本文详细解读了LIME、SHAP、Kernel SHAP 和Deep SHAP四种机器学习模型可解释性算法,帮助读者理解模型决策过程。
原文标题:原创 | 机器学习模型的可解释性(二)
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、SHAP值在特征重要性排序上相比于传统的特征重要性评估方法(如基于树模型的特征重要性)有哪些优势和劣势?
3、Kernel SHAP作为LIME的改进版本,它主要解决了LIME的哪些问题?它在实际应用中又存在哪些局限性?
原文内容

作者:宋雨婷本文约3300字,建议阅读6分钟本文对LIME、SHAP、Kernel SHAP 和Deep SHAP作了详细解读。
文章的第一部分“”中介绍了内部可解释模型,本文着重解释事后可解释性分析模型,重点介绍目前对于模型可解释性的常见模型,如:LIME、SHAP、Kernel SHAP 和Deep SHAP。
事后可解释性分析方法通常会用到内部可解释模型,用内部可解释模型去解释黑箱。对于一个黑箱,如果我们可以说出在这个模型中,哪个变量是最重要的,哪个变量是无关紧要的,在一定程度上,就可以解释这个模型。LIME和SHAP可以做到。
LIME
LIME 算法的核心思路是,在底层模型的局部拟合一个可解释的线性模型,利用该线性模型拟合局部的模型变化,进而在这个局部对底层模型进行解释。
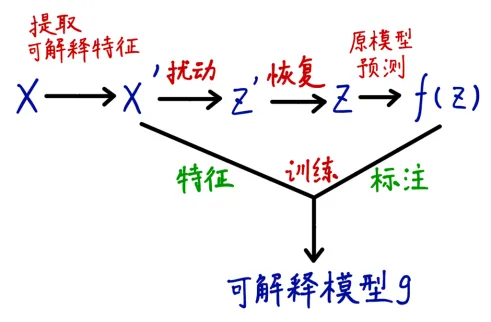
LIME的操作流程:先假设局部点为d维向量![]() ,提取X中的所有非零元素组成X’,从X’这个点开始的。通过对X’的非零元素进行随机采样来生成扰动样本z’,进而恢复到原始表示z并调用底层模型获取f(z)作为标签用于训练解释模型。过程如下图:
,提取X中的所有非零元素组成X’,从X’这个点开始的。通过对X’的非零元素进行随机采样来生成扰动样本z’,进而恢复到原始表示z并调用底层模型获取f(z)作为标签用于训练解释模型。过程如下图:
![]()
想象一下,假设一个线性模型中有成千上万个变量,每个变量都会对响应变量产生影响,此时,即使各个变量前![]() 的
的![]() 是已知的,用户已经很难取理解这个线性模型。因此,在LIME的训练中,我们对这个局部线性模型通常有两点要求,一是它需要能够尽量精准的去刻画底层模型,二是它不可过于复杂,因此,最小化的目标函数如下:
是已知的,用户已经很难取理解这个线性模型。因此,在LIME的训练中,我们对这个局部线性模型通常有两点要求,一是它需要能够尽量精准的去刻画底层模型,二是它不可过于复杂,因此,最小化的目标函数如下:
![]()
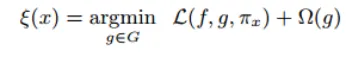
前者代表局部不可信度,后者代表可解释模型的复杂度。在这个式子里,f是底层函数,g是解释函数,![]()
![]() 是通过扰动生成的点距离初始点的距离(试想,更近的点可以更好地表达出初始点附近的情况)。
是通过扰动生成的点距离初始点的距离(试想,更近的点可以更好地表达出初始点附近的情况)。
然而,![]()
![]() 作为模型复杂度通常是训练前设置好的超参数(如决策树的深度、线性模型非零权重的数量等),若想要求解最优值,通常只能枚举,因此,LIME算法将问题转化为最小化
作为模型复杂度通常是训练前设置好的超参数(如决策树的深度、线性模型非零权重的数量等),若想要求解最优值,通常只能枚举,因此,LIME算法将问题转化为最小化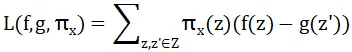
![]() ,并利用K-Lasso进行稀疏性控制。LIME适用于多个场景。对于文本数据,原始的词向量通常难以解释,LIME 采用词袋模型,将文本样本转换为可解释特征。在词袋模型中,只关注单词是否出现,用 0 或 1 来表示。对于图像数据,直接在像素层面进行扰动比较困难,所以需要设计特定的扰动范式。通常采用对原图像进行聚类的方法,将图像分成多个分块(假设分成 K 块),每一块有存在或不存在两种状态,这样可以生成
,并利用K-Lasso进行稀疏性控制。LIME适用于多个场景。对于文本数据,原始的词向量通常难以解释,LIME 采用词袋模型,将文本样本转换为可解释特征。在词袋模型中,只关注单词是否出现,用 0 或 1 来表示。对于图像数据,直接在像素层面进行扰动比较困难,所以需要设计特定的扰动范式。通常采用对原图像进行聚类的方法,将图像分成多个分块(假设分成 K 块),每一块有存在或不存在两种状态,这样可以生成![]()
![]() 个样本。不同的值可以适应不同的情况,既可以使解释更详细(较大),也可以使解释更简洁(较小)。
个样本。不同的值可以适应不同的情况,既可以使解释更详细(较大),也可以使解释更简洁(较小)。
SHAP
SHAP 模型的核心是 Shapley 值。它采用了 Shapley 值的概念来解释机器学习模型中的特征重要性。Shapley值最初来源于博弈论。在多人联盟博弈的场景中,多个参与者组成联盟来进行博弈。
从一个例子说起,联合国安理会有 15 个理事国,其中包括 5 个常任理事国和 10 个非常任理事国。一项决议草案要在安理会通过,需要至少 9 个理事国的赞成票,并且这 9 票中必须包含全部 5 个常任理事国的赞成票。
假设一个非常任理事国 A,在前期各方投票意向不明朗时,如果常任理事国中有 4 个已经确定支持该决议,而剩下 1 个常任理事国和一些非常任理事国还在犹豫。此时非常任理事国 A 决定支持该决议,并且通过它的外交努力,拉拢了其他几个非常任理事国一起支持,最终使得决议获得通过(达到 9 票且包含 5 个常任理事国)。那么非常任理事国 A 在这个博弈过程中的 Shapley 值就较高,因为它的加入和努力对决议的通过起到了关键的边际贡献。虽然它是一个相对 “小” 的理事国,但在这个联盟博弈场景下产生了重大影响。
相反,如果一个非常任理事国 B 在大多数理事国已经确定投票方向后才决定支持,它对决议通过的边际贡献就小,其 Shapley 值也就较低。
Shapley 值反映了在这种联盟博弈中,当某一个人加入联盟时,对最终博弈决策所带来的边际贡献。
在机器学习中,Shaply值也就是,当一个特征被模型考虑,对模型预测结果带来的边际影响。计算公式如下:
![]()
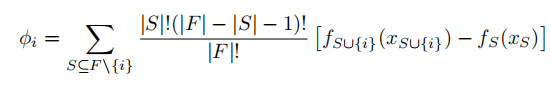
公式中,后者是计算包含特征和不包含特征时模型预测的差异,即特征在这个特定的特征子集组合下对模型预测的边际贡献。前者作为系数,用于对每个特征子集的贡献进行加权。其中,|S|是特征子集的大小,|F|是所有特征集合的大小。
将计算得到的![]() 带入到可加特征归因方法,可加特征归因方法公式定义如下:
带入到可加特征归因方法,可加特征归因方法公式定义如下:
![]()

倘若我们想要可加特征归因方法去尝试解释底层模型,为保障解释效果,模型理应满足局部准确性、缺失性和一致性等理想性质,从而避免一些其他方法可能出现的违反这些性质导致的不直观行为。
局部准确性是指对于任意一个数据样本x,原始模型的预测结果g(x)等于基于SHAP值构建的解释模型的预测结果。公式表达为:![]()
![]()
缺失性是指如果一个特征i在数据样本中不存在(即xi的值为缺失值),那么该特征的SHAP值![]() 为 0。公式表示为:
为 0。公式表示为:![]()
![]()
一致性是指如果两个模型f和f’满足对于任意特征子集S,都有![]()
![]() ,那么在这两个模型中,特征i的SHAP值和满足
,那么在这两个模型中,特征i的SHAP值和满足![]()
![]() 。一致性保证了 SHAP 值随着模型对特征的依赖性增加而单调增加。公式表示为:
。一致性保证了 SHAP 值随着模型对特征的依赖性增加而单调增加。公式表示为:
![]()
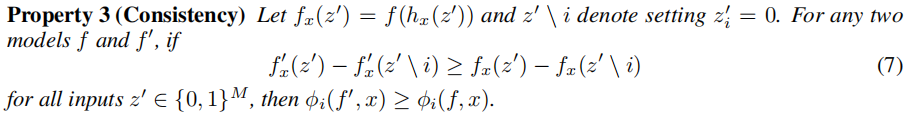
经过推导,在可加特征归因方法中,要满足这三条性质,则特征重要性度量![]()
![]() 是唯一的,这个唯一的度量就是SHAP值。公式表示为:
是唯一的,这个唯一的度量就是SHAP值。公式表示为:
![]()
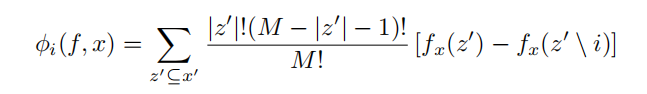
所有不包含特征i的集合共有![]()
![]() 个,这使得SHAP 值的精确计算具有挑战性。由于大多数模型无法处理任意模式的缺失输入值,我们用
个,这使得SHAP 值的精确计算具有挑战性。由于大多数模型无法处理任意模式的缺失输入值,我们用![]()
![]() 来近似
来近似![]() 。当计算
。当计算![]()
![]() 时,特征独立性和模型线性是简化期望值计算的两个可选假设,在这种假设下,
时,特征独立性和模型线性是简化期望值计算的两个可选假设,在这种假设下,![]()
![]() 可推导:
可推导:
![]()

其中,![]()
![]() 表示不在S中的元素的集合。
表示不在S中的元素的集合。
因此,要计算![]()
![]() ,只需计算
,只需计算![]()
![]() 即可。
即可。
通常,求解SHAP包括模型无关的近似方法(如Shapley sampling values method、equivalently the Quantitative Input Influence method、Kernel SHAP)和特定于模型的近似方法(Linear SHAP、Low-Order SHAP、Max SHAP、Deep SHAP)。
Kernel SHAP
Shapley 值是满足属性1 - 3(局部准确性、缺失性和一致性)的唯一可能解,显而易见,LIME作为一个可加特征归因方法,必然不同时满足这三个属性。那么,一个自然的问题是LIME的解是否能恢复这些值。Kernel SHAP就是LIME方法结合了Shapley方法的改进。答案取决于损失函数L、加权核![]()
![]() 和正则化项
和正则化项![]() 的选择。
的选择。
在Kernel SHAP中,他们的计算如下:
![]()

Deep SHAP
虽然 Kernel SHAP 提高了与模型无关的 SHAP 值估计的样本效率,但通过将注意力限制在特定的模型类型上,可以开发更快的特定于模型的近似方法。DeepSHAP 是一种用于解释深度神经网络预测结果的方法。它避免了 DeepLIFT中需要启发式地选择线性化组件的问题。
DEEP SHAP将DEEPLIFT中的参考值解释为![]()
![]() 中的E[x],那么DeepLIFT在假设输入特征彼此独立且深度模型为线性的情况下近似SHAP值。
中的E[x],那么DeepLIFT在假设输入特征彼此独立且深度模型为线性的情况下近似SHAP值。
DeepLIFT 使用线性组合规则,等同于将神经网络的非线性组件线性化,其反向传播规则是启发式选择的。而 DeepSHAP 从为每个组件计算的 SHAP 值中导出有效的线性化,从而能够快速近似整个模型的 SHAP 值。
基于决策树
Anchor和LIME提出者是同一个人,Anchor也是在针对LIME中存在的一些问题做出改进。不妨看下面这张图,在LIME算法中,对于给定的点x,在其邻域D内理应都是可以应用局部线性模型去解释,然而,观察黄色方框内的区域底层模型的预测结果为“-”,却被解释模型预测成了“+”,而绿色椭圆内底层模型的预测结果为“+”,却被解释模型预测成了“-”。这表明LIME无法确定其解释的范围。与此同时,倘如底层模型的局部非线性,此时用LIME去解释,必然会导致LIME解释的效果不佳。
![]()
![]()
![]()
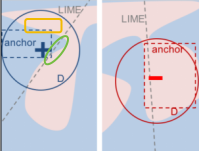
解释”黑箱”的主要思想之一是用一个解释性高的模型去局部模拟底层模型的生成,LIME用的是线性模型。于是,作者提出,用解释性同样很高的IF-THEN规则去局部模拟。IF……,THEN预测分类结果为……。这自然而言的就解决了LIME无法确定其解释的范围,IF后面就是单一Anchor解释的范围。
以下图为例,在文本情感分类的任务里,“This movie is not bad”和“This movie is not very good”是不同的情感,“This”,“ movie”,“ is ”在两句话中均出现了且对文本情感判断结果无较大影响,“not”在两句话中均出现了但带来的影响截然相反,单独出现的“not” 是无法给出解释性的。然而,所有包含“not good”的句子,被模型判断为了negative,所有包含“not bad”的句子,被模型判断为了positive。可以看出,模型判断的结果与句子中的其他单词无关,仅一个特征子集就能锚定一个句子的确切情感。那么,在这个例子里,我们就可以得到两个anchor:1、IF{“not”,”good”} in sentence,THEN predict negative 2、IF{“not”,”bad”} in sentence,THEN predict positive。
![]()

那么,我们该怎么解释底层模型,我们该怎么找到它的anchor呢?对于有n个特征作为输入的底层模型,每个特征都有被选进这个anchor和没被选进两种可能,理论上,一共有![]() 个anchor,直接计算的复杂度很高。因此,作者选择自底向上的贪心算法来尽量减少计算,与此同时,利用UBC算法选择最精确的anchor,并选择最好的一个放到下一轮。对于算法,此处不做过多展开。
个anchor,直接计算的复杂度很高。因此,作者选择自底向上的贪心算法来尽量减少计算,与此同时,利用UBC算法选择最精确的anchor,并选择最好的一个放到下一轮。对于算法,此处不做过多展开。
结论
本文对LIME、SHAP、Kernel SHAP 和Deep SHAP 作了详细解读,这四种算法是机器学习中用到的的比较重要的模型。
作者简介
宋雨婷,苏州大学,未来科学与工程学院数据科学与大数据技术专业在读,对可解释性机器学习、计算机视觉等领域感兴趣。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织