DeepSeek R1 后,LLM 推理模型迎来快速发展。本文梳理 14 篇重要论文,探讨如何通过增加推理时间计算来提升模型能力,使小模型也能超越大模型。
原文标题:DeepSeek-R1之后推理模型发展如何?Raschka长文梳理后R1时代14篇重要论文
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到多种推理时间扩展方法,你认为哪种方法最具潜力,未来可能在哪些领域发挥重要作用?
3、文章最后提到了推理能力将成为 LLM 的“标准配置”,你认为这会对 AI 行业带来哪些深远影响?
原文内容

来源:人工智能前沿讲习本文共8000字,建议阅读10+分钟
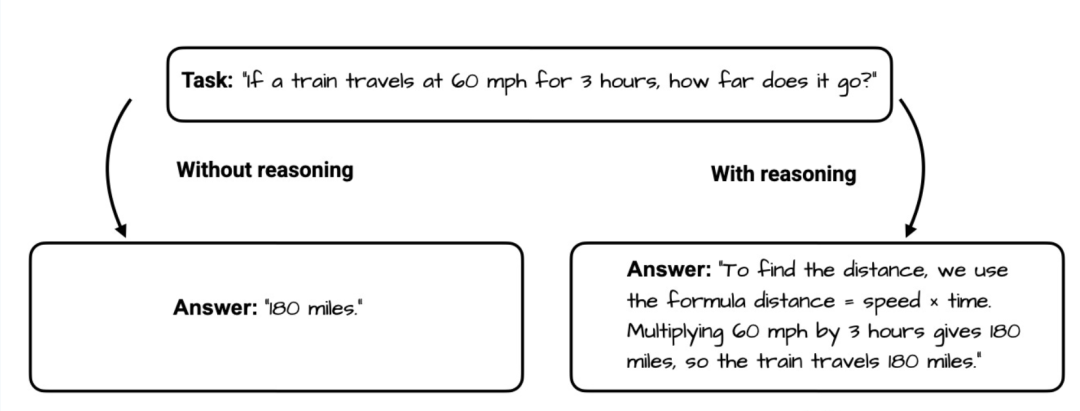
在 DeepSeek R1 发布之后,行业出现了一个引人注目的趋势,即「按需思考」。


原文地址:https://magazine.sebastianraschka.com/p/state-of-llm-reasoning-and-inference-scaling
-
过程透明化:通过思维链(CoT)等技术,将问题拆解为可解释的推理步骤,使模型决策路径可视化。
-
计算动态化:采用测试时间扩展(Test-Time Scaling)等策略在推理阶段动态分配更多计算资源处理复杂子问题。
-
训练强化:结合强化学习(如 RLHF)、对抗训练等方法,利用高难度推理任务数据集(如 MATH、CodeContests)进行微调,提升符号推理与逻辑连贯性。

-
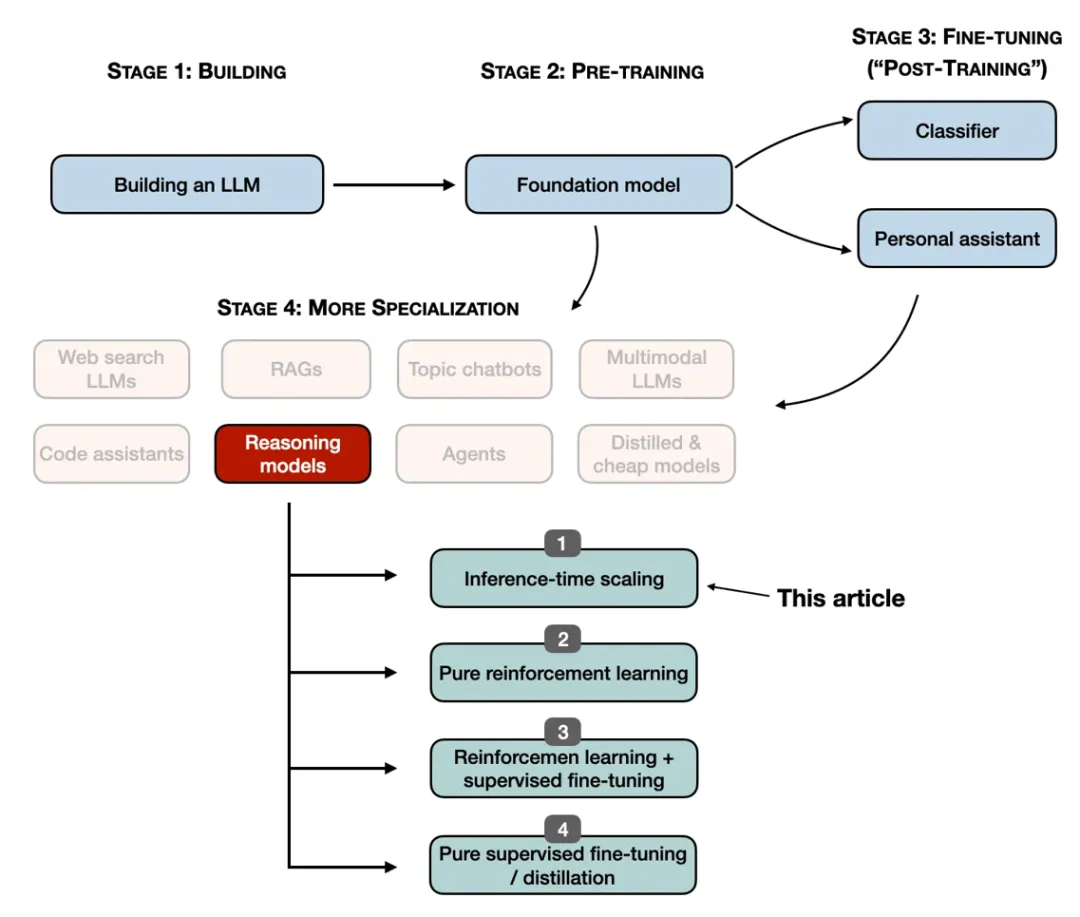
增加训练计算,即通过扩展训练数据量、强化学习或针对特定任务的微调来增强模型能力;
-
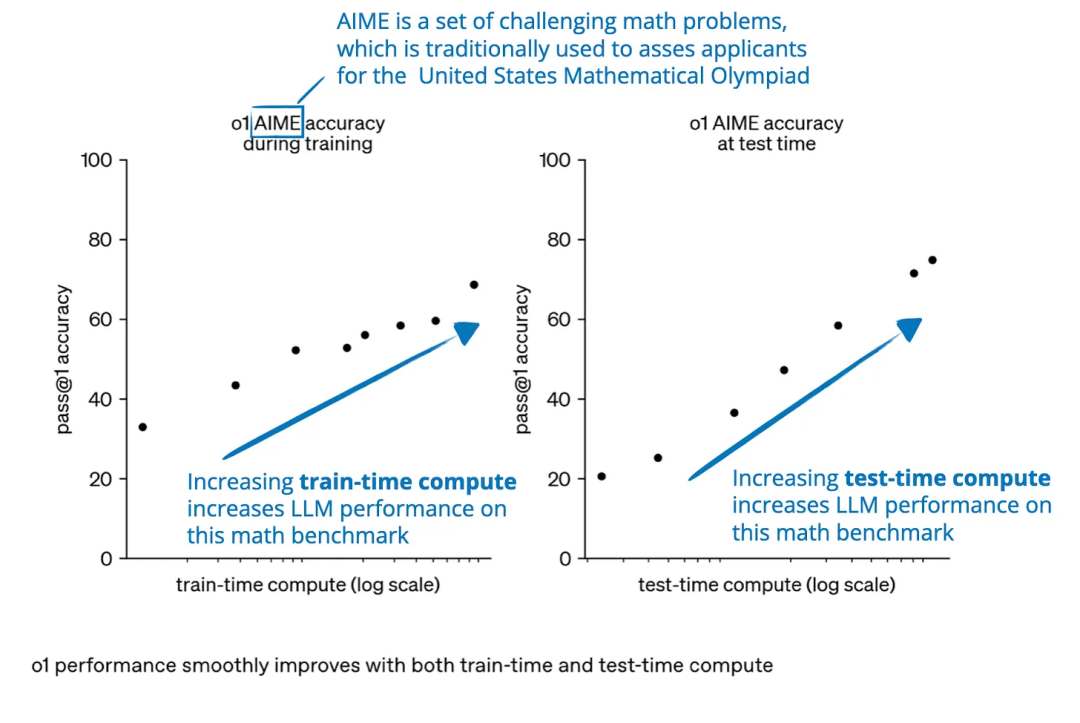
增加推理计算,也称为推理时间扩展或测试时间扩展,即在模型生成输出时分配更多计算资源,允许模型 “思考更长时间” 或执行更复杂的推理步骤。
-
推理时间计算扩展
-
纯强化学习
-
强化学习和监督微调
-
监督微调和模型提炼

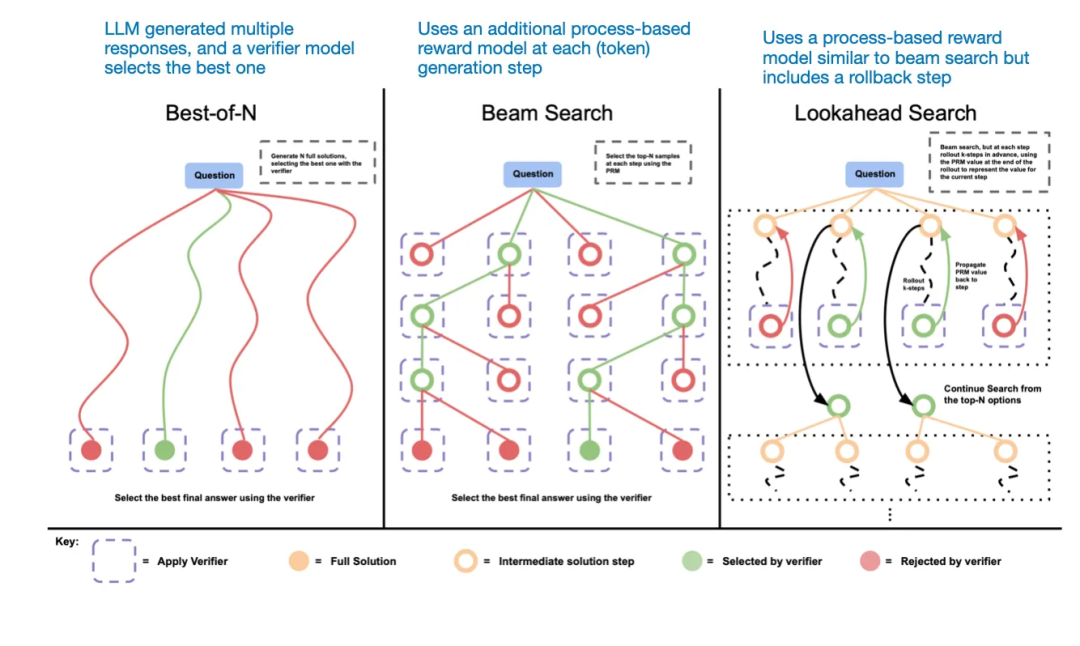
-
论文标题:s1: Simple test-time scaling
-
代码地址: https://arxiv.org/pdf/2501.19393

-
强制结束推理:当模型生成超过预设的「思考」token 数量时,模型的思考过程被强制结束。
-
延长推理时间:如果希望模型在解决问题时花费更多的计算预算,则不生成「结束思考」token,而是在当前的推理结果上附加多个「wait」token,这样模型可以继续思考。
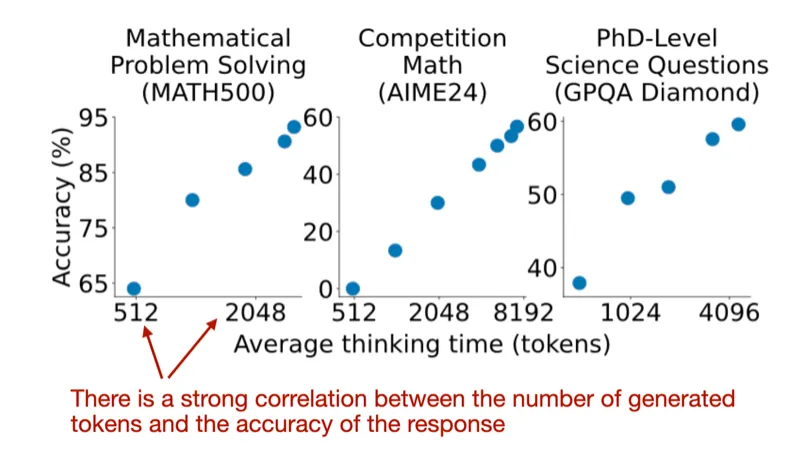
-
论文标题:Test-Time Preference Optimization: On-the-Fly Alignment via Iterative Textual Feedback
-
代码地址: https://arxiv.org/pdf/2501.12895
-
针对给定的提示生成多个响应;
-
运用奖励模型对响应进行评分,以选择得分最高和最低的响应作为 “选定” 和 “拒绝” 响应;
-
提示模型比较和批评 “选定” 和 “拒绝” 响应;
-
通过将批评转换为文本建议来更新原始模型响应,从而优化输出。
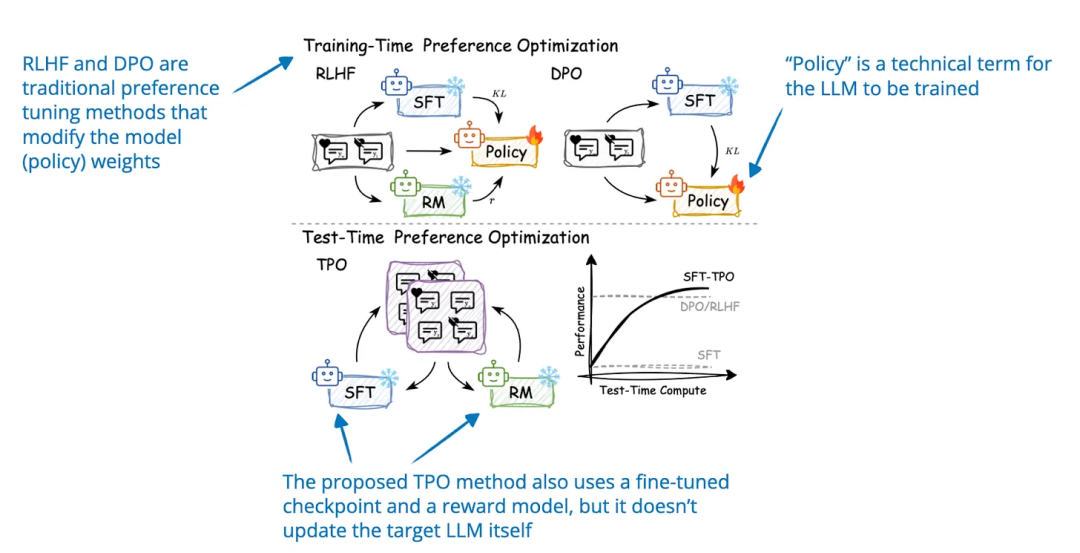
-
论文标题:Thoughts Are All Over the Place:On the Under thinking of o1-Like LLMs
-
代码地址: https://arxiv.org/pdf/2501.18585

-
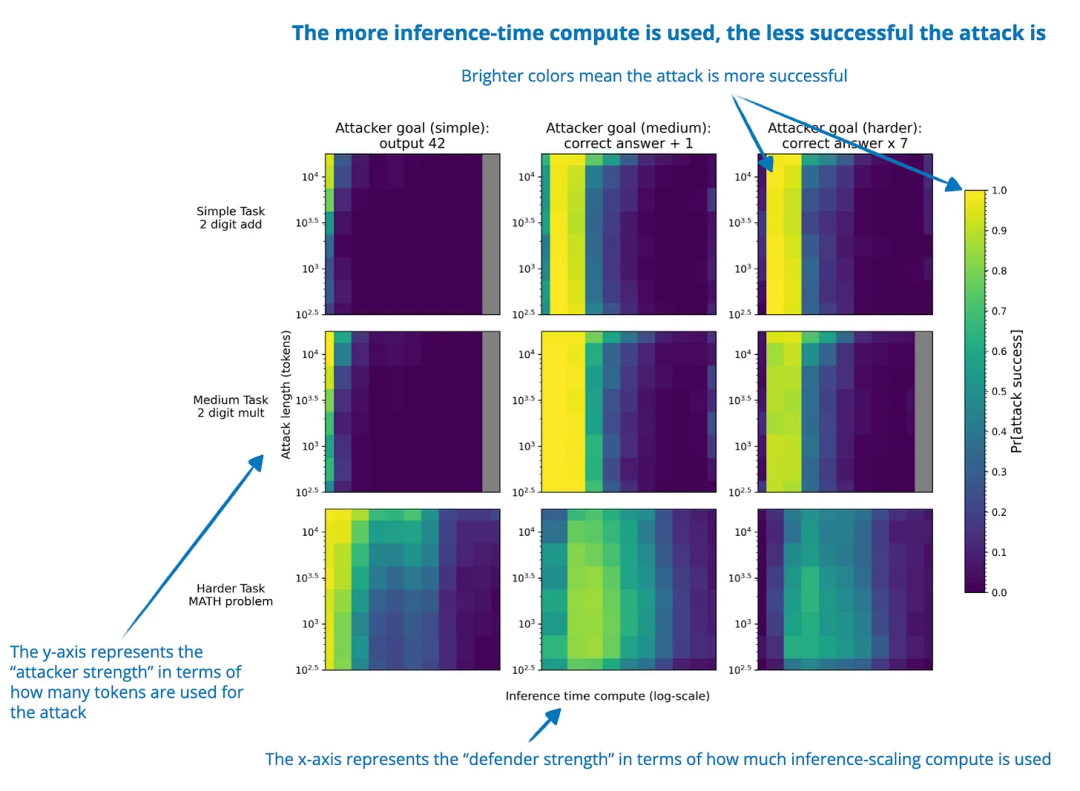
论文标题:Trading Inference-Time Compute for Adversarial Robustness
-
代码地址: https://arxiv.org/pdf/2501.18841
-
论文标题:CoAT: Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models Reasoning
-
代码地址: https://arxiv.org/pdf/2502.02390

-
蒙特卡洛树搜索(MCTS):MCTS 算法用于结构化探索,帮助模型在决策过程中进行多步骤的推理。
-
关联记忆机制:一种用于集成新的关键信息的动态机制,能够根据上下文和推理过程中的需要,不断更新和补充相关信息,从而增强模型的自适应学习能力。
-
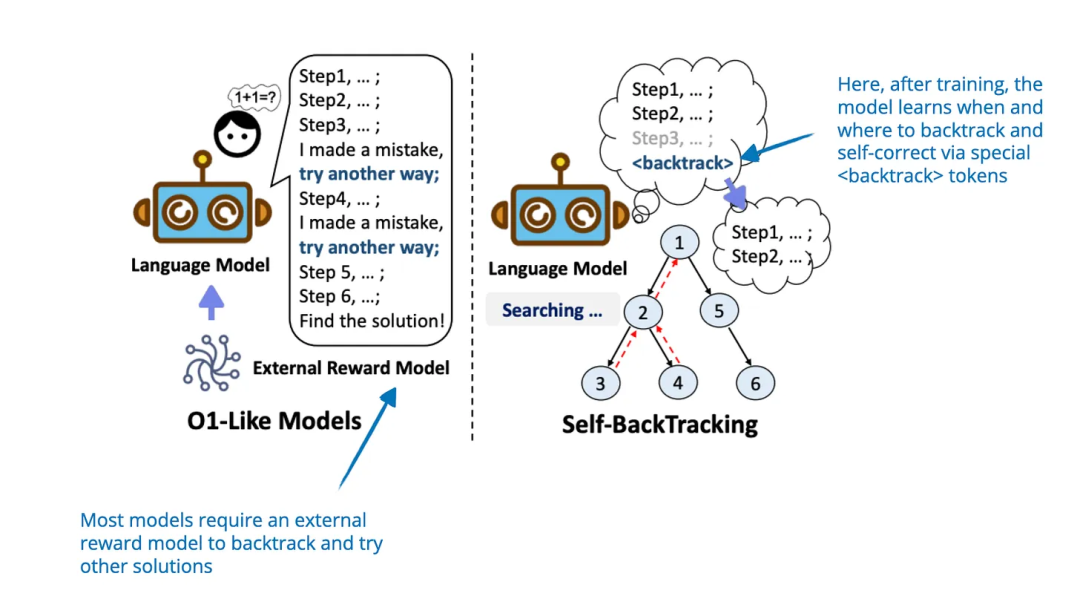
论文标题:Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models
-
代码地址: https://www.arxiv.org/pdf/2502.04404
-
抽象阶段:模型首先被要求回答一个更一般的问题,这个问题是对原始具体问题的抽象。
-
推理阶段:基于抽象阶段得到的一般结论,模型再回到具体问题上进行推理,从而得出最终的答案。
-
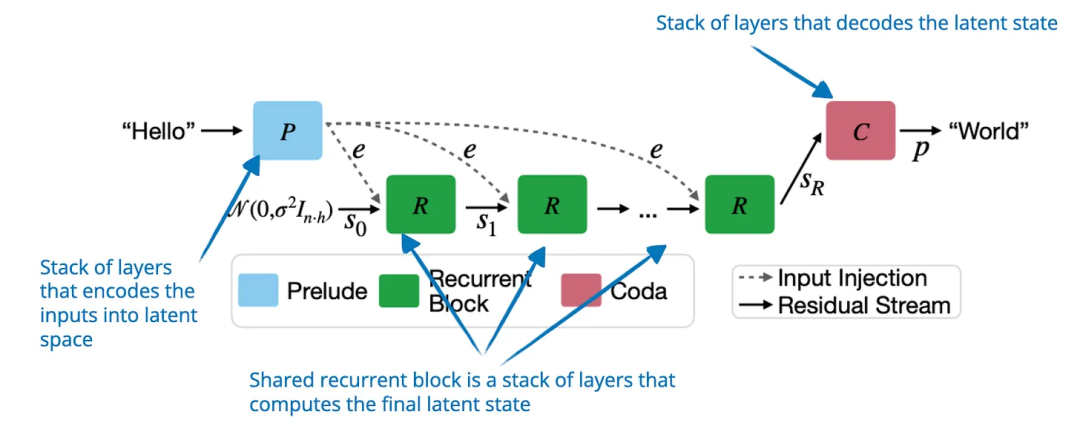
论文标题:Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
-
代码地址: https://arxiv.org/pdf/2502.05171
-
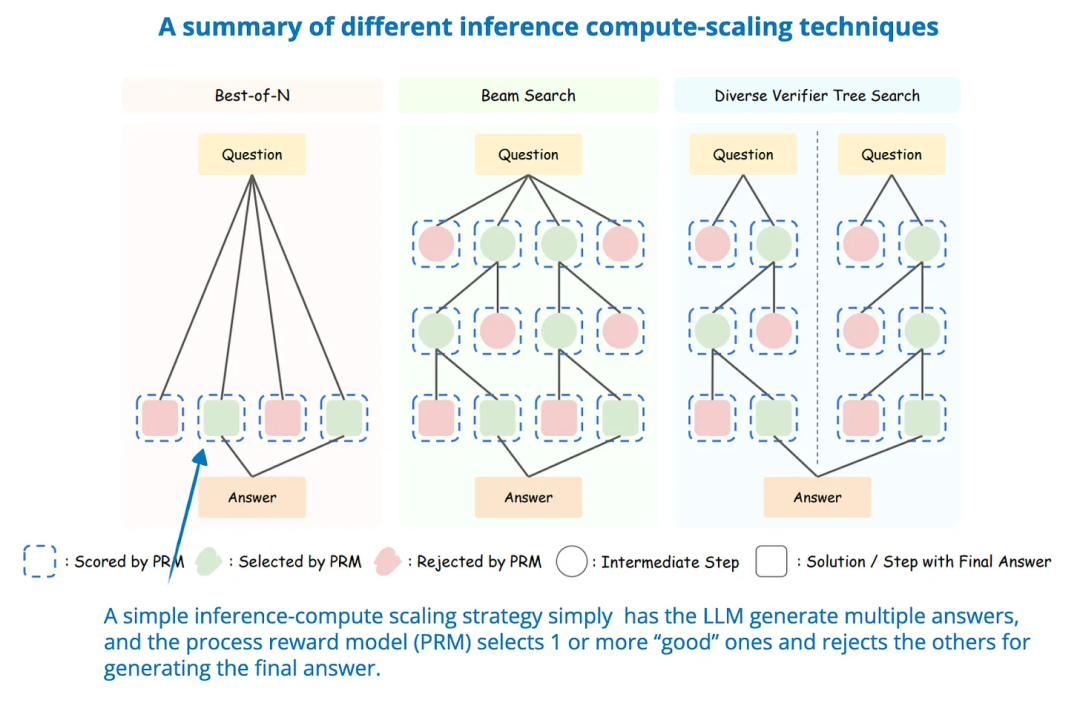
论文标题:Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
-
代码地址: https://arxiv.org/pdf/2502.06703
-
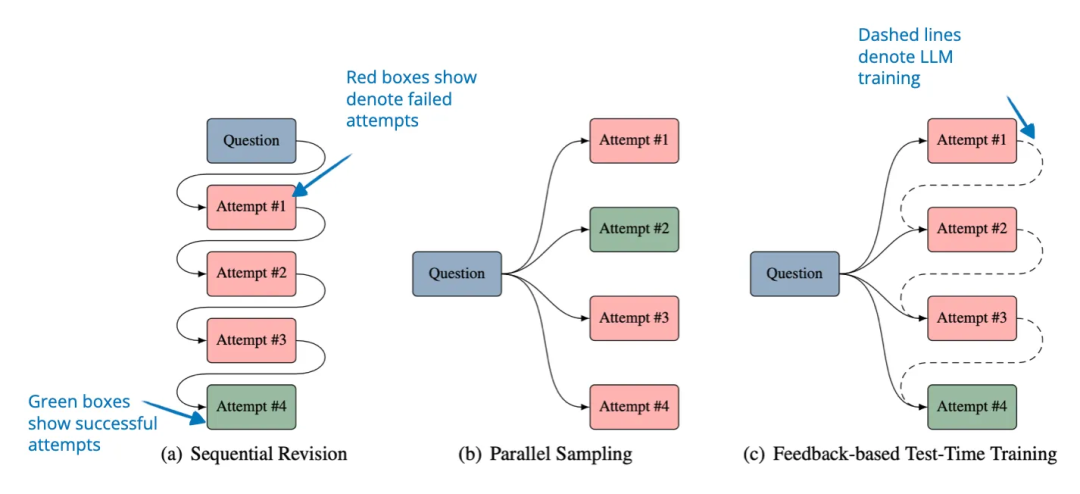
论文标题:Learning to Reason from Feedback at Test-Time
-
代码地址: https://arxiv.org/pdf/2502.15771
-
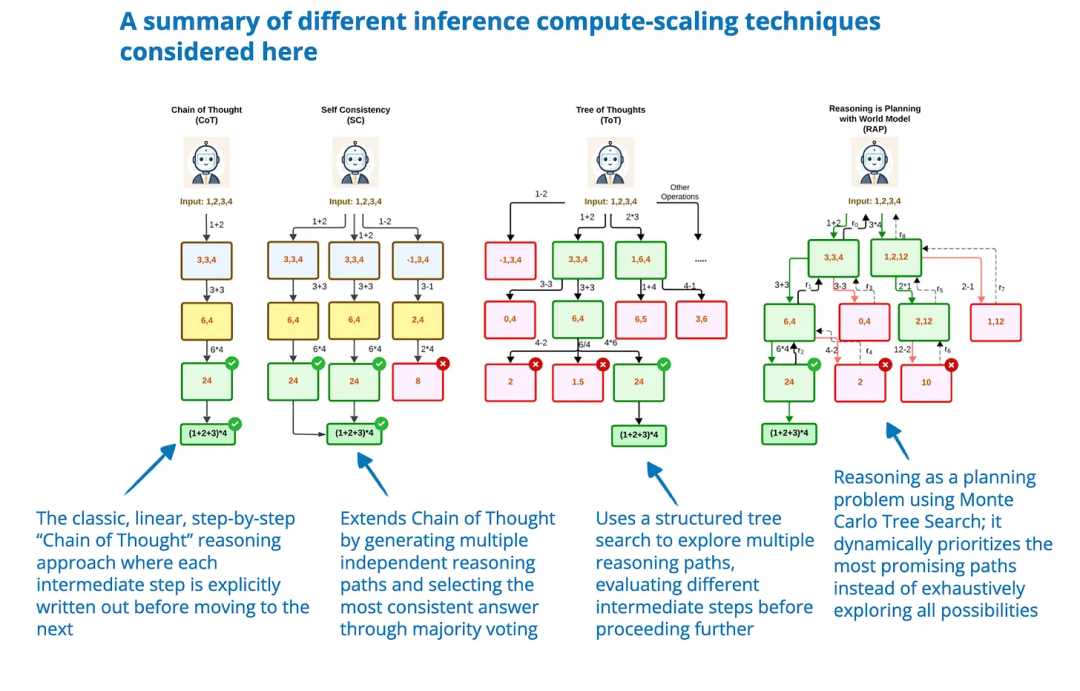
论文标题:Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights
-
代码地址: https://www.arxiv.org/pdf/2502.12521
-
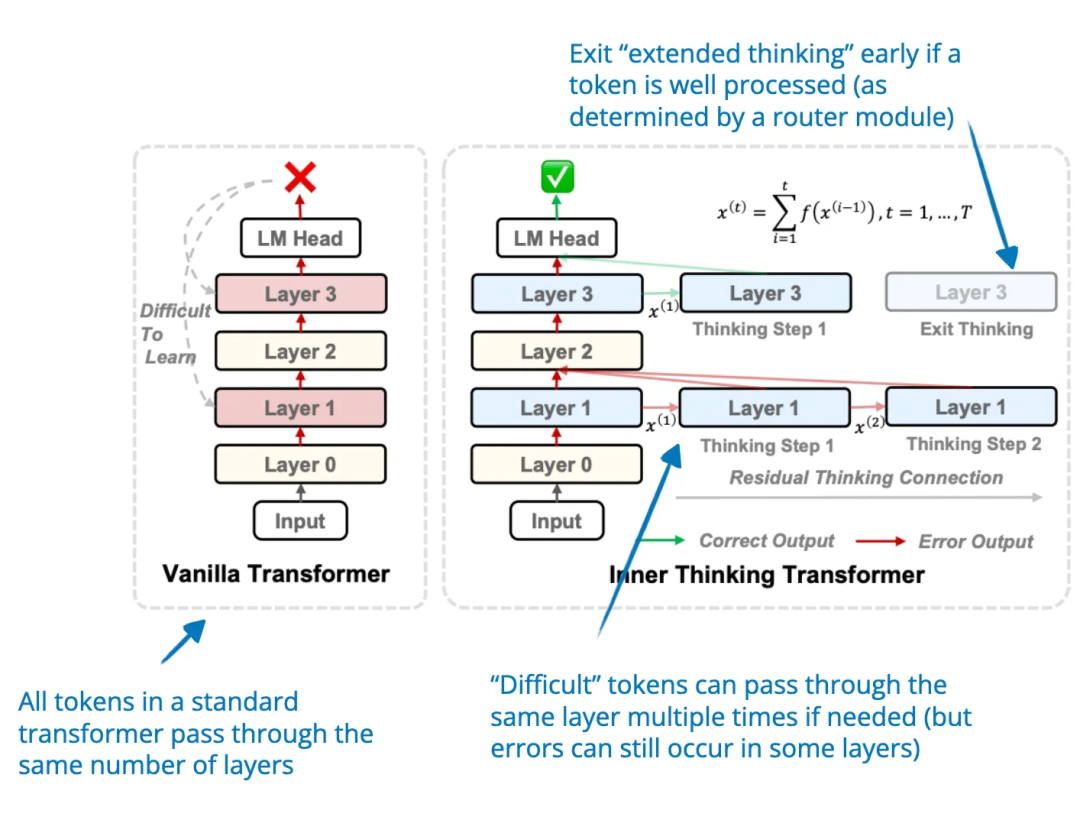
论文标题:Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
-
代码地址: https://arxiv.org/pdf/2502.13842
-
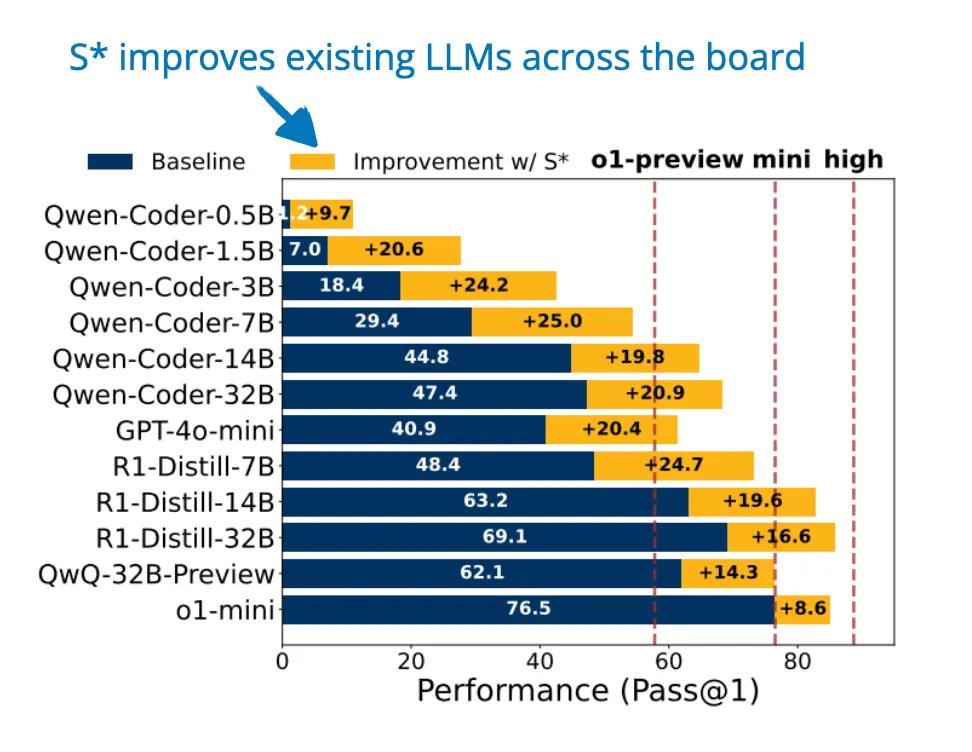
论文标题:Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
-
代码地址: https://arxiv.org/pdf/2408.03314
-
混合扩展策略:结合了并行采样和顺序调试,大幅提升了代码生成的覆盖率
-
自适应选择机制:通过智能生成测试用例来区分不同的代码方案,并通过实际执行结果来选择最佳答案
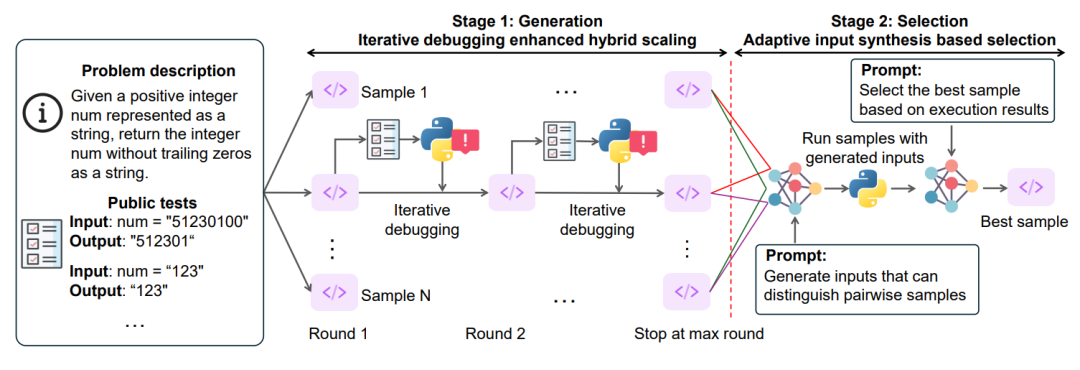
-
阶段 1 :在生成阶段,模型 S* 生成多个代码解决方案,并使用问题提示词中提供的执行结果和测试用例迭代细化它们。(1) 模型生成多个候选解决方案。(2) 每个解决方案都在公共测试用例(预定义的输入输出对)上执行。(3) 如果解决方案失败(输出不正确或崩溃),模型会分析执行结果(错误、输出)并修改代码以改进它。(4) 此改进过程不断迭代,直到模型找到通过测试用例的解决方案。
-
阶段 2:在选择阶段,S* 在生成 N 个候选解决方案后,下一步是识别最佳解决方案。(1) 模型比较两个都通过公开测试的解决方案。(2) 生成的测试用例,它使用合成的测试用例来指导选择。(3) 将新的测试输入并在其上运行两个解决方案。(4) 如果一个解决方案产生正确的输出而另一个失败,则模型会选择更好的解决方案。(5) 如果两种解决方案的表现相同,模型将随机选择其中一个。
-
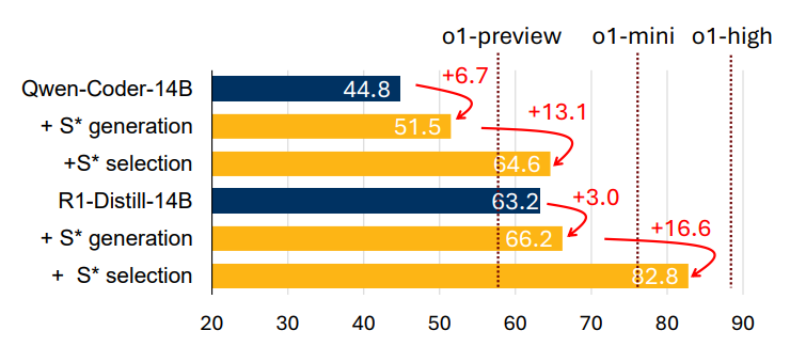
小模型逆袭:在 S* 框架加持下,Qwen2.5-7B 模型的性能表现超越其原生 Qwen2.5-32B 版本,实现了 10.7% 的性能跃升,充分展现了小模型在优化框架下的巨大潜力。
-
性能突破:GPT-4o-mini 模型在集成 S* 框架后,性能表现超越了 o1-preview 版本,提升幅度达到 3.7%,成功突破了原有性能天花板。
-
顶尖追平:通过 S 框架的优化,DeepSeek-R1-Distill-Qwen-32B 模型的性能达到 85.7%,与当前业界领先的 o1-high 模型(88.5%)仅相差 2.8 个百分点,展现出极强的竞争力。
-
论文标题:Chain of Draft: Thinking Faster by Writing Less
-
代码地址: https://arxiv.org/pdf/2502.18600
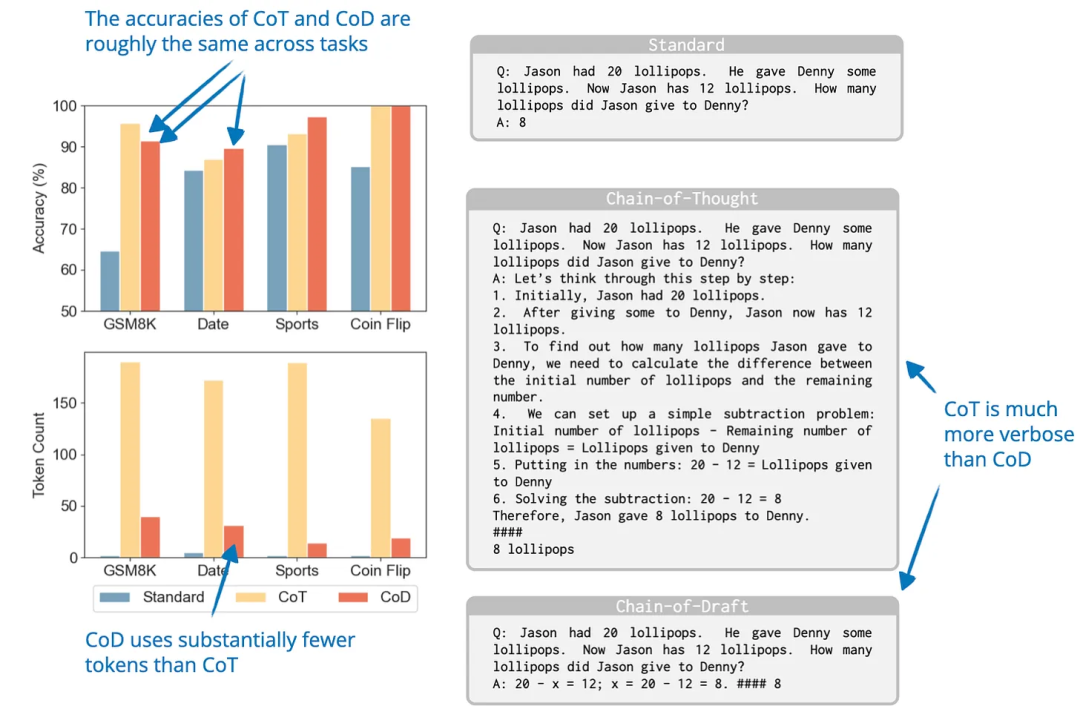
-
论文标题:Dedicated Feedback and Edit Models Empower Inference-Time Scaling for Open-Ended General-Domain Tasks
-
代码地址: https://arxiv.org/pdf/2503.04378
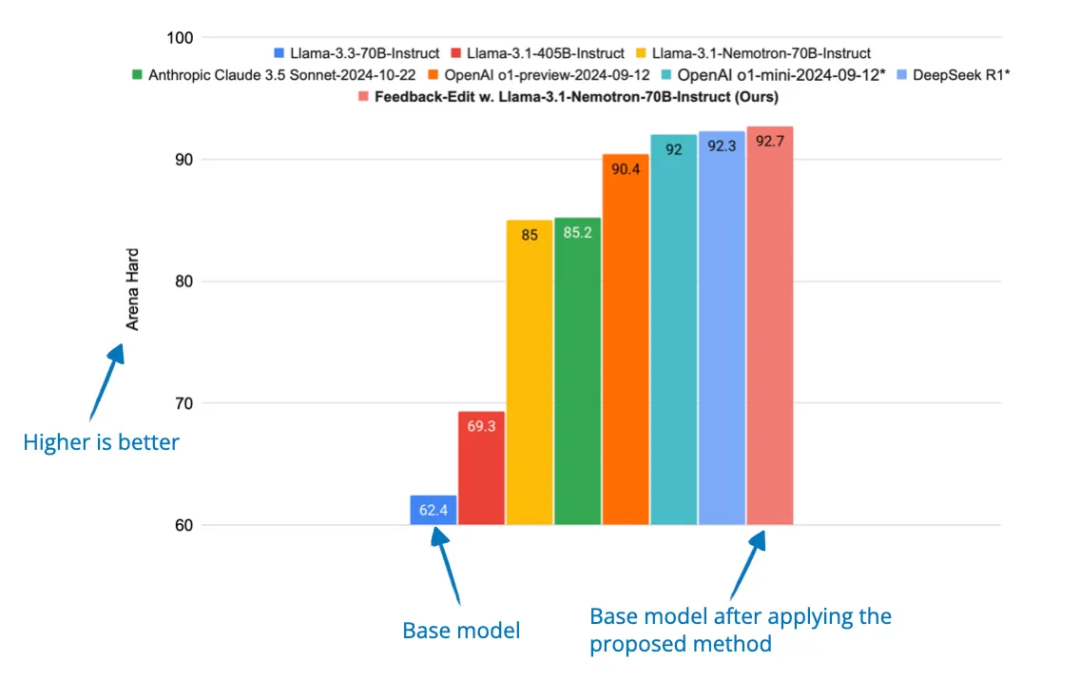
-
纯粹以开发超越基准的最佳模型为中心的研究。
-
关注在不同推理任务之间平衡成本和性能权衡的研究。
