南开大学提出HINT模型,通过分层多头注意力机制解决图像恢复中传统MHA的冗余问题,显著提升图像恢复质量和效率。
原文标题:CVPR 2025 | 魔鬼藏于统一性——即插即用分层多头注意力!
原文作者:数据派THU
冷月清谈:
本文介绍了一种名为HINT的Transformer模型,它通过引入层次化多头注意力(HMHA)和查询-键缓存更新(QKCU)模块,旨在解决传统多头注意力(MHA)在图像恢复中存在的冗余问题。HMHA通过分层子空间划分和重排序操作,鼓励模型学习多样化的代表性特征,而QKCU模块则增强了头之间的交互作用,调节预测特征。实验结果表明,HINT在低光增强、去雾、去雪、去噪和去雨等多种图像恢复任务上均表现出色,并在模型复杂度和准确性之间取得了较好的平衡。该研究为图像恢复领域提供了一个新的方向,并为未来在极端条件下的图像恢复提供了潜在的解决方案。
怜星夜思:
1、文章中提到的HMHA的核心思想是通过子空间划分和重排序来减少冗余,那么在实际应用中,如何确定最佳的子空间划分策略,以保证各个头能够学习到真正不同的上下文信息?你认为是否存在一种自适应的子空间划分方法?
2、QKCU模块通过增强头之间的交互来减少冗余,那么这种交互方式是否会引入新的计算负担?在计算资源有限的情况下,如何平衡交互的强度和计算效率?
3、文章提到HINT在极端低光条件下仍面临挑战,未来可以考虑收集大规模真实世界数据集进行进一步训练。那么,如何解决真实世界数据集的标注问题?是否存在一些半监督或者自监督的学习方法,可以用于提升模型在无标注数据上的性能?
2、QKCU模块通过增强头之间的交互来减少冗余,那么这种交互方式是否会引入新的计算负担?在计算资源有限的情况下,如何平衡交互的强度和计算效率?
3、文章提到HINT在极端低光条件下仍面临挑战,未来可以考虑收集大规模真实世界数据集进行进一步训练。那么,如何解决真实世界数据集的标注问题?是否存在一些半监督或者自监督的学习方法,可以用于提升模型在无标注数据上的性能?
原文内容


一、论文信息
论文题目:Devil is in the Uniformity: Exploring Diverse Learners within Transformer for Image Restoration
中文题目:魔鬼藏于统一性中:探索用于图像恢复的Transformer中的多样化学习者论文链接:https://arxiv.org/pdf/2503.20174v1
所属单位:南开大学计算机科学学院 VCIP & TMCC & DISSec,南开国际高级研究院(深圳·福田),南京理工大学计算机科学与工程学院。
二、论文概要
Highlight

图1. 普通多头注意力(MHA)与提出的HMHA(配备QKCU模块)的比较(左)和提出的HMHA(配备QKCU模块)(右),用于低光增强任务。标准的MHA为h个头分配了相同大小(C')的子空间,并且每个头独立执行注意力计算。因此,这些头倾向于关注相同的区域(红色框),并忽略一些退化区域(黄色框)的恢复,导致输出不令人满意(细节丢失和引入模糊效果)。相比之下,HMHA在层次化子空间分割之前实施了重新排序操作,这鼓励模型学习多样化的代表性特征。QKCU通过层内/层间方式增强了头之间的交互作用,调节HMHA中的预测特征,从而产生更好的输出。

图4. 在LOL-v2上对低光增强的定性结果。顶部案例来自合成子集,而底部案例来自真实子集。与其他技术相比,HINT生成的图像生动,没有引入明显的色彩失真。

图6. 在SOTS 基准测试上对雾霾去除的定性结果。HINT生成的图像比其他方法更接近参考图像。

图7. 特征可视化。最上面一行展示了MDTA学习到的每个头的特征图,而底部的特征图展示了HMHA的结果。MDTA中的头倾向于关注相同的区域(红色框),而HMHA中的对应部分则在从不同子空间学习表示方面显示出优越性。因此,配备了所提出的HMHA的模型恢复出的图像更令人愉悦,更接近参考图像(黄色框)。

图8. 在真实世界基准测试上的可视化,包括NPE、DICM、VV和 MEF(从上到下)。HINT恢复了令人愉悦的结果,而所考虑的技术则遇到了曝光不足/过度曝光问题,或者触发了色彩失真,或者仍然存在显著的伪影。
1. 研究背景
-
研究问题:在图像恢复领域,基于Transformer的方法已经显示出显著的性能,其中多头注意力(MHA)机制在捕获多样特征和恢复高质量图像方面起着关键作用。然而,MHA中独立的头从统一划分的子空间进行注意力计算,导致了冗余问题,限制了模型输出的满意度。本文旨在解决这一问题,提出一种改进的MHA机制,以提高图像恢复的质量。
-
研究难点:MHA机制的冗余问题主要表现在不同的头倾向于关注相同的区域,而忽略了对一些退化区域的恢复,导致输出结果不理想。此外,头之间缺乏协作加剧了冗余问题,限制了模型的表示能力。
-
文献综述:在图像恢复领域,从传统的手工制作方法到基于学习的CNN模型,研究者们见证了从低级任务到高级任务的范式转变。近年来,基于Transformer的模型被应用于低级任务,并在各种图像恢复任务中取得了显著进展。然而,这些模型仍然依赖于传统的MHA,存在冗余问题,限制了模型的性能。为了解决这一问题,研究者们提出了各种高效的模块和先进的架构设计,例如残差特征学习、编码器-解码器架构和注意力机制等。尽管这些注意力机制成功缓解了计算负担,但它们仍然依赖于传统的MHA,存在冗余问题,限制了模型的表示能力。
2. 本文贡献
-
Hierarchical Multi-head Attention (HMHA):提出了一种分层多头注意力机制(HMHA),通过在不同大小和包含不同信息的子空间中学习,鼓励每个头学习不同的上下文特征,从而缓解了标准多头注意力(MHA)中的冗余问题。(本推文介绍重点)
-
Query-Key Cache Updating (QKCU) 模块:引入了QKCU机制,包括层内和层间方案,通过增强注意力头之间的交互来减少冗余问题。QKCU模块通过门控机制选择性地保留信息流中最关键的元素,从而提高模型学习不同上下文表示的能力。
三、创新方法


HMHA能够有效地解决传统多头注意力(MHA)中头之间冗余的问题,并提高模型在图像恢复任务中的性能,实现步骤:
1、子空间划分:HMHA通过重新排列通道来分配不同的子空间给各个头,将通道空间分割为C = [C1, C2, . . . , Ch],其中C1 ≤ C2 ≤ ... ≤ Ch,确保每个子空间包含的信息是独立的,并且子空间的大小是不同的。这样设计的目的是让每个头能够学习到不同的上下文信息,从而提取出多样化的特征表示。
2、重排序操作:在进行层次化子空间划分之前,先对通道进行重排序,基于它们的相似性进行分组。这一步骤的目的是确保每个头能够关注到不同的语义特征,从而减少冗余并提高模型的表达能力。
3、多头注意力计算:在每个子空间内,各个头独立地执行点积注意力计算。每个头在自己的子空间内进行注意力计算,以捕获不同的上下文信息。通过上述步骤,模型能够融合来自不同子空间的多样特征,从而得到更加丰富和全面的特征表示。
四、实验分析
1. 数据集与评估指标:在12个基准数据集上进行了5种典型的图像恢复任务的实验,包括低光增强、去雾、去雪、去噪和去雨。使用峰值信噪比(PSNR)和结构相似性(SSIM)指标来评估恢复图像与参考图像之间的质量。此外,还采用了非参考指标MANIQA来衡量真实世界输入的恢复性能。
2. 训练细节:使用AdamW优化器进行训练,并采用广泛采用的损失函数来约束模型训练。模型训练时采用的超参数α被实验性地设置为0.9。HINT模型采用编码器-解码器架构,包含4个级别的编码器和解码器,以及4个基本块。在第4级,编码器和解码器块被统一为一个瓶颈层。此外,还包含一个细化阶段,由4个基本块组成。3. 结果与分析:
2. 训练细节:使用AdamW优化器进行训练,并采用广泛采用的损失函数来约束模型训练。模型训练时采用的超参数α被实验性地设置为0.9。HINT模型采用编码器-解码器架构,包含4个级别的编码器和解码器,以及4个基本块。在第4级,编码器和解码器块被统一为一个瓶颈层。此外,还包含一个细化阶段,由4个基本块组成。3. 结果与分析:
低光增强:HINT在LOL-v2数据集上的表现优于现有的低光增强方法,特别是在PSNR和SSIM指标上。HINT在平均PSNR上比Retinexformer提高了0.9 dB,比其他算法至少提高了1.74 dB。

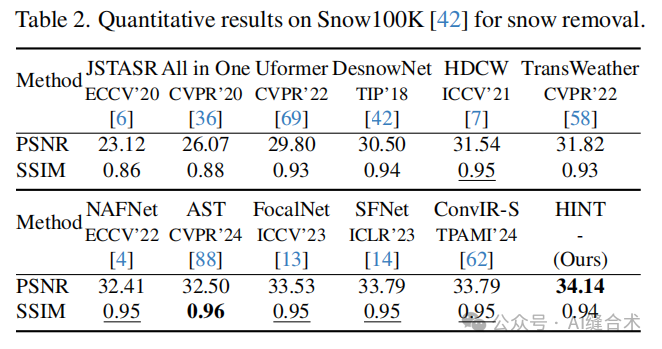
图像去雪:在Snow100K数据集上,HINT在PSNR和SSIM指标上均取得了最佳成绩,比最近的通用恢复流程AST提高了1.64 dB的PSNR。
图像去雾:在SOTS数据集上,HINT在PSNR和SSIM指标上均优于其他方法,至少在PSNR上提高了0.35 dB。

模型效率:HINT在保持较低模型复杂度的同时,获得了最高的PSNR分数,其性能优于基于CNN的MIRNet、基于Transformer的IPT和Restormer。


真实世界场景评估:在没有真实参考的现实世界数据集上,HINT在所有方法中表现最佳,恢复的图像视觉效果令人满意。

五、结论
1. HINT模型的有效性:HINT模型通过引入HMHA和QKCU机制,有效解决了标准MHA中的冗余问题,并提高了模型的表达能力。HINT在多个图像恢复任务中均表现出色,特别是在模型复杂度和准确性方面。
2. 研究贡献:HINT是首个在广泛使用的Transformer架构内探索高效MHA机制以恢复高质量图像的工作。该研究为图像恢复领域提供了新的方向,并有望激发社区的兴趣和进一步的研究。
3. 未来工作方向:尽管HINT在图像恢复方面取得了显著成果,但在极端低光条件下恢复输入图像时仍面临挑战。未来工作可以考虑收集大规模真实世界数据集进行进一步训练,以解决这一问题。
3. 未来工作方向:尽管HINT在图像恢复方面取得了显著成果,但在极端低光条件下恢复输入图像时仍面临挑战。未来工作可以考虑收集大规模真实世界数据集进行进一步训练,以解决这一问题。
