DeepCoder-14B-Preview开源!代码推理能力媲美 OpenAI o3-mini,附一键部署教程,快速体验高性能。
原文标题:在线教程丨媲美 o3-mini,开源代码推理模型 DeepCoder-14B-Preview 狂揽 3k stars
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到 DeepCoder-14B-Preview 使用了分布式强化学习来扩展上下文长度,这种方法有什么优势?
3、教程中推荐使用 RTX 4090 显卡和 vLLM 镜像,这对模型的性能有什么影响?
原文内容


目前「一键部署 DeepCoder-14B-Preview」教程已上线至 HyperAI超神经官网的教程板块中,模型克隆完成后进入「API 地址」即可快速体验模型!
近期,Agentica 团队携手 Together AI 联合开源了名为 DeepCoder-14B-Preview 的代码推理模型,这个仅需 14B 即可媲美 OpenAI o3-Mini 的新模型迅速引起业界广泛关注,在 GitHub 狂揽 3k stars。
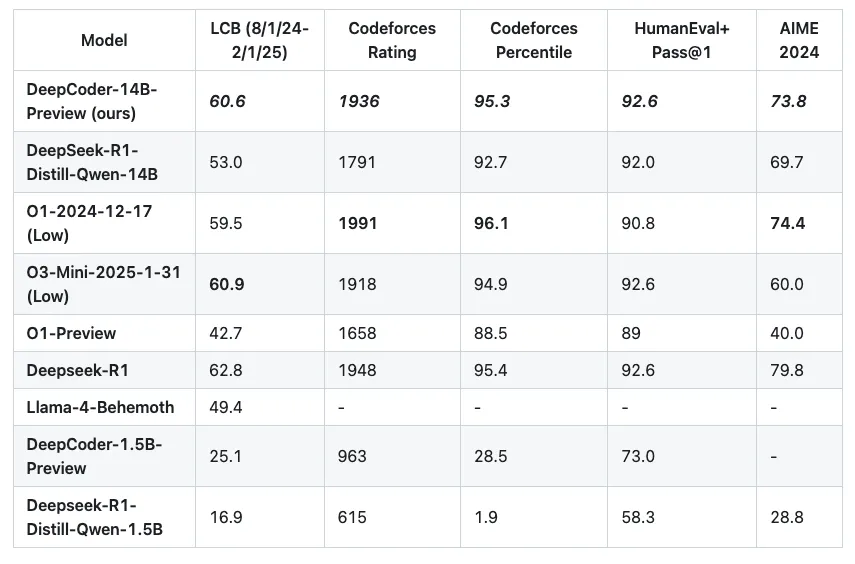
具体而言,DeepCoder-14B-Preview 是一款基于 DeepSeek-R1-Distilled-Qwen-14B 进行微调的代码推理 LLM,使用分布式强化学习 (RL) 扩展上下文长度。该模型在 LiveCodeBench v5 (8/1/24-2/1/25) 上实现了 60.6% 的单次通过率 (Pass@1),不仅超越了其基础模型,并且仅凭 140 亿参数就达到了与 OpenAI o3-mini 相当的性能。
目前「一键部署 DeepCoder-14B-Preview」教程已上线至 HyperAI超神经官网的教程板块中,模型克隆完成后进入「API 地址」即可快速体验模型!
Demo 运行
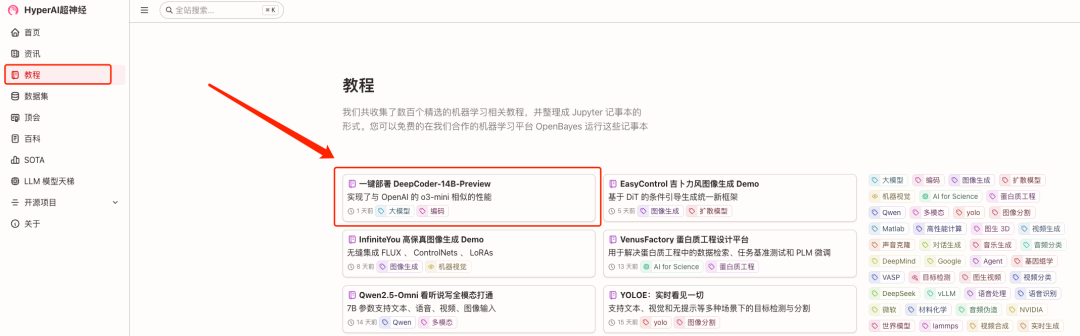
1. 登录 hyper.ai,在「教程」页面,选择「一键部署 DeepCoder-14B-Preview」,点击「在线运行此教程」。
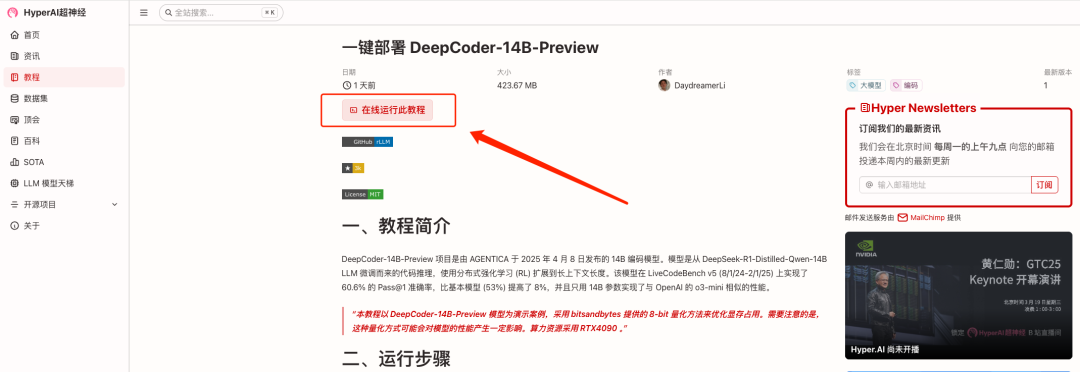
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
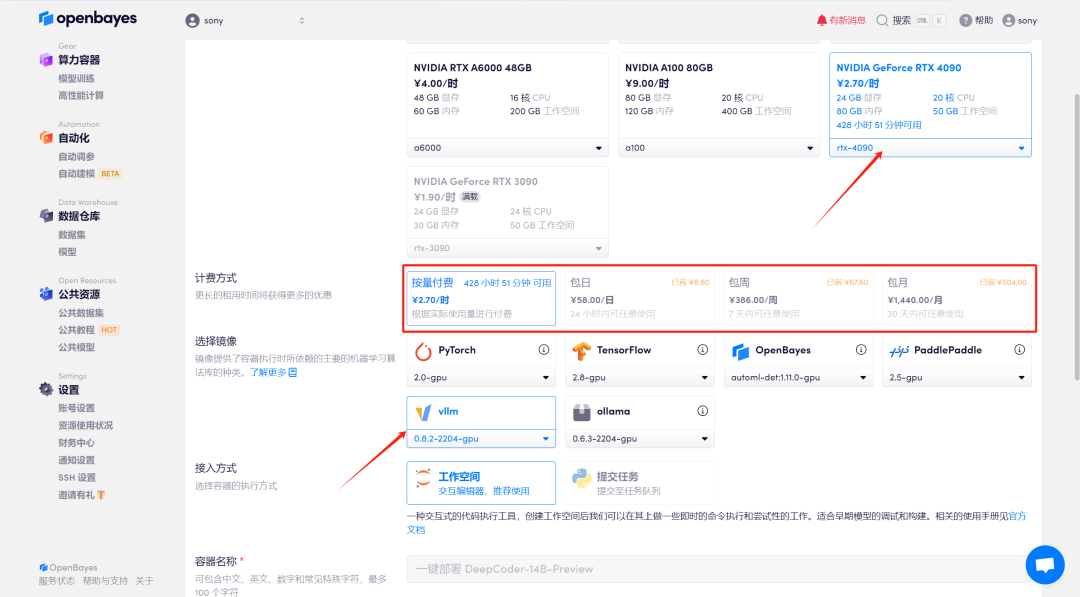
3.选择「NVIDIA GeForce RTX 4090」以及「vLLM」镜像,OpenBayes 平台提供了 4 种计费方式,大家可以按照需求选择「按量付费」或「包日/周/月」,点击「继续执行」。新用户使用下方邀请链接注册,可获得 4 小时 RTX 4090 + 5 小时 CPU 的免费时长!
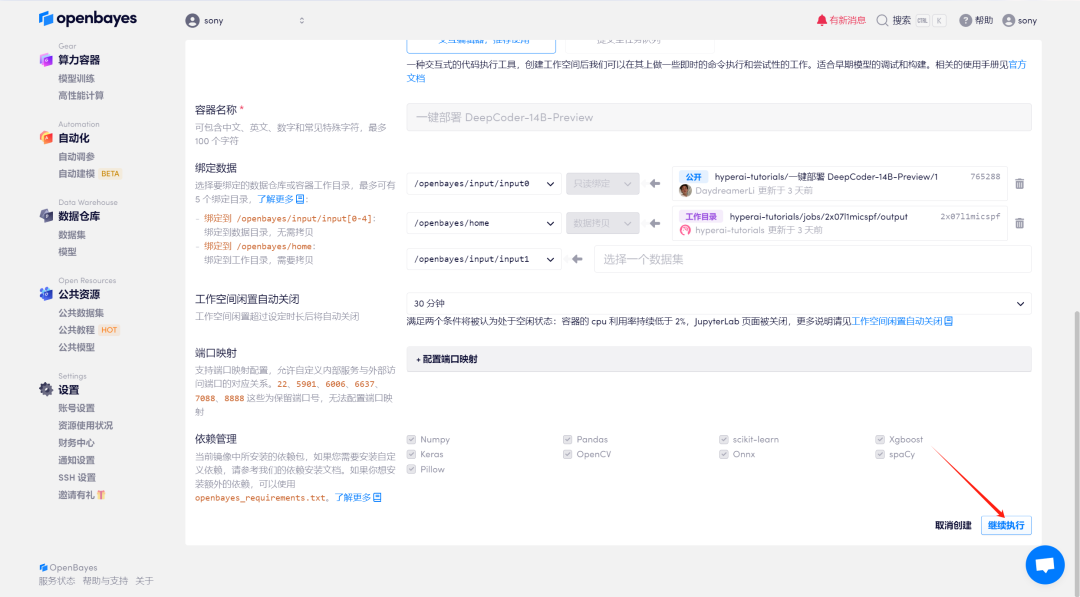
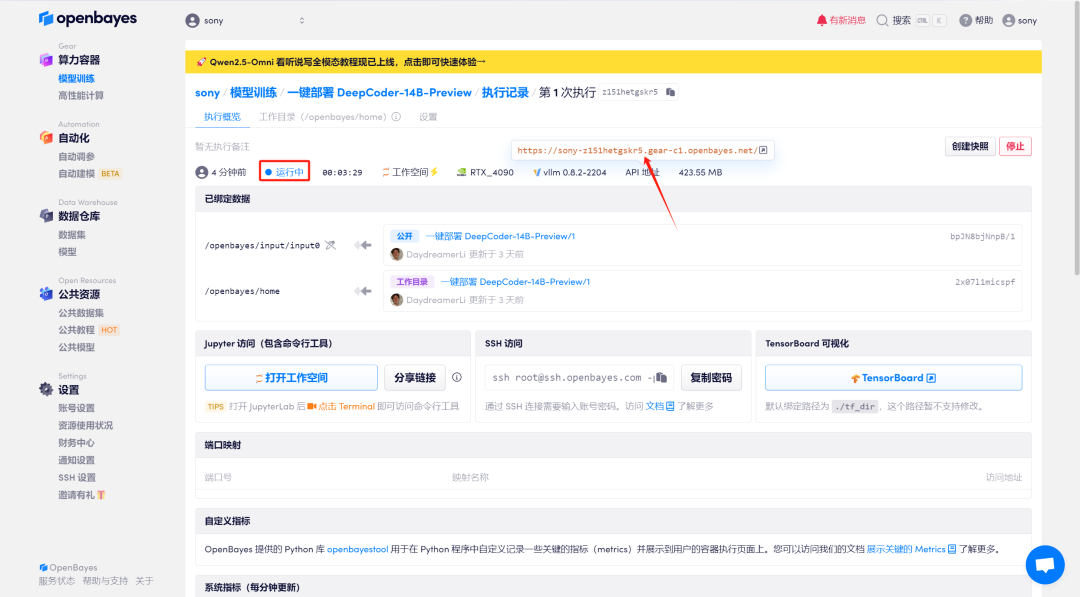
4.等待分配资源,首次克隆需等待 2 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。请注意,用户需在实名认证后才能使用 API 地址访问功能。
效果展示
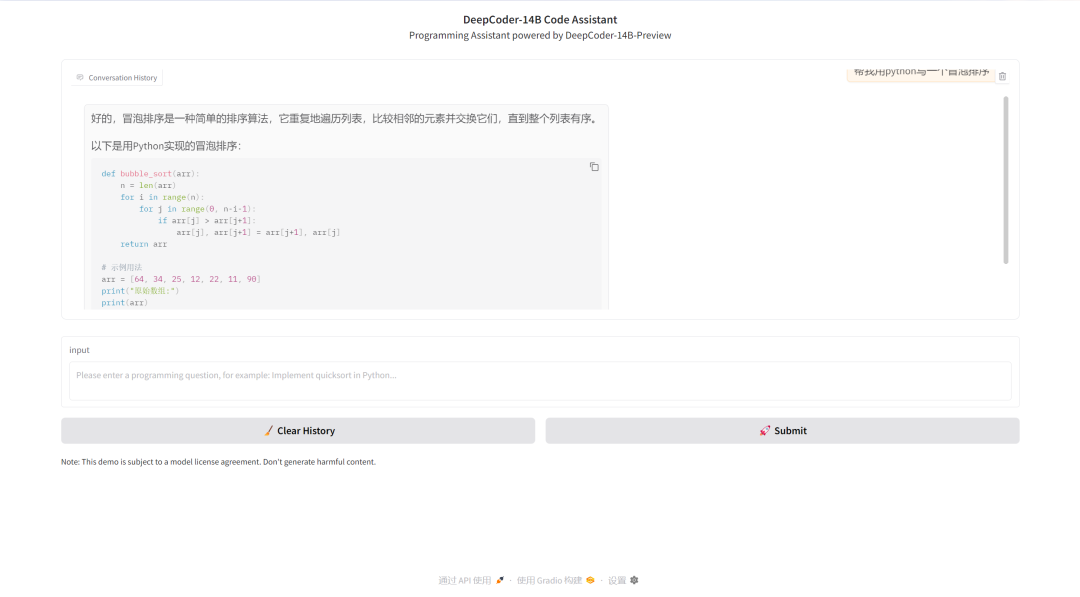
进入 Demo 页面后即可体验模型。本教程以 DeepCoder-14B-Preview 模型为演示案例,采用 bitsandbytes 提供的 8-bit 量化方法来优化显存占用。
在「input」栏中输入内容,点击「Submit」生成。点击「Clear History」可清除对话记录。
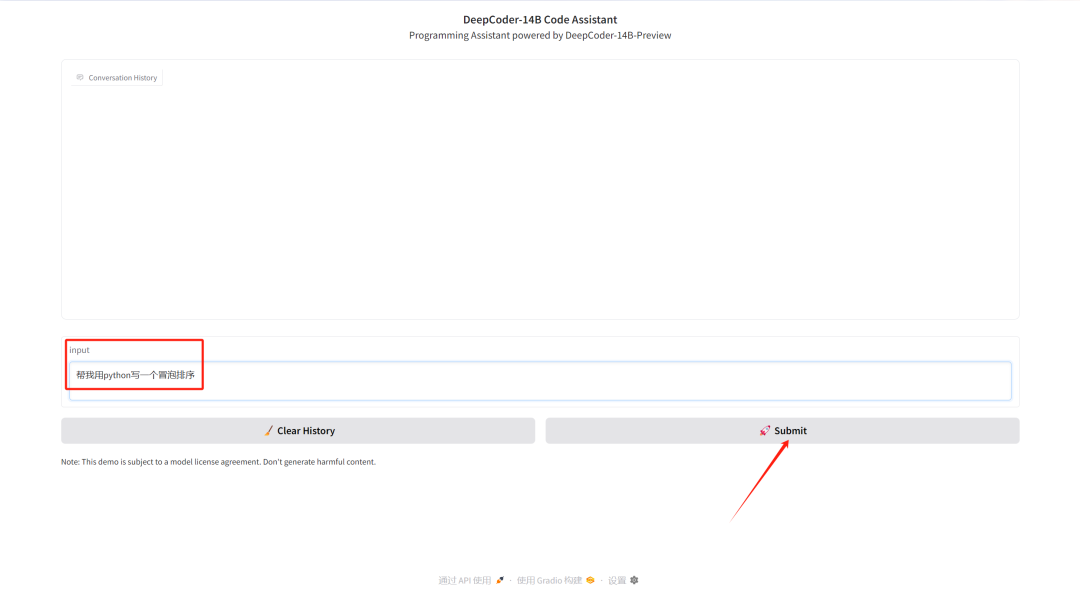
此处以经典的冒泡排序为例,可以看到模型很快地对问题做出了答复。