ICLR 2025 Oral 论文 ChartMoE 提出一种新颖的 MoE 训练方法,通过多样化对齐任务增强模型对图表的理解,同时缓解通用知识遗忘。
原文标题:ICLR 2025 Oral IDEA联合清华北大提出ChartMoE:探究下游任务中多样化对齐MoE的表征和知识
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到 MoE 结构本身就带有一定的正则作用,可以缓解下游领域模型在通用任务上遗忘。你认为除了文章中提到的原因外,还有哪些因素可能导致这种现象?
3、ChartMoE 在专家选择分布上,发现模型倾向于选择通用专家和最富含信息的 Code 专家。这说明了什么?对于未来的模型设计,你有什么启发?
原文内容

最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%

-
论文链接:
-
https://arxiv.org/abs/2409.03277
-
代码链接:
-
https://github.com/IDEA-FinAI/ChartMoE
-
模型链接:
-
https://huggingface.co/IDEA-FinAI/chartmoe
-
数据链接:https://huggingface.co/datasets/Coobiw/ChartMoE-Data
研究动机与主要贡献:
-
不同于现阶段使用 MoE 架构的原始动机,ChartMoE 的目标不是扩展模型的容量,而是探究 MoE 这种 Sparse 结构在下游任务上的应用,通过对齐任务来增强模型对图表的理解能力,同时保持在其他通用任务上的性能。
-
不同于之前依赖 ramdom 或 co-upcycle 初始化的方法,ChartMoE 利用多样的对齐任务进行专家初始化。这种方法加大了专家间的异质性,使 ChartMoE 可以学习到更全面的视觉表征,展现出显著的解释性。

ChartMoE 是一个以 InternLM-XComposer2 模型为训练起点、引入 MoE Connector 结构的多模态大语言模型,具有先进的图表理解、图表重绘、图表编辑、重要部分高亮、转换图表类型等能力。ChartMoE 为图表(Chart)这种独特于自然图像的输入,设计了多阶段的图文对齐方式,每一个阶段产物都是 MoE Connector 中的一个专家,这样的训练方式和模型设计不仅能获得更全面的视觉表征、显著提高 MLLM 的图表理解能力,还可以在不加入通用数据的情景下,减少模型对通用知识的遗忘。
多阶段对齐训练的 MoE


-
通用 MLLM,如 LLaVA,他们的 training recipe 通常分为两个阶段,第一个阶段使用图文对(image-text pair)训练 MLP Connector,第二阶段 SFT 训练 MLP Connector + LLM。
-
这种范式可以很自然的迁移到 Chart MLLM 中,如:ACL24 的 ChartAst,使用成对的 Chart-Table 进行第一阶段的图文对齐。
然而,Table 这种结构化文本格式,其中仅包含了每个数据点的数值,以及 xy 轴的含义等信息,几乎不保留视觉元素信息,如:颜色、图表类型、图形元素的相对关系等。所以,ChartMoE 希望采用更多样、更全面的对齐方式,将 Chart 转译成三种结构化文本格式:Table、JSON、Python Code。
我们以开源数据集(ChartQA、PlotQA、ChartY)中的表格数据作为起始点,为每个图表类型人为定义了 JSON 键,通过 random 生成、GPT 生成等方式为每个键填上对应的值,从而构建出 JSON 数据。此后可以将 JSON 中的键值对填入到每个图表类型预定义好的代码模板中得到 Python 代码来生成图表,从而构成 (Chart, Table, JSON, Code) 四元组,通过这种方式,采集了约 900k 数据,称为 ChartMoE-Align。

获取到数据后,ChartMoE 采用 chart-to-table、chart-to-json、chart-to-code 三种方式进行图文对齐,每个任务分别训练一个独立的 MLP Connector,拼上初始的通用 MLLM 中的 MLP Connector,再加上一个随机初始化的 learnable router,就可以构成一个亟待吃下 SFT 数据的 MoE Connector,即:Diversely Aligned MoE。


对比 Diversely Aligned MoE 与 Random 初始化、Co-Upcycle 初始化(即把通用 Connector 复制 N 份)的 Training Loss,我们发现,Diversely Aligned MoE 能够有更低的初始 loss(因为已经更好地学到了对齐到后续 LLM 的 chart 表征),以及整体更平滑的训练曲线。
Training Recipes
ChartMoE 训练分为三个阶段:
-
多阶段对齐(数据:ChartMoE-Align,Table 500k + JSON 200k + Code 100k),仅训练 MLP Connector,最后拼成 MoE Connector。
-
广泛学习高质量知识(使用 MMC-Instruct 数据集,包含很多 Chart 相关的任务,如:Chart Summarization),训练 MoE Connector(尤其是 Learnable Router,亟待学习)以及 LLM Lora。
-
Chart 领域 SFT(ChartQA + ChartGemma):训练 MoE Connector 以及 LLM Lora;
-
PoT(Program-of-Thought):即输出 python 代码来解决问题,可以让模型将计算交给代码,提高解题准确率,如:一个利润柱状图,问最高利润和最低利润差多少,就会输出代码:
-
profits = [5, 7, 9, 1, 11, -3] print (max (profits) - min (profits))
ChartMoE 表征可视化
按每个 Visual Patch Token 选择的专家序号进行可视化,观察 Visual Patch 的 Top-1 的专家选择分布:


-
背景 tokens 倾向于选择通用通用专家,也说明通用专家选择占比非常高。
-
数据点、图像元素、图像元素间的 interaction(如第一行第四列的 graph 图的 edges)非常倾向于选择 code 专家(尽管 chart-to-code 数据中并没有包含这种 graph 图表)。
-
标题、xy 轴标注、xy 轴刻度、图例等文本信息,倾向于选择 table/JSON 专家。
-
类似的现象也可以泛化到通用场景,尽管我们整个 training 中完全没有包含这样的数据。
ChartMoE 专家分布可视化
我们分析了完全让模型自由学习,不加入 MoE balance loss 下的专家选择分布,和上文所述符合,模型倾向于选择通用专家和最富含信息的 Code 专家 Random 初始化、Co-Upcycle 初始化、加入 balance loss 的 Diversely-Aligned 初始化,我们均有进行专家选择分布的分析,以及严格控制变量下的 ChartQA 性能比较:


尽管前三者都会获得更均衡的专家分布,但性能是不如完全不加 balance loss 自由学习 Divesely-Aligned MoE 的,可能是因为:
-
对于视觉信息,本就是分类不均衡的,信息相对少的背景 tokens 占全部视觉 tokens 的大多数。
-
balance loss 本身目的并非在于性能的提升,而是专家选择更均衡后,配合专家并行 (Expert Parallel) 技术,可以提高训练 / 推理的效率。
我们额外分析了最终的 ChartMoE checkpoint,强行固定选择某个专家的性能:

可以看到,和专家选择分布基本保持一致,模型自己最知道哪个专家能获得好性能了。
ChartMoE Performance(Chart & 通用)
这里想先 show 一下通用领域,因为 chart 领域的 sota 在进行了细粒度的多样化对齐后,相对来说更加可以预见。在不使用通用领域数据的情况下,在通用领域中遗忘更少,可能是做下游领域 MLLM 更关注的事情。这会让我们有更好的预期:比如加入通用数据后,通用能力不掉!
我认为通用领域遗忘更少有两个原因:
-
(显而易见)插入了通用专家,尽管通用专家也更新了。
-
(可能更本质)MoE Connector 的结构,由于 learnable router 的存在,通用专家的更新相比普通的 MLP Connector 是更少的(比如有些 token 可能确实没选到通用专家,它就不会对通用专家的更新产生贡献),某种程度上,可以认为 MoE Connector 这种 sparse 结构本身就带有一定的正则作用。
通用领域
我们选择了 MME 和 MMBench 两个比较有代表性的通用领域的 benchmark,比较了 baseline(InternLM-XComposer2)、用 chart 数据 directly SFT、以及 ChartMoE 的性能,可以看到,Directly SFT 模型在通用领域掉点严重,ChartMoE 几乎不会掉性能,且在有些细分领域上还有增点

Chart 领域
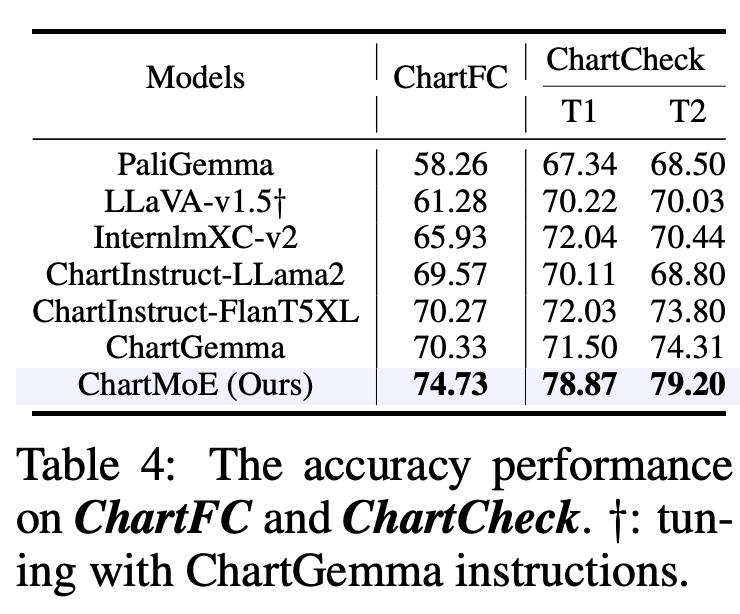
对于 Chart 领域,我们选择了 ChartQA、ChartBench(主要是无数值标注的 Chart)、ChartFC&ChartCheck(Fact Checking 任务,回答支持或不支持),在这些 Benchmark 上,ChartMoE 都能达到非常好的性能,尤其是相对初始的 baseline 模型(InternLM-XComposer2)提升非常显著。


Conclusion
在 ChartMoE 这个工作中,我们探索了通用 MLLM 使用 MoE 这种 sparse 的结构后在下游任务上的表现:
-
从 Representation 角度:专家异质化的 MoE 可以获得更加多样、更加全面的视觉表征,从而在下游任务上达到更好的性能。
-
从 Knowledge 角度:MoE 这种 Sparse 结构,可以等价于加入了适量的正则项,既能显著提高下游任务性能,也能缓解下游领域模型在通用任务上遗忘。
ChartMoE 是一个抛砖引玉的工作,我们相信后续也会有更多工作去探索下游任务中 Sparse 结构的表现!
