UIUC与谷歌发布Search-R1,利用强化学习训练大模型自主进行推理和搜索,解决知识缺失问题,显著提升问答性能。
原文标题:UIUC联手谷歌发布Search-R1:大模型学会「边想边查」,推理、搜索无缝切换
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到Search-R1在训练时对搜索结果进行了损失屏蔽(loss masking),这是为什么?如果不进行损失屏蔽,可能会出现什么问题?
3、Search-R1允许模型进行多轮搜索,这种机制在哪些场景下特别有用?它可能会带来哪些新的挑战?
原文内容

本文的作者来自伊利诺伊大学香槟分校(UIUC)、马萨诸塞大学(UMass)和谷歌。本文的第一作者为 UIUC 博士生金博文,主要研究方向为与大语言模型相关的智能体、推理和强化学习研究。其余学生作者为 UMass 博士生曾翰偲和 UIUC 博士生岳真锐。本文的通信作者为 UIUC 教授韩家炜。
DeepSeek-R1 展示了强化学习在提升模型推理能力方面的巨大潜力,尤其是在无需人工标注推理过程的设定下,模型可以学习到如何更合理地组织回答。然而,这类模型缺乏对外部数据源的实时访问能力,一旦训练语料中不存在某些关键信息,推理过程往往会因知识缺失而失败。
与此同时,另一个研究方向——搜索增强生成(Retrieval-Augmented Generation, RAG),试图通过引入外部搜索引擎缓解上述问题。现有 RAG 方法主要分为两类:
-
基于 Prompting 的方法:直接在提示词中引导大模型调用搜索引擎。这种方式虽无需额外训练,但存在明显局限:大模型本身可能并不具备如何与搜索引擎交互的能力,例如何时触发搜索、搜索什么关键词等,往往导致调用行为不稳定或冗余。
-
基于监督微调(SFT)的训练方法:通过构建高质量的数据集,训练模型学习合理的搜索调用策略。这类方法具有更强的适应性,但却面临可扩展性差的问题:一方面,构建高质量、覆盖丰富推理路径的搜索数据非常昂贵;另一方面,由于搜索操作本身不可微分,无法直接纳入梯度下降优化流程,阻碍了端到端训练的有效性。
为此,我们提出了一个新的训练范式——Search-R1,它基于强化学习,通过环境交互式学习方式训练大模型自主掌握推理与搜索交替进行的策略,实现真正意义上的「边推理,边搜索」的闭环智能体。

-
论文标题:Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
-
论文地址:https://arxiv.org/abs/2503.09516
-
代码地址:https://github.com/PeterGriffinJin/Search-R1
-
huggingface 主页:https://huggingface.co/collections/PeterJinGo/search-r1-67d1a021202731cb065740f5
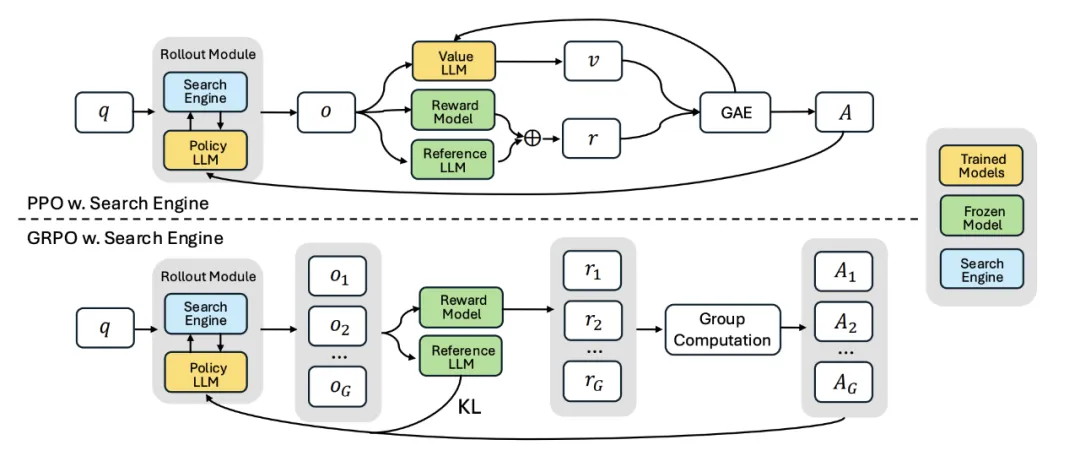
方法
搜索增强的强化学习框架
传统 RL 方法通常让大模型仅在固定输入上学习生成答案。而 Search-R1 引入了一个可交互的「搜索引擎模块」,模型可以在生成过程中随时发起搜索请求,获取外部知识,从而提升推理质量。
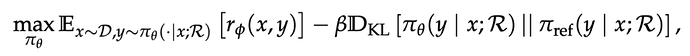
为了避免训练时对搜索结果本身产生不必要的「记忆」,我们对搜索引擎返回的文本进行了损失屏蔽(loss masking),确保模型仅学习如何在检索增强背景下进行合理推理,而非简单复制外部知识。
多轮搜索调用的生成机制
Search-R1 允许模型在回答前进行多轮推理与搜索交替进行。具体流程如下:
-
模型首先通过 <think>...</think> 标签进行推理;
-
如果模型判断当前知识不够,会触发 <search>关键词</search>;
-
系统自动调用搜索引擎,将搜索结果以 <information>...</information> 的形式插入上下文;
-
模型根据新信息继续推理,直到输出 <answer>答案</answer>为止。
整个过程高度模块化且可扩展,支持多个搜索引擎与自定义检索策略。

结构化的训练模板
我们设计了简单但有效的训练模板(instruction),统一所有训练样本的格式:

这种训练模板(instruction)指导大语言模型以结构化的方式与外部搜索引擎进行交互,同时保留策略空间的灵活性,使模型在强化学习过程中能够自主探索更优的搜索—推理策略。
轻量的奖励设计
为减少训练成本与复杂性,我们采用了基于最终回答准确性的奖励函数,无需构建额外的神经网络打分模型,提升了训练效率并降低了策略对奖励信号偏差的敏感性。
实验结果
主要性能表现
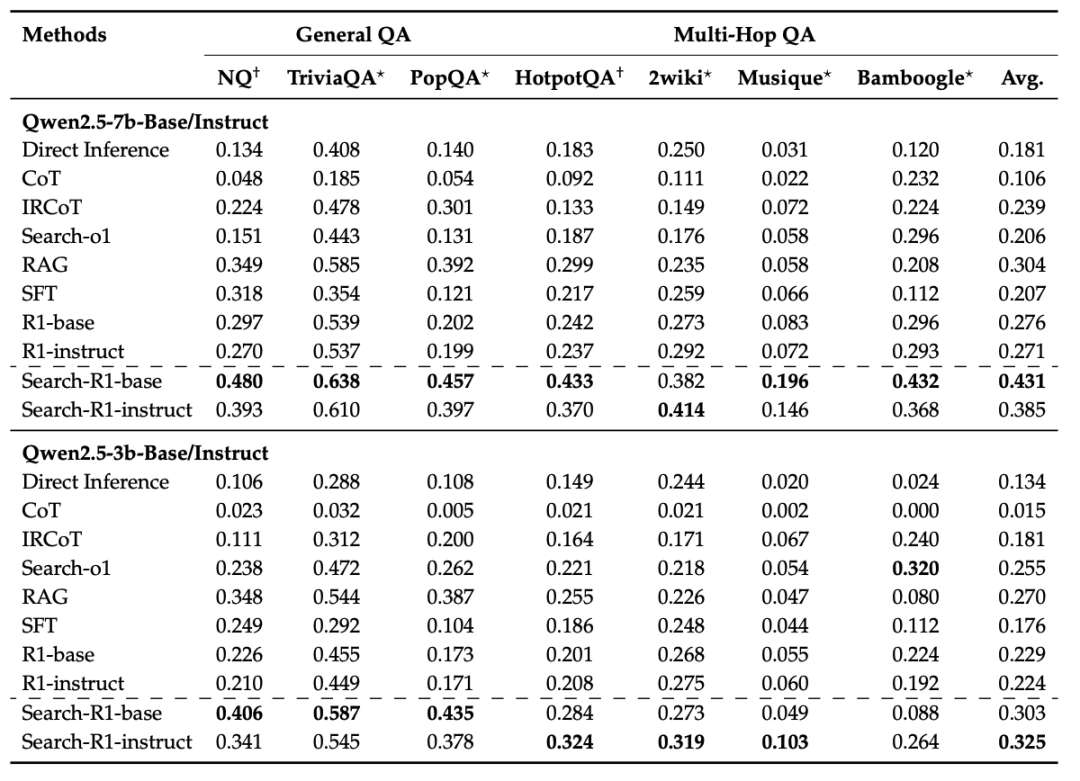
-
Search-R1 在所有数据集上均取得领先表现,其中 Qwen2.5-7B 模型平均相对提升 41%,3B 模型提升 20%,相较 RAG 和 CoT 等方法具有显著优势;
-
引入搜索引擎的 RL 优于纯推理 RL(R1),验证了搜索在知识稀缺问题中的重要性;
-
在零样本和跨任务迁移场景中也具有稳健表现,如在 PopQA、Musique、Bamboogle 等模型未见过的任务中依然保持显著优势;
-
更大的模型对搜索行为更敏感、效果更好,7B 模型相较 3B 展现出更大性能提升。
PPO vs. GRPO
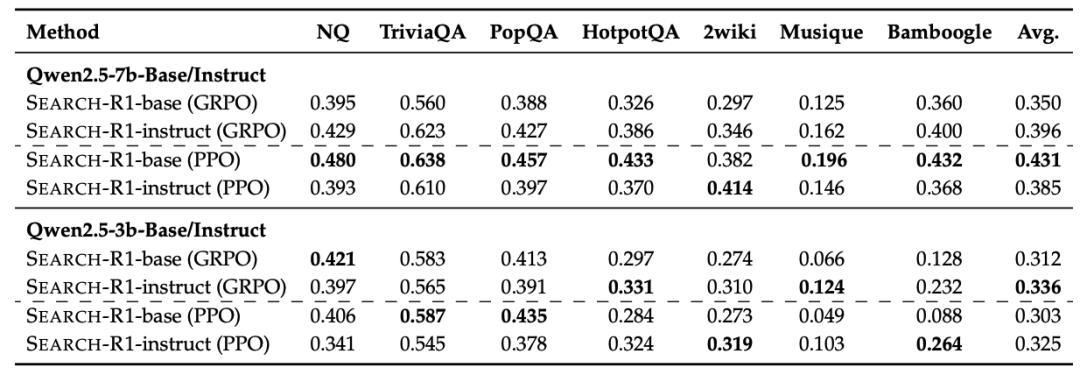
我们对两种 RL 优化策略进行了系统比较:GRPO 收敛更快,但在训练后期可能存在不稳定性;PPO 表现更稳定,最终性能略高于 GRPO,成为默认推荐配置;两者最终训练 reward 相近,均适用于 Search-R1 的优化目标。
Base 模型 vs. Instruct 模型
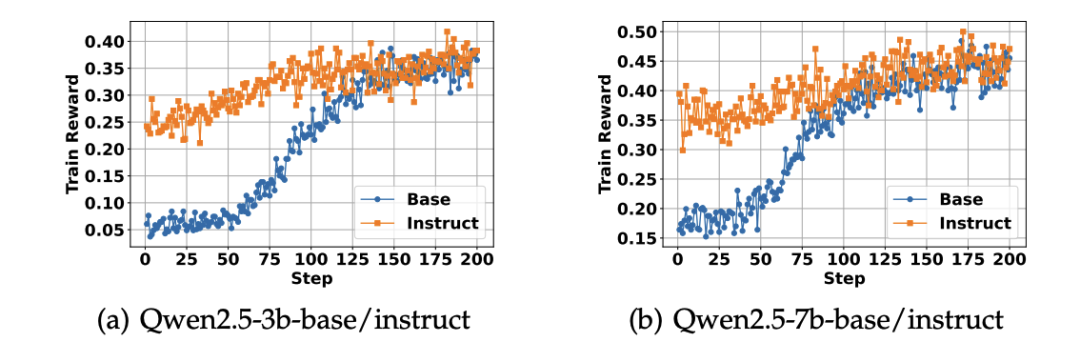
实验显示:Instruct 模型初始表现更好,训练收敛更快;但随着训练推进,Base 模型最终可达到相近甚至更优的效果;强化学习弥合了两者在结构化推理任务中的能力差异。
搜索行为与响应结构的动态学习
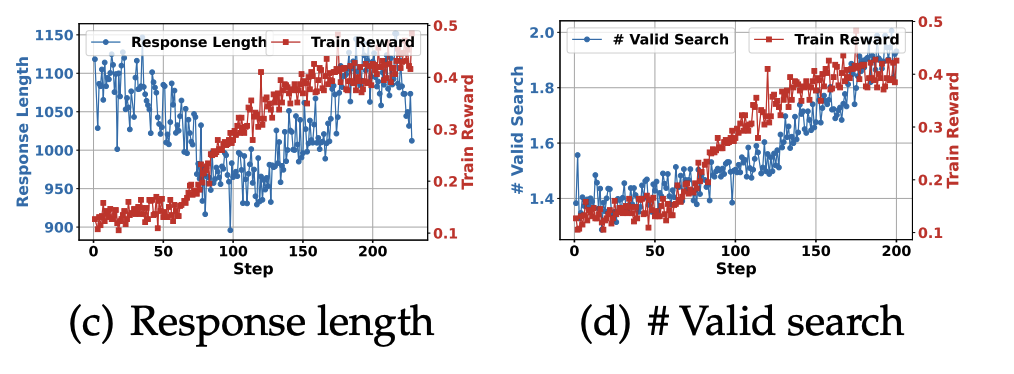
训练初期模型输出较短,搜索行为少;随着训练推进,模型逐渐学会更频繁调用搜索,响应长度增加;表明模型逐步掌握了「推理中搜索」的动态交互式策略。
总结
本文提出了 Search-R1,一种全新的强化学习框架,使大语言模型能够在生成过程中灵活调用搜索引擎,实现推理与外部检索的深度融合。相较于传统的 RAG 或工具使用方案,Search-R1 无需大规模监督数据,而是通过 RL 自主学习查询与信息利用策略。
我们在七个问答任务上验证了其显著的性能提升,并系统分析了不同训练策略对搜索增强推理的影响。未来,我们期待将该框架扩展到更多工具与信息源的协同调用,探索其在多模态推理任务中的应用潜力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com