通义万相开源首尾帧生视频模型,上传两张图片即可生成高清特效视频,支持运镜控制,快来体验!
原文标题:通义万相新模型开源,首尾帧图一键生成特效视频!
原文作者:阿里云开发者
冷月清谈:
怜星夜思:
2、文章里提到这个模型可以控制运镜,感觉这个功能怎么样?运镜对视频内容生成有什么影响?
3、通义万相这个模型开源了,大家觉得这对AI视频创作领域会带来什么影响?会不会降低视频创作的门槛,让更多人参与进来?
原文内容
昨晚,通义万相首尾帧生视频14B模型正式开源。
作为业界首个百亿级参数规模的开源首尾帧生视频模型,该模型可根据用户指定的开始和结束图片,生成一段能衔接首尾画面的720p高清视频,满足延时摄影、变身等更可控、更定制化的视频生成需求。
基于该模型,用户上传两张图片即可完成更复杂、更个性化的视频生成任务,并实现同一主体的特效变化、不同场景的运镜控制等视频生成。
用户还可输入一段提示词,通过旋转、摇镜、推进等运镜控制衔接画面,在保证视频和预设图片一致性前提下,让视频拥有更丰富的视觉效果。

模型体验
目前,用户可在通义万相官网直接免费体验该模型,或在GitHub、Hugging Face、魔搭社区下载模型本地部署后进行二次开发。
通义万相官网:https://tongyi.aliyun.com/wanxiang/videoCreation
GitHub:https://github.com/Wan-Video/Wan2.1
Hugging Face:https://huggingface.co/Wan-AI/Wan2.1-FLF2V-14B-720P
魔搭社区:https://www.modelscope.cn/models/Wan-AI/Wan2.1-FLF2V-14B-720P
技术解读
首尾帧生视频比文生视频、单图生视频的可控性更高,是最受AI视频创作者欢迎的功能之一,但这类模型的训练难度较大,对模型的指令遵循、视频内容与首尾帧一致性、视频过渡自然流畅性等均有高要求。
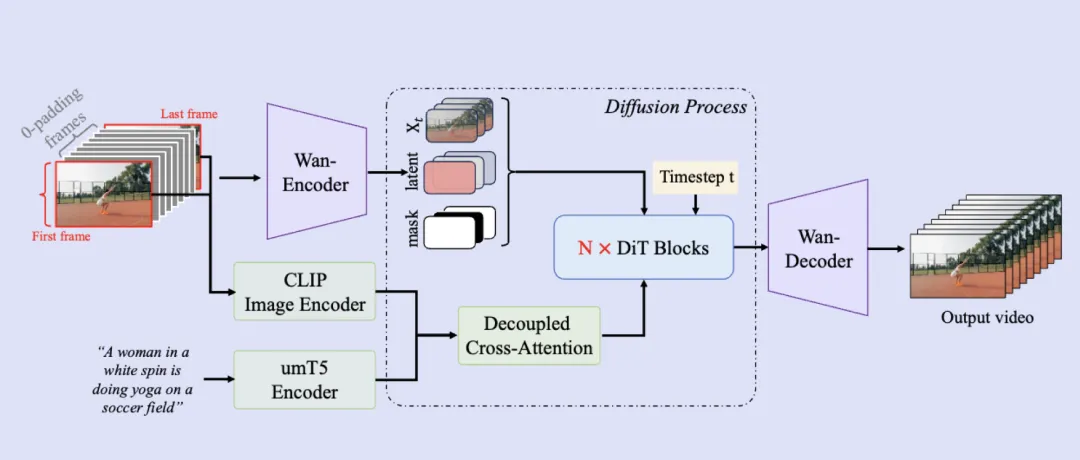
基于现有的Wan2.1文生视频基础模型架构,通义万相首尾帧生视频模型进一步引入了额外的条件控制机制,通过该机制可实现流畅且精准的首尾帧变换。
在训练阶段,团队还构建了专门用于首尾帧模式的训练数据,同时针对文本与视频编码模块、扩散变换模型模块采用了并行策略,这些策略提升了模型训练和生成效率,也保障了模型具备高分辨率视频生成的效果。
今年2月,通义万相Wan2.1文生视频和图生视频模型开源后,迅速登上Hugging Face模型热榜和模型空间榜榜首,其在GitHub已斩获超10k star,模型下载量超过220万,是开源社区热度最高的大模型之一。
效果展示








