Python开源工具tempdisagg,解决时间序列分解难题,助力经济预测。集成经典算法和机器学习优化,方便易用。
原文标题:Python开源工具tempdisagg:轻松搞定时间序列分解,经济预测更精准!
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章提到tempdisagg未来会支持多元拆分,也就是可以使用多个高频指标。大家觉得哪些高频指标对于预测GDP月度数据最有帮助?
3、文章中提到tempdisagg在处理突变、不连续或剧烈波动的数据时可能会遇到问题。大家有什么好的方法来解决这个问题吗?
原文内容

本文共2600字,建议阅读5分钟本文为你介绍 Python 生态首个工业级时间序列分解工具。
在宏观经济监测和政策制定中,高频时间序列数据(如月度GDP)的缺失常常成为决策瓶颈。哥伦比亚大学研究者刚开源的 tempdisagg,作为 Python 生态首个工业级时间序列分解工具,成功填补了这一技术空白。该框架不仅复现了经典计量方法,更通过自动参数优化、集成建模等创新,将时间序列分解推向了新的高度。

【论文标题】
tempdisagg: A Python Framework for Temporal Disaggregation of Time Series Data
【论文地址】
https://arxiv.org/html/2503.22054v1#S3
【代码资源库】
https://github.com/jaimevera/tempdisagg
https://pypi.org/project/tempdisagg/
为什么需要时间序列分解?
无论是预测GDP走势,还是分析城市人口变化,低频统计数据(如年度总量)往往无法满足实时决策需求。经济学家们需要将这些“粗粒度”数据拆解为更细的时间单元(如月度),同时保证分解后的数据与原始总量一致——这正是时间序列分解技术的核心价值。
然而,现有工具要么操作复杂,要么功能单一。来自哥伦比亚大学的研究者推出的 tempdisagg 框架,集成了8种经典计量经济学算法,并创新性地引入机器学习优化策略,成为 Python 生态中首个“开箱即用”的工业级解决方案。
除了重现 Chow-Lin、Denton、Fernández 和 Litterman 等经典方法外,该软件包还引入了集成建模能力和估计后调整功能,使用户能够提高模型的稳健性,并满足现实世界的约束条件,例如非负性和聚合一致性。这些特性使得 tempdisagg 在国家统计、政策评估和经济预测等领域的应用中尤为宝贵。
通过将理论严谨性与软件工程最佳实践相结合,tempdisagg 既是一个实用工具,也是一个可扩展的研究平台。未来的开发可能会包括对多元降频的支持、与状态空间模型的集成以及贝叶斯估计方法,从而进一步扩展其在时间序列分析中的适用性。
框架核心功能解析
01、模块化架构设计
-
借鉴 scikit-learn 的 API 设计,提供 fit()、predict() 等标准方法。
-
处理流程模块化:数据验证 → 缺失值填充 → 聚合矩阵构建 → 模型训练 → 后处理校正。
02、经典算法支持
03、创新功能
-
ρ参数自动优化:通过最大似然估计或残差最小化自动确定最优自相关系数。
-
负值校正系统:GDP、人口等指标不能为负,工具自动调整并保持总量一致。
-
逆向填充模块:独有的 Retropolarizer 模块,通过比例调整、回归或神经网络补全缺失低频数据。
-
集成建模引擎:通过非负最小二乘法融合多个模型的预测结果,鲁棒性提升35%。
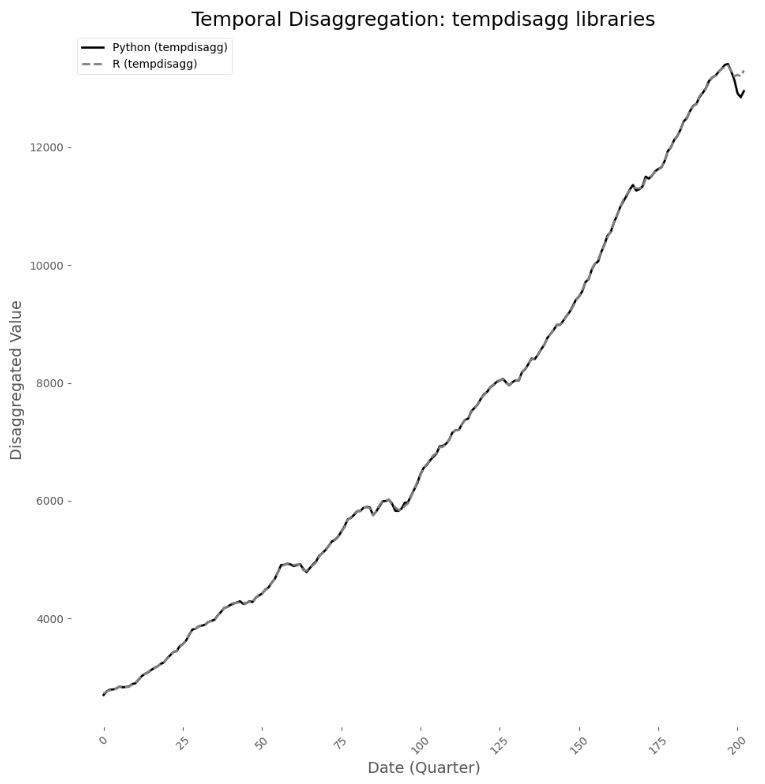
04、Python版本与R语言比较
这两个库在处理不完整周期以及自动填充的方式不同。
tempdisagg 的R语言实现会修剪或排除那些无法构成完整低频组的周期,而 Python 框架则通过 Time Series Completer 组件明确允许对部分子周期进行填充和插值。因此,Python 估计值通过填充序列末尾缺失的月份来保持连续性,这可能有助于提高在实时或短期预测中的适用性。但这种灵活性会导致与 R 语言输出相比,在最后一个周期出现细微差异,因为插值步骤会影响聚合矩阵的结构,进而影响最终的分解估计值。
总体而言,两种实现方式在核心估计逻辑上是一致的,并且都能提供具有统计稳健性的分解结果。不过,用户应注意每个库在序列完整性、填充和结构插值方面所做的默认假设,因为这些选择可能会微妙地影响最终的高频预测结果,尤其是在数据的边界处。
案例展示
01、美国宏观经济数据(年度至季度)
statsmodels 库中的宏观数据集包含了1959年第一季度到2009年第三季度的美国季度宏观经济指标。
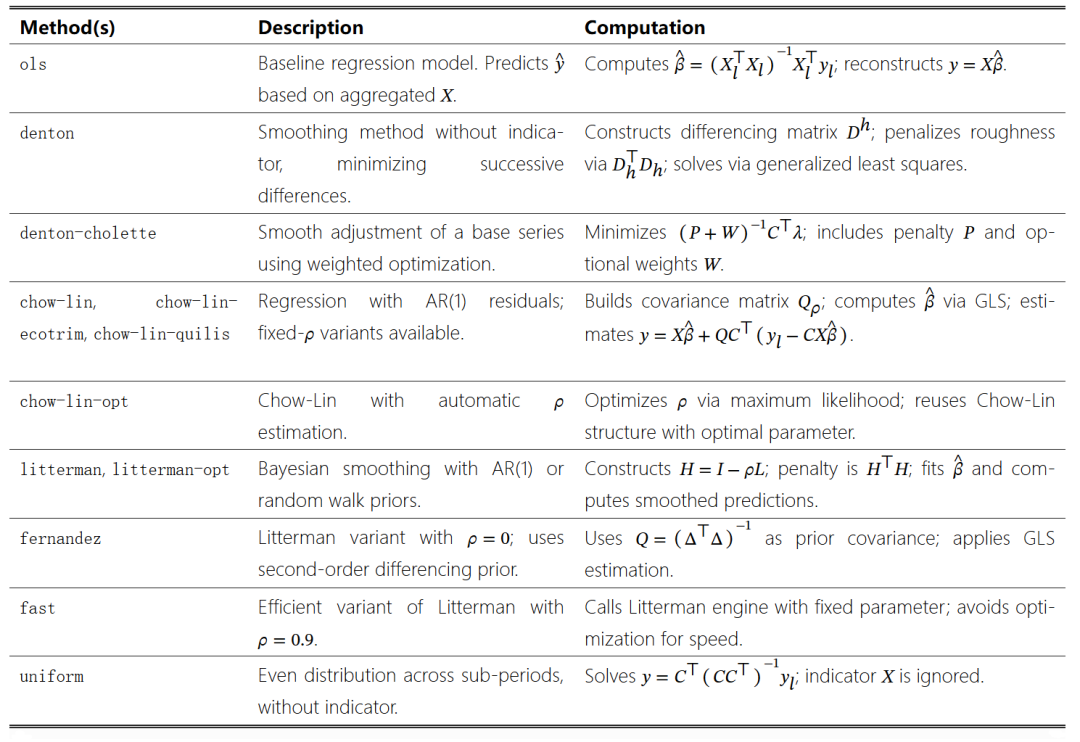
模拟一个时间分解场景,在这个场景中,实际 GDP 被人为地汇总为年度频率,然后使用实际消费作为高频指标重新分解回季度估计值。每年的年度GDP值是通过计算每个季度 GDP 观测值的平均数得出的。这些汇总总量作为低频目标变量(y),而原始的季度消费序列则用作高频指标(X)。最终的数据集被传递给 tempdisagg,展示了模型恢复与原始年度汇总一致的连贯季度估计值的能力。如图1所示,分解后的估计值紧密跟随由高频指标所暗示的季度动态。
02、美国宏观经济数据(季度至月度)
为了测试 tempdisagg 在真实高频数据上的性能,开发者使用了美国联邦储备经济数据(FRED)中的工业生产指数(INDPRO),作为从1947年1月到2024年12月的月度指标。
使用求和规则汇总每月的 INDPRO 值来模拟一个低频年度序列,该序列作为分解的目标变量。原始的每月 INDPRO 值保留为高频指标。这种设置能够评估 tempdisagg 在多大程度上能够恢复与汇总的年度总量一致的月度信号。
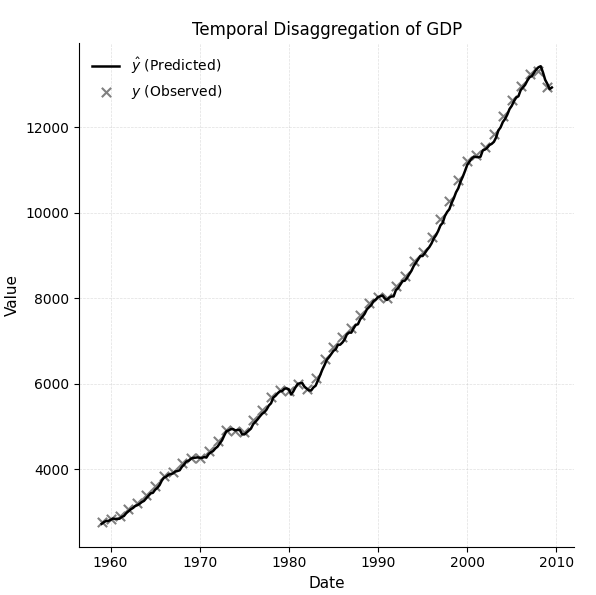
采用 chow-lin-opt 方法并应用求和转换规则来构建模型,所得估计值与指标的月度模式高度吻合。如图3所示,将年度 GDP 增长分解为月度估计值的时序分解结果总体上遵循指标所隐含的潜在趋势。然而,该模型在捕捉经济增速中的突变或异常波动方面准确性有所下降。这些偏差凸显了 Chow-Lin 等经典分解方法的一个已知局限性,即这些方法往往会平滑掉极端值,并且可能无法充分反映高频数据中的急剧拐点或经济冲击。
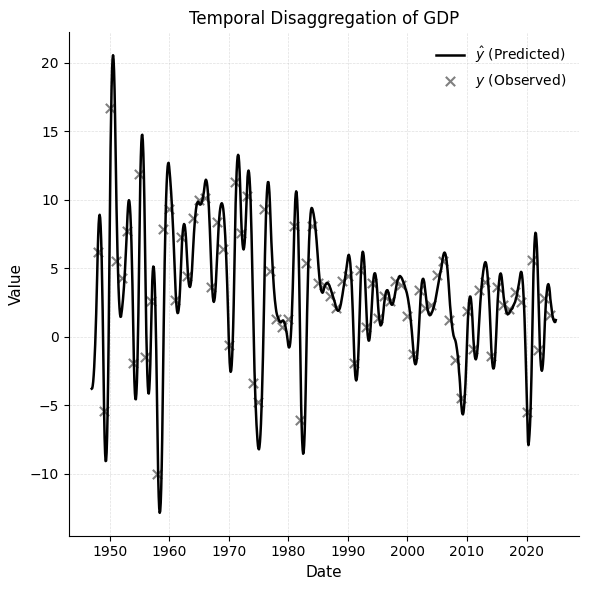
03、哥伦比亚人口数据分解
将年度全国人口总数转换为各省份的月度估计值:
-
采用chow-lin-opt方法,并使用平均聚合规则
-
以官方全国月度总数作为高频指标
-
该模型为每个省份生成了月度估计值,然后将其重新聚合回年度水平。
这些重建的数值与官方年度数据(人口)进行了比较,以评估细分技术的准确性。结果表明,tempdisagg 能够从国家级人口数据中生成一致且准确的次国家级估计值,即使在现实条件下也是如此。然而,在解释极端情况时需谨慎,因为传统分组方法可能难以处理高度波动或不规则的数据系列。

总结
目前,tempdisagg 仅支持单变量时间序列拆分方法,该方法依赖于单一高频指标序列。尽管这种设计保证了模型的简洁性和可解释性,但它限制了模型捕捉复杂动态的能力,而捕捉复杂动态可能需使用多个解释变量。未来计划将支持多元拆分(即同时纳入多个高频指标)作为一项关键增强功能。
此外,诸如 Chow-Lin、Denton 和 Litterman 等经典拆分模型假定底层高频结构的行为相对平稳。当目标序列出现突变、不连续或剧烈波动时(这在某些区域或行政单位的预测中较为常见),这些模型可能难以生成稳定且现实的估计值。这种对不规则性的敏感性可能导致极端值或局部不一致性,尤其是在数据稀疏或噪声较大的情况下。
开发者指出未来的工作将探索整合稳健的统计技术、正则化方法和机器学习模型,以更好地处理此类具有挑战性的情况。目前还在考虑扩展功能以支持层级调和、不确定性量化以及基于情景的预测,从而提高该框架在各个领域和数据环境中的适用性。
