OpenAI等AI模型的快速发展离不开算力基础设施的支撑。文章深入探讨了大模型训练的流程、挑战与未来趋势,并分析了算力瓶颈与硬件需求。
原文标题:不会吧!OpenAI 发布新 O3 和 4o-mini,居然得看算力基础设施的脸色?
原文作者:AI前线
冷月清谈:
怜星夜思:
2、文章提到了Transformer架构在数据效率上的瓶颈,你认为未来有哪些可能的算法创新可以突破这个瓶颈?
3、文章最后提到了万卡集群中系统层面的瓶颈,包括计算、存储、通信、能源等多维度挑战。对于国内团队来说,在构建万卡集群时,你认为应该优先解决哪个问题?为什么?
原文内容

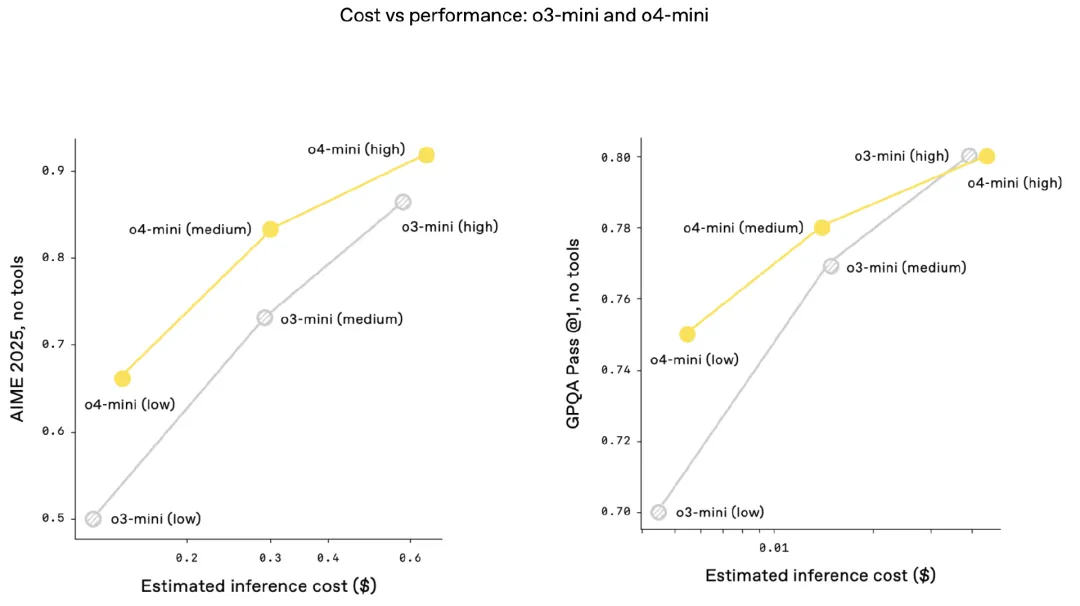
2025 年 4 月伊始,正值中国清明假期,太平洋彼岸的 Meta 公司便发布了 Llama 4 模型。该模型参考了 DeepSeek 的技术,采用 FP8 精度训练的 MoE 架构,并且是训练原生的多模态模型。此次发布包含两种尺寸的模型,尽管如此,其实际测试效果却不尽如人意,这在 AI 圈内引发了轩然大波。紧接着,Google 推出了 A2A 协议(Agent2Agent),旨在解决未来多智能体之间如何沟通协作的问题。一时间,关于 MCP 与 A2A 是否可替代、能否互竞的讨论再度升温。4 月 16 日,OpenAI 再接再厉,正式发布了两款全新的人工智能推理模型,o3 与 o4-mini,开启 AI“看图思考”能力。
将时间线稍微拉长,回溯到 2025 年春节以来的短短数月,足以让我们深切感受到 AI 领域变化之迅猛。曾经的“各领风骚三五月”,如今已缩短为“只领风骚两三周”的节奏,并且这种加速的趋势仍在持续。
-
模型方面:
-
LLM 与多模态领域: 阿里的 Qwen 系列、Google 的 Gemini 系列、OpenAI 的 GPT 系列,以及 DeepSeek 的多篇前沿论文(如 NSA、GRM)和 KIMI 与 DeepSeek“撞车”的 MoBA 模型,纷纷“你方唱罢我登场”,各展风采。
-
AI4S、具身智能等方向: 虽然探索从未停歇,但与大语言模型领域不同,尚未收敛到一个统一的架构上持续深化、优化,仍在时序模型、图神经网络(GNN)、图注意力网络(GAT)、扩散模型、时空变换网络(STTN)等多个方向持续探索。
-
类 Sora 文生视频模型: 包括快手的可灵、字节的即梦、阿里的万象等,基本都围绕扩散模型范式展开,发展节奏介于 LLM 和 AI4S 之间。国内传媒院校以及奥美等 4A 级广告公司也开始涉足应用,抖音、快手等平台上已有大量 AI 生成的短视频,其观看流量迅速增长。看似“百花齐放春满园”,实际满园一种花。
-
智能体方面:
-
继 Open AI 发布 DeepResearch,Google 和 xAI 也发布了各自对标的 DeepSearch 后,真正将 Agent 热潮点燃的是 Monica 与 3 月 6 日凌晨发布的 Manus。紧接着,开源复刻的 OpenManus、OWL 相继问世,并进一步带动了 MCP(Model Context Protocol)及智能体间通信协议(如 ANP、如 IEEE SA-P3394 标准等)的科普。
-
AI 原生应用方面:
-
腾讯公司低调发布了 IMA 应用(手机应用商店可下载),并迅速在年轻知识工作者中形成了良好的口碑效应。
本文将基于以上快速变化的背景,聚焦于推动 AI 技术飞跃发展背后的关键引擎——大模型训练过程。无论是备受瞩目的 Llama 4 发布、智能体领域协议之争,还是迅速迭代的大模型架构背后,都离不开强大的算力基础设施作为支撑。事实上,当前的人工智能竞赛早已进入到算力驱动时代,算力的规模、效率与稳定性直接决定了大模型迭代速度与效果。
接下来,我们将深入介绍大模型训练的一般流程,探讨其面临的具体挑战、技术细节以及未来发展的关键趋势。
所有的大模型和智能,都离不开算力。而我们离理想中的完美大模型训练系统还很遥远。实际上训练算法团队、模型团队、AIInfra 团队需要深度地融合,逐步实现从百卡、千卡、万卡、十万卡的突破。大模型训练是一个复杂且资源密集的过程,涉及多个阶段:
在这个阶段,模型研究团队通过单点研究完成模型设计,并将大模型部署到集群上进行初步训练。初期可能会遇到数据吞吐、数据对齐等问题,但这些问题通常在模型启动初期就能被发现并解决。例如,数据对齐问题可能导致模型在不同节点上的梯度计算不一致,从而影响训练效果。但是这些问题很快就被发现了,因为在模型启动初期。便开始继续训练。
在研发过程中,大模型团队可能会遇到“灾难性问题”,如隐藏的小 bug 导致集群频繁报错。这些问题需要在不停止训练的情况下“边修边训”来解决。例如,一个隐藏的小 bug 可能导致集群在训练到 40% 时频繁崩溃,这需要团队快速定位问题并进行修复,同时保持训练的连续性。

经过灾难性地边开车边修车的过程,大模型团队会积累丰富的全栈技术,使得复刻下一个版本的大模型变得更加高效。例如,DeepSeek 从 V1、V2、V3、R1 的过程,模型能力的加速会越来越快;OpenAI 的模型从 GPT-4 至 GPT-4.5 的模型能力提升约为 10 倍,获得了“难以量化但全方位增强的智能”。在这个阶段,团队通常会优化模型架构和训练算法,以提高训练效率和模型性能。
在经历了模型能力的加速期后,会发现 Scaling Law(规模定律)依然发挥着重要作用。要实现下一个 10 倍乃至百倍的性能提升,关键在于数据效率,即能够利用更多算力,从同样数量的数据中学到更多知识的方法。
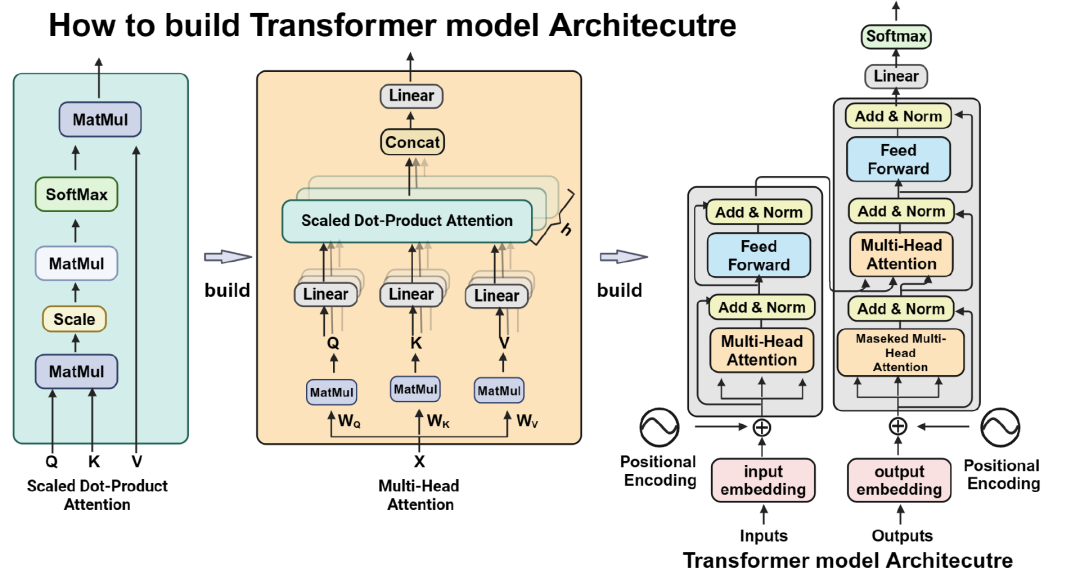
Transformer 架构之所以广泛应用,是因为它在利用数据方面非常高效,能够吸收和压缩信息,并实现泛化。它最大的特点就是能用计算资源高效地吸收信息。 然而,其潜在瓶颈也逐渐凸显出来:
-
Transformer 从数据中获得有用信息的深度是有限的,当计算能力快速增长,而数据增长相对缓慢时,数据就会成为这种标准模式的瓶颈。这就需要算法创新,开发出能够利用更多算力从同样数量的数据中学到更多知识的方法。
-
Transformer 架构的一个主要优势是其在数据效率方面的表现。它能够通过 Self Attention 自注意力机制有效地捕捉长距离依赖关系,从而在处理大规模数据集时表现出色。然而,随着模型规模的增加,数据效率的提升变得越来越困难。例如,一个拥有 1000 亿参数的模型可能需要数百万个训练样本才能达到最佳性能,而数据的增长速度往往无法跟上模型规模的增长。
-
在训练过程中,损失曲线的监控是确保模型正常运行的关键。通过实时监控 Loss 损失曲线,可以及时发现训练过程中的异常趋势,并采取相应的优化措施。例如,如果损失曲线在训练过程中出现波动,可能是因为权重数据在多卡之间分布不均匀导致计算聚合的时候溢出,这种问题其实在 infra 层面排查是挺困难的,算法上看上去没什么问题。
除了上述内容,我们还需要持续优化整个大模型的训练系统,弥补训练启动前算法团队和 Infra 团队未能完成的协同设计(co-design)。例如密切监控训练过程中的各类统计指标,确保不会出现预期外的异常情况。
此外,除了数据和算力的增长,Transformer 架构中的算法改进对性能的影响也是叠加式的。每次算法性能提高 10% 或 20%,叠加在数据效率上就会带来显著的提升效果。目前能看到的是 OpenAI 和 DeepSeek 正在进入 AI 研究的新阶段,将开始积累数据效率方面的成果。
事实上,在大规模并行集群,也就是到万卡和十万卡的 AI 集群上会遇到的许多问题,并非规模扩大后才出现,而是从一开始就存在的。这些问题大多在小规模阶段就能被观察到,只是随着规模扩大,它们会演变成灾难性问题。
-
预训练与强化学习的数据矛盾。 预训练数据集通常追求广度和多样性。但当涉及模型强化学习,也就是 LLM+RL 时,若要让模型获得清晰的奖励信号 Reward 和良好的训练环境,就很难同时保持数据集的广度。预训练本质上是一个数据压缩的过程,旨在发现不同事物之间的联系。它更侧重于类比和抽象层面的学习。而推理 Reasoning 则是一种需要谨慎思考的特定能力,能够帮助解决多种类型的问题。通过跨领域的数据压缩,预训练模型能够掌握更高层次的抽象知识。
-
Scaling Law 尚未触及理论极限。从机器学习和算法发展的角度来看,我们尚未触及明确 Scaling Law 和 Transformer 架构的理论上限。不同代的模型架构(或者说不同参数规模的模型)本质上是模型规格演进的必然结果。例如,我们无法简单地用 30B 模型的架构和数据量直接训练一个 160B 的模型。当计算需求超出单集群的承载能力时,就不得不转向多集群训练架构,所以现在出现了很多 AIInfra 研究异构场景的技术点。
构建万卡甚至十万卡规模的集群系统并非最终目标,真正的核心在于其实际产出价值——即能否训练出一个优秀的大模型。OpenAI 已经跨过了大模型训练的四个阶段,进入了一个新的算力纪元。对于 OpenAI 和 DeepSeek 这样的团队来说,计算资源已不再是主要瓶颈。这一转变对行业和公司自身的影响是深远的,毕竟从 2022 年开始,进入了百模型大战,到 DeepSeek 出来大杀四方这段时间期间,大部分算法和模型厂商来说都是长期处于计算资源受限的环境中。
那么在万卡集群的整体层面,什么会限制进行模型大规模训练?是芯片、处理器、内存、网络还是电源?既然国内很多团队处于转型阶段,那么对芯片、处理器等的需求是什么?
在大模型训练过程中,系统层面的瓶颈并非单一因素所致,而是计算、存储、通信、能源等多维度的综合挑战。也就是对于大模型来说,AIInfra 扮演着重要的角色。
计算芯片(如 GPU/TPU)的性能直接影响训练效率,包括算力密度(TFLOPS)、显存容量(如 HBM 带宽)和高速互联能力(NVLink/RDMA)。例如,千亿参数模型的训练需要 TB 级显存存储参数和中间状态,而显存带宽不足会导致计算单元闲置,形成"内存墙"。此外,随着模型规模扩大,单集群的计算能力可能无法满足需求,迫使团队转向多集群架构,此时状态同步和通信开销成为新瓶颈。
内存系统的优化同样关键。除了显存,主机内存(DRAM)和存储(SSD/HDD)的层级协同也影响数据吞吐。例如,训练过程中的检查点(checkpoint)保存和加载需要高效的内存管理,而存储 I/O 延迟可能拖慢整体流程。因此,现代训练系统需要显存、内存和存储之间的带宽匹配,避免某一环节成为短板。
在大规模分布式训练中,网络通信往往是主要瓶颈之一。AllReduce 等集合操作需要高效的跨节点数据传输,而低带宽或高延迟的网络(如传统以太网)会导致同步时间大幅增加。当前,800Gbps RDMA 网络正在成为超算集群的标配,但拓扑设计(如 Dragonfly、Fat-Tree)和通信调度算法(如拓扑感知的 AllReduce)仍需优化,以避免网络拥塞。
此外,多集群训练引入了更复杂的通信问题。例如,跨数据中心的训练可能受限于广域网(WAN)带宽,而一致性协议(如参数服务器的同步策略)的选择会影响训练稳定性和速度。因此,国内团队在构建万卡级集群时,不仅需要高速互联硬件,还需软件层面的通信优化,如梯度压缩、异步训练等。
随着计算密度提升,电源和散热成为不可忽视的限制因素。单机柜功率已从传统的 10kW 提升至 30kW 以上,而风冷散热效率接近极限,液冷技术(如冷板、浸没式)逐渐普及。这不仅涉及硬件改造(如供电冗余、冷却管路设计),还需软件层面的功耗管理,如动态电压频率调整(DVFS)和任务调度优化,以降低整体能耗。
在算力受限情况下,通过低精度训练(FP8/BF16)、动态稀疏化等技术提升硬件利用率。万卡级集群的稳定性要求硬件级容错(如自动恢复)、全局内存一致性(CXL 技术)等特性。目前,行业正在探索 3D 封装、存算一体、光互联等新技术,以突破传统架构限制。

总的来说,大模型训练的瓶颈本质是系统级的挑战,需从芯片、网络、能源到软件栈的全栈优化。当前的算力基础设施对大模型训练起到关键性作用,而我们离理想中的完美大模型训练系统还很遥远。
AICon 2025 强势来袭,5 月上海站、6 月北京站,双城联动,全览 AI 技术前沿和行业落地。大会聚焦技术与应用深度融合,汇聚 AI Agent、多模态、场景应用、大模型架构创新、智能数据基建、AI 产品设计和出海策略等话题。即刻扫码购票,一同探索 AI 应用边界!

