清华大学提出SpargeAttn,一种无需训练的稀疏Attention方法,加速语言、视频、图像等大模型推理,精度无损,提速显著。
原文标题:清华稀疏Attention,无需训练加速一切模型!
原文作者:数据派THU
冷月清谈:
清华大学的研究团队提出了SpargeAttn,一种无需训练即可直接使用的稀疏Attention方法,旨在加速各种模型的推理过程。该方法通过快速预测P矩阵的稀疏部分,并结合GPU Warp级别的稀疏Online Softmax算法,实现了在语言、视频、图像生成等大模型上的加速,同时保持了端到端的精度。SpargeAttn尤其适用于中等长度的上下文,并且通过与SageAttention等方法的融合,可以进一步提高加速效果。实验结果表明,SpargeAttn在多种模型上均能实现显著的加速,且对模型精度没有明显影响。该研究还优化了稀疏预测部分的性能,降低了其开销,使其在各种长度的序列下几乎可以忽略不计。
怜星夜思:
1、SpargeAttn这种无需训练的稀疏Attention方法,在实际应用中,除了文章中提到的语言、视频、图像生成模型,还能应用在哪些其他领域?大家觉得在哪些场景下,这种方法的优势会更加明显?
2、文章提到SpargeAttn通过预测P矩阵的稀疏部分来加速计算,那么这种预测的准确性对最终的加速效果和模型精度有多大影响?如果预测不准,会造成什么后果?
3、文章中提到SpargeAttn与SageAttention融合可以进一步加速,那么这种融合是怎样实现的?除了SageAttention,是否可以和其他Attention加速方法结合?如果可以,大家觉得和哪种方法结合效果会更好?
2、文章提到SpargeAttn通过预测P矩阵的稀疏部分来加速计算,那么这种预测的准确性对最终的加速效果和模型精度有多大影响?如果预测不准,会造成什么后果?
3、文章中提到SpargeAttn与SageAttention融合可以进一步加速,那么这种融合是怎样实现的?除了SageAttention,是否可以和其他Attention加速方法结合?如果可以,大家觉得和哪种方法结合效果会更好?
原文内容

来源:人工智能前沿讲习本文约1700字,建议阅读6分钟本文从前言,挑战,方法,以及实验效果四个方面介绍 SpargeAttn。
为了进一步加速 Attention,清华大学陈键飞团队进一步提出了无需训练可直接使用的稀疏 Attention(SpargeAttn)可用来加速任意模型。实现了4-7 倍相比于 FlashAttention 的推理加速,且在语言,视频、图像生成等大模型上均保持了端到端的精度表现。

-
论文标题:SpargeAttn: Accurate Sparse Attention Accelerating Any Model Inference
-
论文链接:https://arxiv.org/abs/2502.18137
-
开源代码:https://github.com/thu-ml/SpargeAttn
下图展示了 SpargeAttn 的速度,可以发现在 RTX4090 上,SpargeAttn 在 60% 稀疏度的情况下可以达到 900TOPS 的速度,甚至是使用 A100 显卡速度的 4.5 倍(A100 上 FlashAttention 只有 200TOPS)。

在 SpargeAttn 的 Github 仓库中可以发现,SpargeAttn 的使用方法比较简洁,只需要进行一次简单的超参数搜索过程,就可以永久地对任意的模型输入进行推理加速。
接下来,将从前言,挑战,方法,以及实验效果四个方面介绍 SpargeAttn。
前言
随着大模型需要处理的序列长度越来越长,Attention 的速度优化变得越来越重要。这是因为相比于网络中其它操作的 O (N) 的时间复杂度,Attention 的时间复杂度是 O (N^2)。尽管 Attention 的计算复杂度为 O (N^2),但幸运的是 Attention 具备很好的稀疏性质,即 P 矩阵的很多值都接近 0。如何利用这种稀疏性来节省计算就成为了 attention 加速的一个重要方向。大多数现有的工作都集中在利用 P 矩阵在语言模型中表现出来的固定的稀疏形状(如滑动窗口)来节省计算,或是需要重新训练模型,比如 DeepSeek 的 NSA 以及 Kimi 的 MoBA。此外,现有稀疏 Attention 通常需要较大的上下文窗口(如 64K~1M)才能有明显加速。SpargeAttn 的目标是开发一个无需训练、对各种模型(语言 / 视频 / 图像)通用、精度无损、对中等长度的上下文(如 4-32K)也有加速效果的注意力机制。
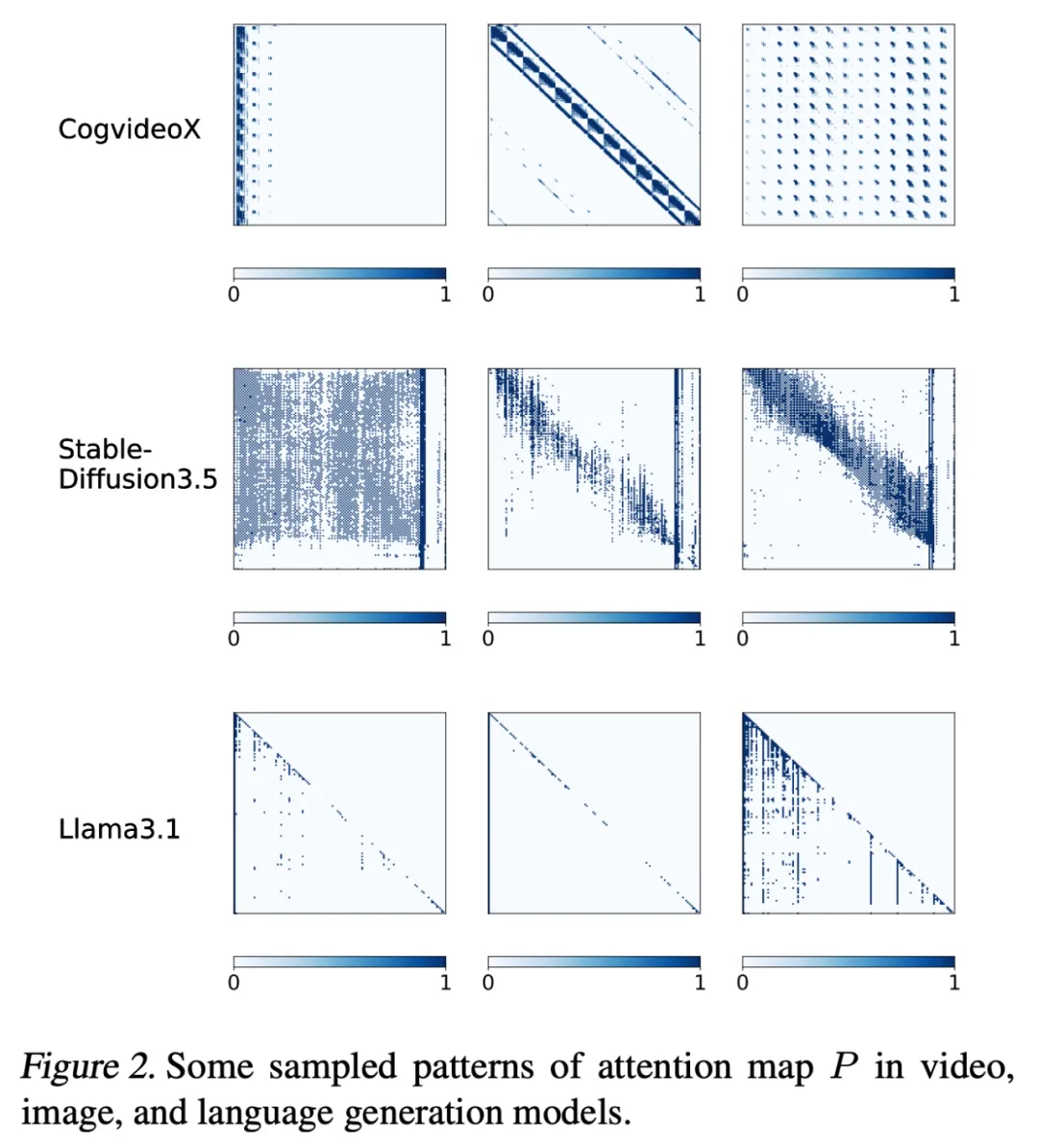
图 1: 不同的模型表现出不同的稀疏形状
实现通用的,无需训练的稀疏 Attenion 有哪些挑战?
挑战 1
通用性:Attention 虽然具备稀疏性质,但是其稀疏形状在不同的模型甚至同一模型的不同层中都是不同的,体现出很强的动态性。
如图 1 所示,前两种模型分别为视频模型和图像生成模型,这两个模型中的 Attention 的稀疏形状相比语言模型更加没有规律。设计一种各种模型通用的稀疏 Attention 是困难的。
挑战 2
可用性:对于各种 Attention 的输入,很难同时实现准确且高效的稀疏 Attention。
这是因为准确性要求了完全精确地预测 P 中的稀疏区域,高效性则要求了此预测的时间开销极短。在一个极短的时间内完全精准地预测 P 的稀疏形状是困难的。
方法
为了解决上述的两个挑战,研究团队提出了对应的解决办法。
-
研究团队提出了一种各模型通用的快速的对 P 矩阵稀疏部分进行预测的算法。该方法选择性地对 Q, K 矩阵进行压缩并预测 P 矩阵,接着使用 TopCdf 操作省略 P 中稀疏部分对应的 QK^T 与 PV 的矩阵乘法。
-
研究团队提出了在 GPU Warp 级别上的稀疏 Online Softmax算法,该算法通过利用 Online Softmax 中全局最大值与局部最大值之间的差异,进一步省略了一些 PV 的矩阵乘法计算。
-
可选的,针对视频和图像模型,研究团队充分利用图像以及视频中的 Token 局部相似性质,使用希尔伯特重排的方法对 Attention 前的 Token 进行重新排列,进一步提高稀疏度。
-
最后,研究团队将这种稀疏方法与基于量化的 SageAttention 融合到一起,进一步加速 Attention。
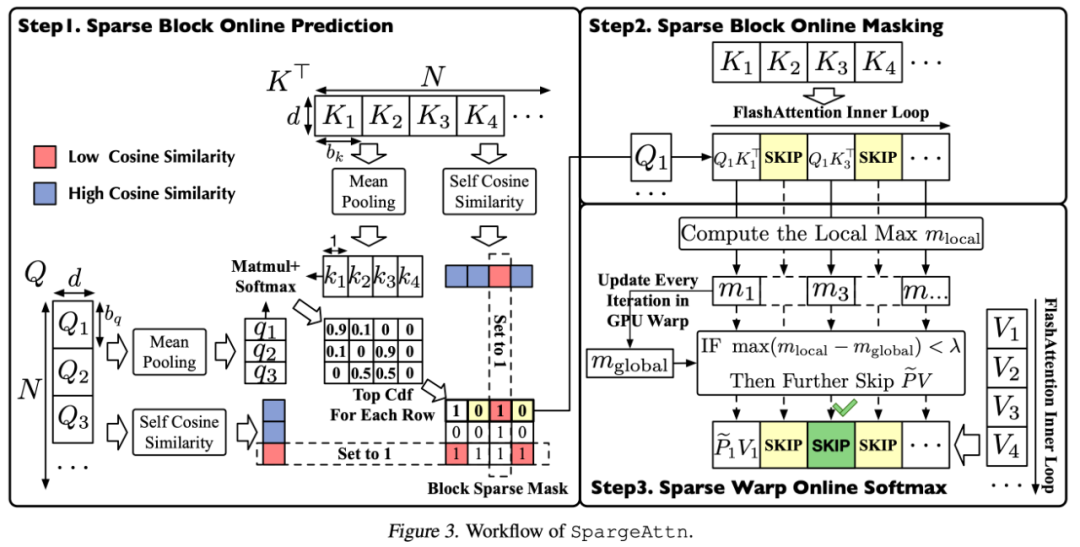
图 2: SpargeAttn 的算法流程图
SpargeAttn 的算法流程如下所示:

实验效果
总的来说,SpargeAttn 在视频、图像、文本生成等大模型均可以实现无需训练的加速效果,同时保证了各任务上的端到端的精度。
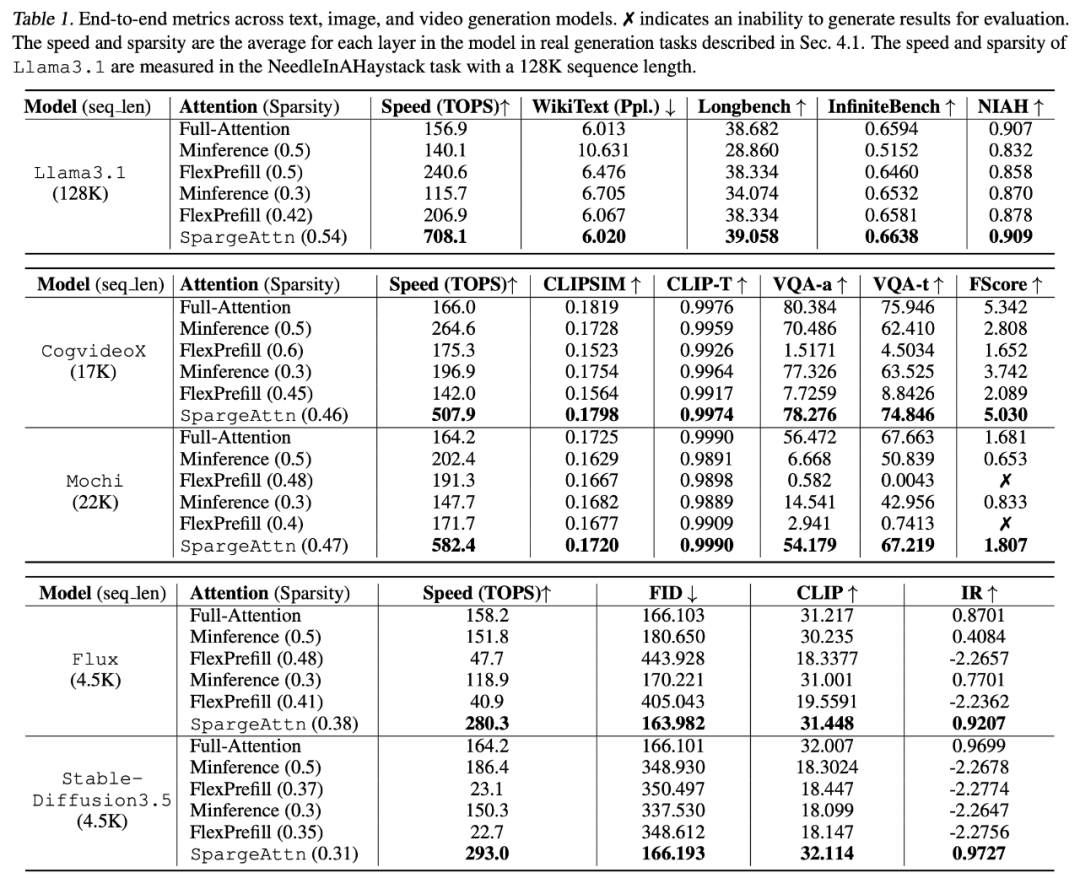
下表展示了 SpargeAttn 在各模型上的稀疏度,Attention 速度,以及各任务上的端到端精度,可以发现 SpargeAttn 在保证了加速的同时没有影响模型精度:(注:此论文中的所有实验都是基于 SageAttention 实现,目前 Github 仓库中已有基于 SageAttention2 的实现,进一步提供了 30% 的加速。
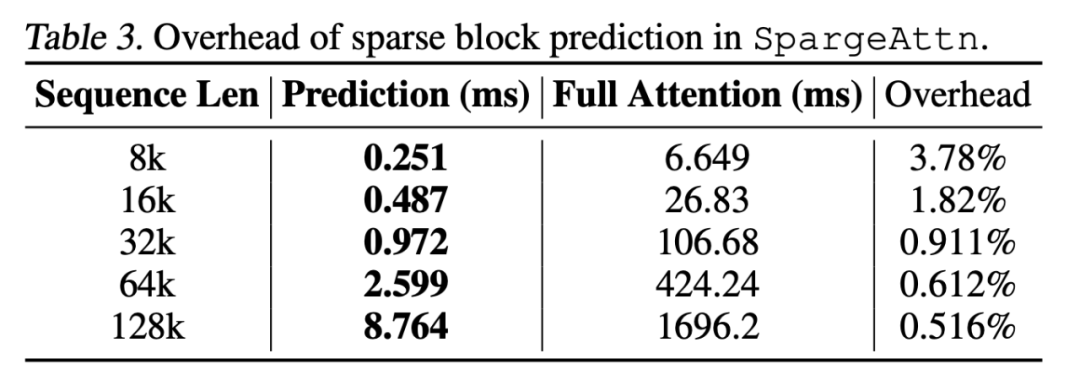
值得一提的是,此前的稀疏 Attention 工作很多无法实际使用的原因之一是稀疏预测部分的 Overhead 较大,而 SpargeAttn 团队还将稀疏预测部分的代码进行了极致优化,将 Overhead 压缩到了几乎在各种长度的序列下都可以忽略的地步:
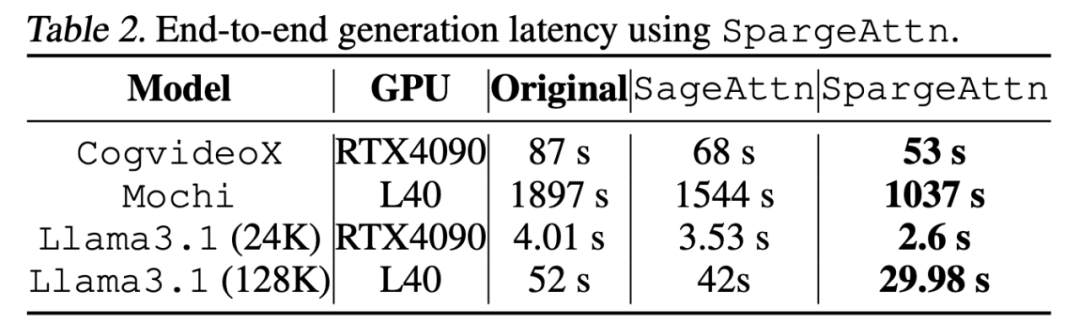
下表展示了对于各模型的端到端的加速效果,以视频生成模型 Mochi 为例,SpargeAttn 提供了近两倍的端到端加速效果:(注:此论文中的所有实验都是基于 SageAttention 实现,目前 Github 仓库中已有基于 SageAttention2 的实现,进一步提供了 30% 的加速)
编辑:黄继彦
