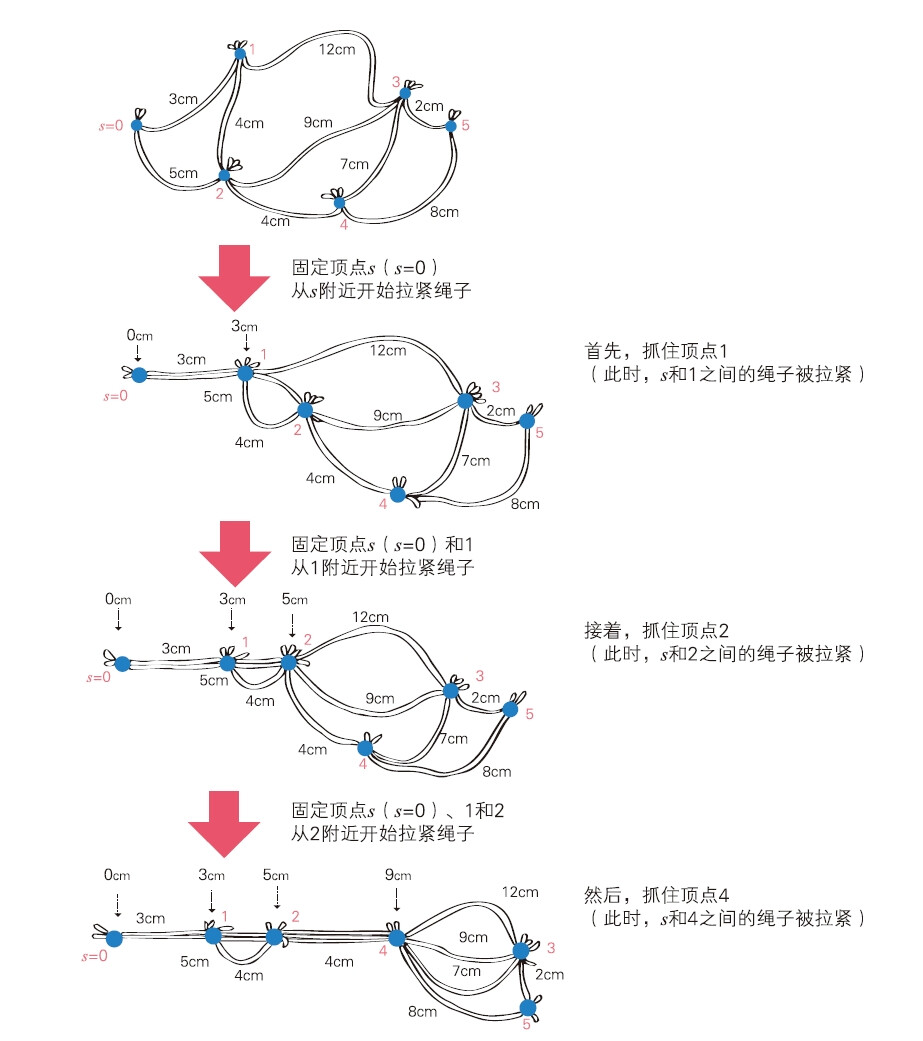
三、迪杰斯特拉算法
这部分作者将迪杰斯特拉算法的过程可视化成“拉紧绳子的操作”来思考。假设将顶点 s 固定,然后用右手捏住从 S 出发的绳子,慢慢地向右移动。
每个节点之间拉着一根绳子,从起点开始,你像是用手一根一根地把绳子往前拉,每次拉紧最近的节点。这个“拉绳子”的过程,正好对应了迪杰斯特拉算法的每一步。作者通过可视化,帮助读者跳出公式记忆,真正“理解”算法逻辑。
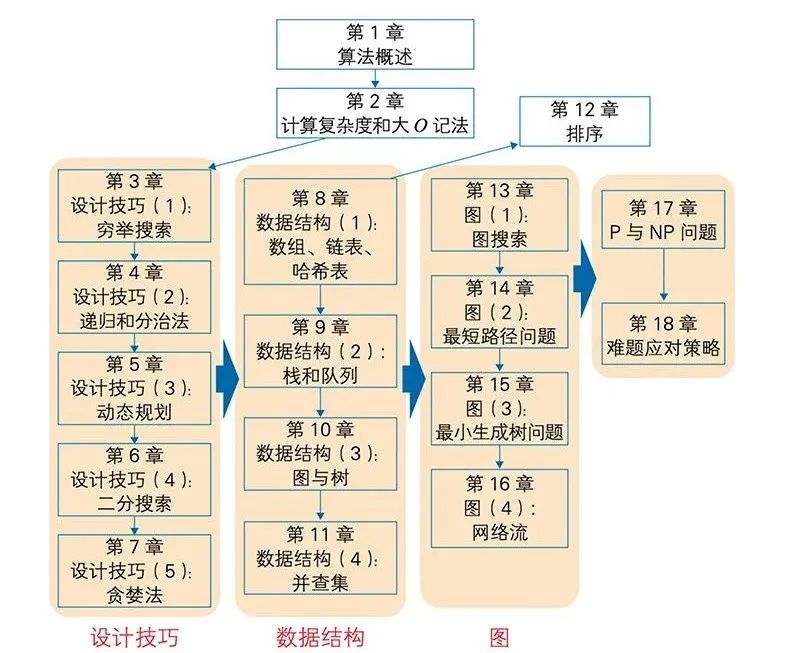
内容结构一目了然,进阶式设计非常合理
本书分成四大单元,共 18 章,内容由浅入深、理论与实践并重,每章后面还附带思考题,助你巩固所学:
1️⃣ 单元一(第1~2章):介绍算法和计算复杂度的基础概念;
2️⃣ 单元二(第3~7章):讲解五大算法设计技巧,包括递归、贪心、分治等;
3️⃣ 单元三(第8~12章):聚焦图、搜索、动态规划等经典算法内容;
4️⃣ 单元四(第13~18章):提这本书,适合你吗?阶段,包括图的高级算法、二分图、网络流等实战性强的专题。
作者简介
这本书,适合你吗?
如果你是:
最后的话
说一句实在的:“会算法,不一定让你一夜变强;但不会算法,很容易在关键时刻掉链子。”
《图解算法和数据结构》这本书没有虚头巴脑的修饰,不用讲“学了它你能变天才”,但它会真诚地带你把每一个核心算法讲清楚、写明白。
越早看,你就越快拥有自己的“解题模型库”。
推荐收藏,也值得反复翻看。👇