复旦与阶跃星辰联合发布OmniSVG,一个可处理3万Token的SVG矢量图生成模型,支持多模态输入,并开源大规模数据集MMSVG-2M。
原文标题:好玩!复旦与阶跃星辰联合发布SVG矢量图生成大模型OmniSVG!挑战3万Token极限
原文作者:机器之心
冷月清谈:
怜星夜思:
2、OmniSVG目前生成复杂SVG需要较长的生成时间,你认为未来可以通过哪些技术手段来优化生成速度?
3、MMSVG-2M数据集的开源对于SVG生成领域有哪些积极意义?你认为未来还需要构建哪些类型的SVG数据集?
原文内容

在日常生活中,SVG(可缩放矢量图形)被广泛应用于网页设计、图标、徽标等领域。SVG 图形因其可缩放性和清晰度,在以下场景中得到了广泛应用:
-
网页设计:用于制作响应式图标、按钮和装饰元素,确保在不同设备上显示清晰。
-
品牌标识:企业徽标、品牌图形等,保持高质量的视觉效果。
-
用户界面设计:应用程序和网站的界面元素,如导航栏、菜单图标等。
-
教育与培训材料:用于制作插图、流程图和示意图,帮助信息传达。
然而,创建这些图形通常需要专业的设计技能和工具。对非专业人士而言,存在一定的门槛。因此,开发自动化的 SVG 设计与生成工具显得尤为关键。
现有基于优化的方法通过优化可微分的矢量图形光栅化器,迭代地调整 SVG 参数。这些方法在生成 SVG 图标方面有效,但在处理复杂样本时计算开销较大,且生成的输出缺乏结构,存在冗余的锚点。
在现有自回归 SVG 生成方法中,存在两个主要局限性:
-
上下文窗口长度限制:由于模型只能处理有限长度的输入序列,这限制了其生成复杂 SVG 内容的能力,现有自回归方法利用 Transformer 模型或预训练的大型语言模型(LLM),直接生成表示 SVG 的 XML 参数或代码,然而复杂 SVG 需要的上下文长度将超出现有 LLM 上下文窗口长度,从而限制了复杂 SVG 的生成;
-
复杂 SVG 数据匮乏:缺乏包含复杂 SVG 内容的大规模数据集,限制了模型的学习和生成能力。现有数据集通常包括 icon 级别的 SVG 或者较为简单的插画 SVG,目前角色复杂度级别的 SVG 数据集仍然是空缺。
项目中,OmniSVG 引入 SVG 参数化的表达方式,自回归地生成高质量、复杂的 SVG。它通过多种生成模式展示了非凡的多功能性,包括文本到 SVG、图像到 SVG 和角色参考生成 SVG,使其成为适用于各种创意任务的强大而灵活的解决方案。

-
论文标题: OmniSVG: A Unified Scalable Vector Graphics Generation Model
-
论文作者:Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, Yu-Gang Jiang
-
作者单位:复旦大学、阶跃星辰
-
论文地址:https://arxiv.org/pdf/2504.06263
-
项目主页:https://omnisvg.github.io/
-
代码地址:https://github.com/OmniSVG/OmniSVG
-
HuggingFace:https://huggingface.co/OmniSVG
值得一提的是,OmniSVG 在发布的当天就成为 Huggingface daily paper upvoted 的第一名,并成为当周排名第二热门的论文。OmniSVG 在 GitHub 上线 7 天,已经斩获了 1.3k star,在国外媒体获得广泛关注。
Huggingface当周第二热门论文
让我们先来看一些生成效果:



1.统一的多模态复杂 SVG 生成框架
OmniSVG 是首个利用预训练视觉语言模型(VLM)进行端到端多模态复杂 SVG 生成的统一框架。通过将 SVG 的坐标和命令参数化为离散的标记,OmniSVG 将结构逻辑与低级几何信息解耦,缓解了代码生成模型中常见的 「坐标幻觉」问题,生成生动且多彩的 SVG 结果。并且得益于下一标记预测的训练目标,OmniSVG 能够在给定部分观测的情况下,生成多样化的 SVG 内容。与传统的自回归 SVG 生成方法相比,OmniSVG 能够处理长度高达 3 万个token 的 SVG,促进了复杂高质量 SVG 的生成。基于预训练的 VLM,OmniSVG 能够理解视觉和文本指令,合成可编辑的高保真 SVG,适用于从图标到复杂插图和动漫角色等多种领域。
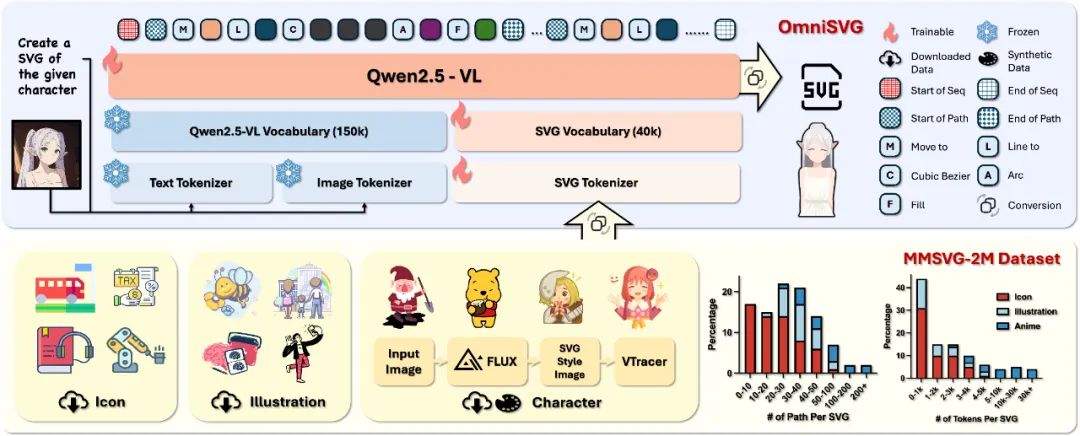
OmniSVG 基于预训练的视觉语言模型 Qwen2.5-VL 构建,并集成了 SVG 分词器。该模型将文本和图像输入分词为前缀分词,而 SVG 分词器则将矢量图形命令编码到统一的表示空间中。

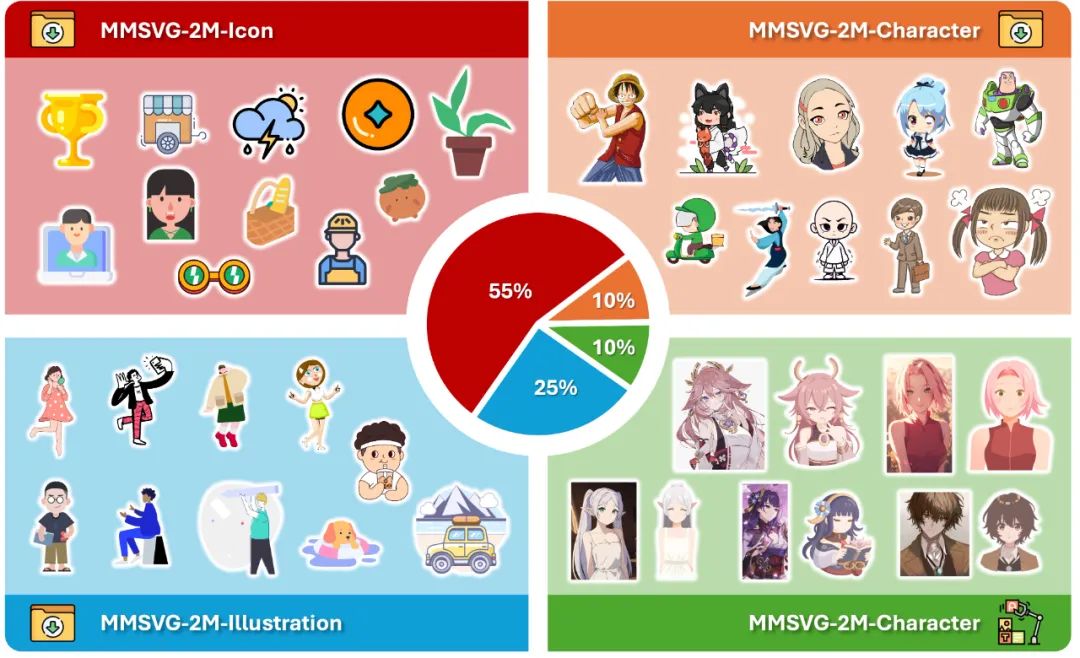
2.MMSVG-2M:包含 200 万个 SVG 样本
项目还开源了 MMSVG-2M 数据集和 MMSVG-Bench 评测平台。MMSVG-2M 是一个大规模的 SVG 数据集,包含了 200 万个 SVG 样本,涵盖了网站图标、插图、平面设计、动漫角色等多种类型。MMSVG-2M 数据集的 SVG 样本,涵盖了网站图标、插图、平面设计、动漫角色等多种 SVG 类型,如下图所示。
3. 实验结果
为了进一步推动 SVG 生成技术的发展,MMSVG-Bench 评测平台专注于以下三个主要任务,分别是文本转 SVG、图像转 SVG 以及角色参考生成 SVG。
论文在 MMSVG-2M 数据集(图标、插图和角色)上将所提出的方法与 SOTA 文本转 SVG 和图像转 SVG 均进行了比较。OmniSVG 在指令遵循性和生成的 SVG 的美观性方面均优于现有的最佳方法。

OmniSVG 和最先进的文本转 SVG 任务的比较结果。

OmniSVG 和最先进的图像转 SVG 任务的比较结果。

通过使用自然角色图像和 SVG 数据对进行训练,OmniSVG 能够通过图像角色参考生成角色 SVG。
结论与局限性
综上所述,OmniSVG 是一种统一的可缩放矢量图形(SVG)生成模型,利用预训练的视觉 - 语言模型(VLM)进行端到端的多模态 SVG 生成。通过将 SVG 命令和坐标参数化为离散标记,OmniSVG 有效地将结构逻辑与低级几何信息解耦,提高了训练效率,同时保持了复杂 SVG 结构的表现力。此外,OmniSVG 在多个条件生成任务中表现出色,显示出其在专业 SVG 设计工作流中应用的巨大潜力。
不过,在推理过程中,OmniSVG 会为复杂样本生成数以万计的标记,这不可避免地会导致相当长的生成时间。同时,在可预见的未来,将 SVG 风格的图像和来源更丰富的自然图像,融入协同训练工作流,有望提升模型对输入图像风格的鲁棒性。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com