NUS团队提出FAR模型,解决长上下文视频生成难题。采用长短时上下文建模和多层KV Cache机制,实现短视频、长视频预测SOTA,代码已开源。
原文标题:迈向长上下文视频生成!NUS团队新作FAR同时实现短视频和长视频预测SOTA,代码已开源
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到FAR模型在world modeling场景中实现了近乎完美的长期记忆效果,这对未来的游戏AI或者机器人技术有什么潜在的应用价值?
3、FAR模型通过长短时上下文建模来提高效率,这个思路在其他领域有没有借鉴意义?比如自然语言处理或者推荐系统?
原文内容

本文由 NUS ShowLab 主导完成。第一作者顾宇超为新加坡国立大学 ShowLab@NUS 在读博士生,研究方向是视觉生成,在 CVPR、ICCV、NeurIPS 等国际顶级会议与期刊上发表多篇研究成果。第二作者毛维嘉为新加坡国立大学 ShowLab@NUS 二博士生,研究方向是多模态理解和生成,项目负责作者为该校校长青年教授寿政。

-
论文标题:Long-Context Autoregressive Video Modeling with Next-Frame Prediction
-
论文链接:https://arxiv.org/abs/2503.19325
-
项目主页:https://farlongctx.github.io/
-
开源代码:https://github.com/showlab/FAR
背景:长上下文视频生成的挑战
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。
解决这一问题的关键在于:高效地对长视频进行训练。但传统的自回归视频建模面临严重的计算挑战 —— 随着视频长度的增加,token 数量呈爆炸式增长。 视觉 token 相较于语言 token 更为冗余,使得长下文视频生成比长上下文语言生成更为困难。
本文针对这一核心挑战,首次系统性地研究了如何高效建模长上下文视频生成,并提出了相应的解决方案。
我们特别区分了两个关键概念:
-
长视频生成:目标是生成较长的视频,但不一定要求模型持续利用已生成的内容,因此缺乏长时序的一致性。这类方法通常仍在短视频上训练,通过滑动窗口等方式延长生成长度。
-
长上下文视频生成:不仅要求视频更长,还要持续利用历史上下文信息,确保长时序一致性。这类方法需要在长视频数据上进行训练,对视频生成建模能力提出更高要求。
长上下文视频生成的重要性:
最近的工作 Genie2 [1] 将视频生成用于 world modeling /game simulation 的场景中,展现出非常令人惊艳的潜力。然而,现有基于滑窗的生成方法通常缺乏记忆机制,无法有效理解、记住并重用在 3D 环境中探索过的信息,比如 OASIS [2]。这种缺乏记忆性的建模方式,不仅影响生成效果,还可能导致对物理规律建模能力的缺失。这可能正是当前长视频生成中常出现非物理现象的原因之一:模型本身并未在大量长视频上训练,i2v(image-to-video)+ 滑动窗口的方式难以确保全局合理性。
FAR 的创新设计与分析
1)帧自回归模型(FAR)
FAR 将视频生成任务重新定义为基于已有上下文逐帧(图像)生成的过程。为解决混合自回归与扩散模型在训练与测试阶段存在的上下文不一致问题,我们在训练过程中随机引入干净的上下文信息,从而提升模型测试时对利用干净上下文的稳定性。
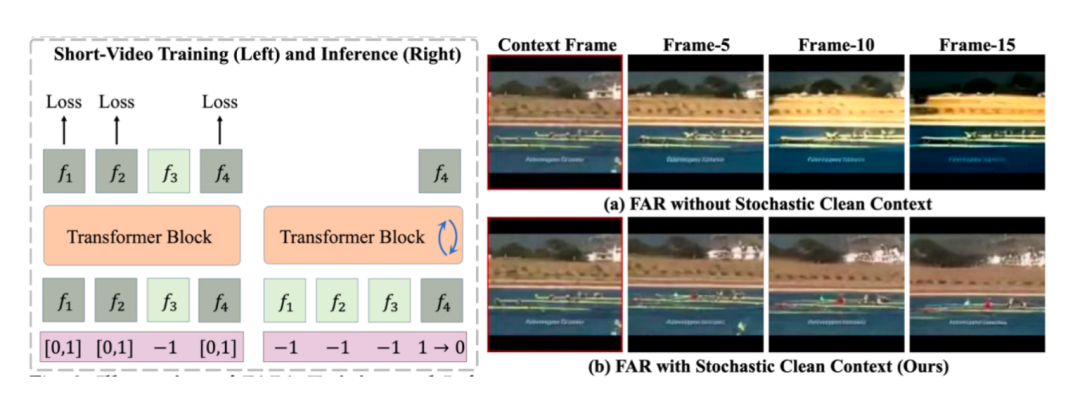
FAR 的训练测试流程;测试时对干净上下文的生成结果。
2) 长短时上下文建模
我们观察到,随着上下文帧数量的增加,视频生成中会出现视觉 token 数量急剧增长的问题。然而,视觉 token 在时序上具有局部性:对于当前解码帧,其邻近帧需要更细粒度的时序交互,而远离的帧通常仅需作为记忆存在,无需深入的时序交互。基于这一观察,我们提出了 长短时上下文建模。该机制采用非对称的 patchify 策略:短时上下文保留原有的 patchify 策略,以保证细粒度交互;而长时上下文则进行更为激进的 patchify,减少 token 数量,从而在保证计算效率的同时,维持时序模拟的质量。

FAR 的长视频训练测试流程
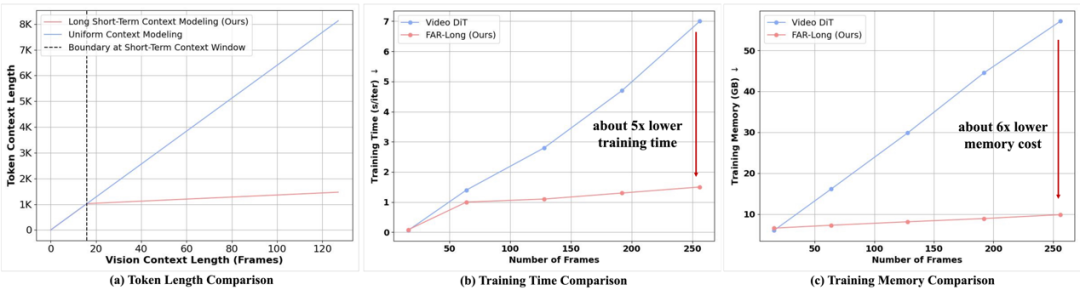
长短时上下文的非对称 patchify 带来的 token 减少以及训练效率提升
3) 用于长上下文视频生成的多层 KV Cache 机制
针对长短时上下文的非对称 patchify 策略,我们提出了相应的多层 KV-Cache 机制。在自回归解码过程中,当某一帧刚离开短时上下文窗口时,我们将其编码为低粒度的 L2 Cache(少量 token);同时,更新仍处于短时窗口内帧的 L1 Cache(常规 token)。最终,我们结合这两级 KV Cache,用于当前帧的生成过程。
值得强调的是,多层 KV Cache 与扩散模型中常用的 Timestep Cache 是互补的:前者沿时间序列方向缓存 KV 信息,后者则在扩散时间步维度上进行缓存,共同提升生成效率。
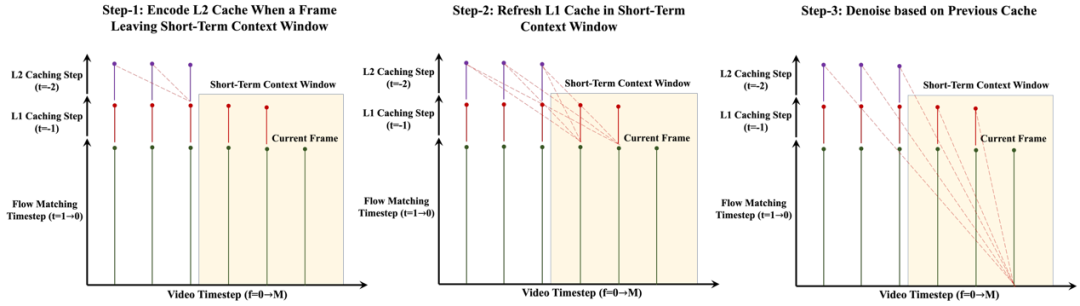
针对长短时上下文策略的多层 KV Cache
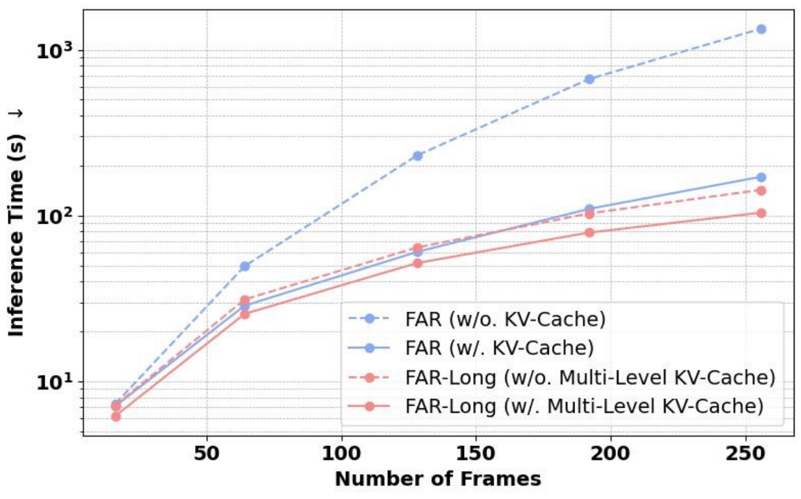
长视频生成的效率提升
FAR 相对于 SORA 类 VideoDiT 的潜在优势
1)收敛效率:在相同的连续潜空间上进行实验时,我们发现 FAR 相较于 Video DiT 展现出更快的收敛速度以及更优的短视频生成性能。
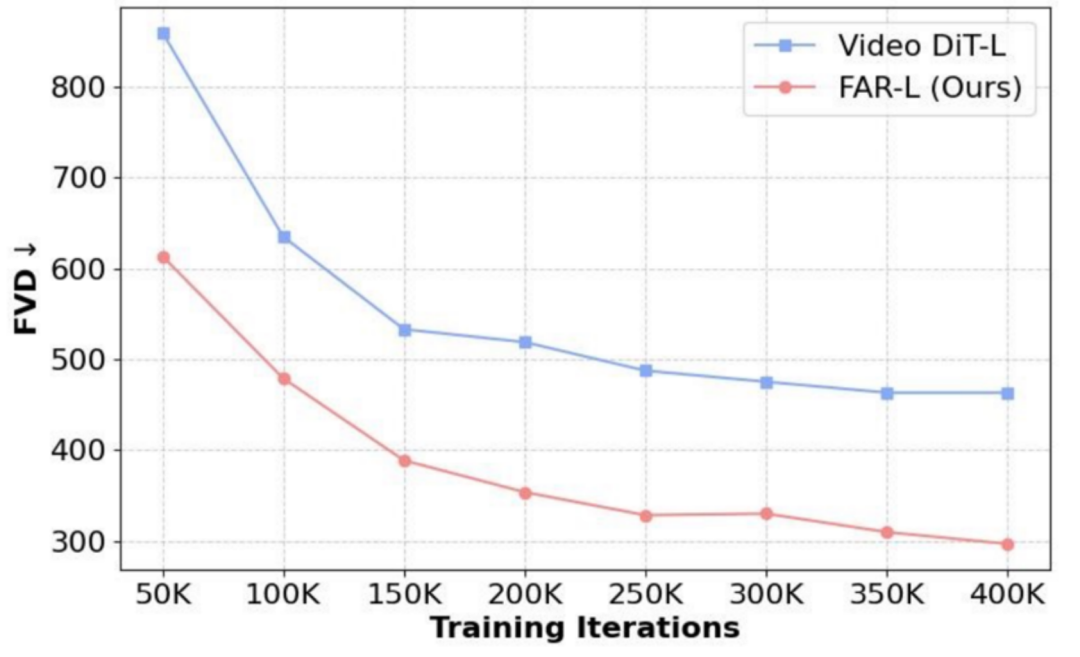
FAR 与 Video DiT 的收敛对比
2)无需额外的 I2V 微调:FAR 无需针对图像到视频(I2V)任务进行额外微调,即可同时建模视频生成与图像到视频的预测任务,并在两者上均达到 SOTA 水平。
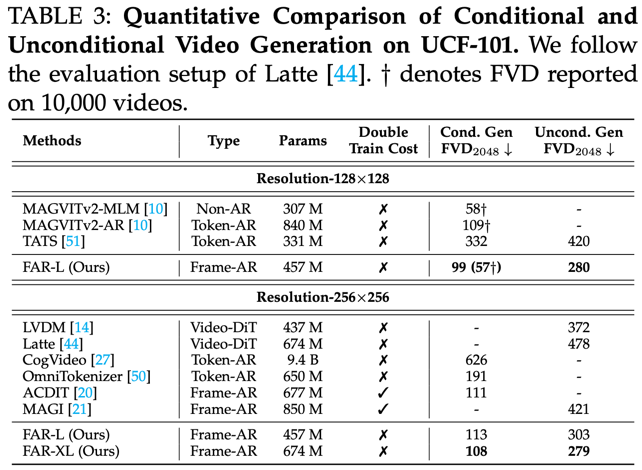
条件 / 非条件视频生成的评测结果
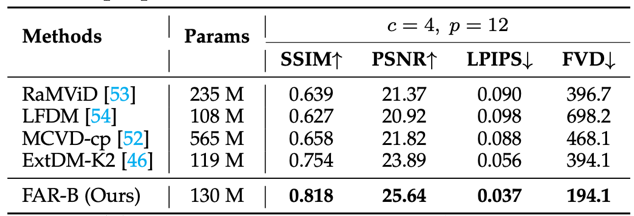
基于条件帧的视频预测的评测结果
3)高效的长视频训练与长上下文建模能力:FAR 支持高效的长视频训练以及对长上下文建模。在基于 DMLab 的受控环境中进行实验时,我们观察到模型对已观测的 3D 环境具有出色的记忆能力,在后续帧预测任务中首次实现了近乎完美的长期记忆效果。

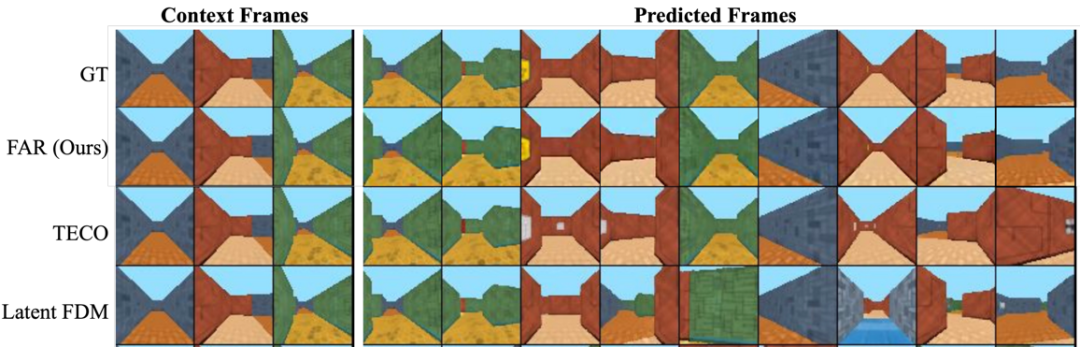
总结
我们首次系统性地验证了长上下文建模在视频生成中的重要性,并提出了一个基于长短时上下文的帧自回归模型 ——FAR。FAR 不仅在短视频生成任务中,相较于 Video DiT 展现出更快的收敛速度与更优性能,同时也在长视频的 world modeling 场景中,首次实现了显著的长时序一致性。此外,FAR 有效降低了长视频生成的训练成本。在当前文本数据趋于枯竭的背景下,FAR 为高效利用现有海量长视频数据进行生成式建模,提供了一条具有潜力的全新路径。
参考文献:
【1】Genie 2: https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/
【2】Oasis: https://oasis-model.github.io/
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com