提出Scene Splatter,一种基于动量机制视频扩散模型,从单张图像生成三维场景。通过级联动量机制和全局高斯表示微调,实现高保真度和一致性的多视角视频生成,突破视频长度限制。
原文标题:【CVPR2025】场景飞溅:基于视频扩散模型的单图像动势三维场景生成
原文作者:数据派THU
冷月清谈:
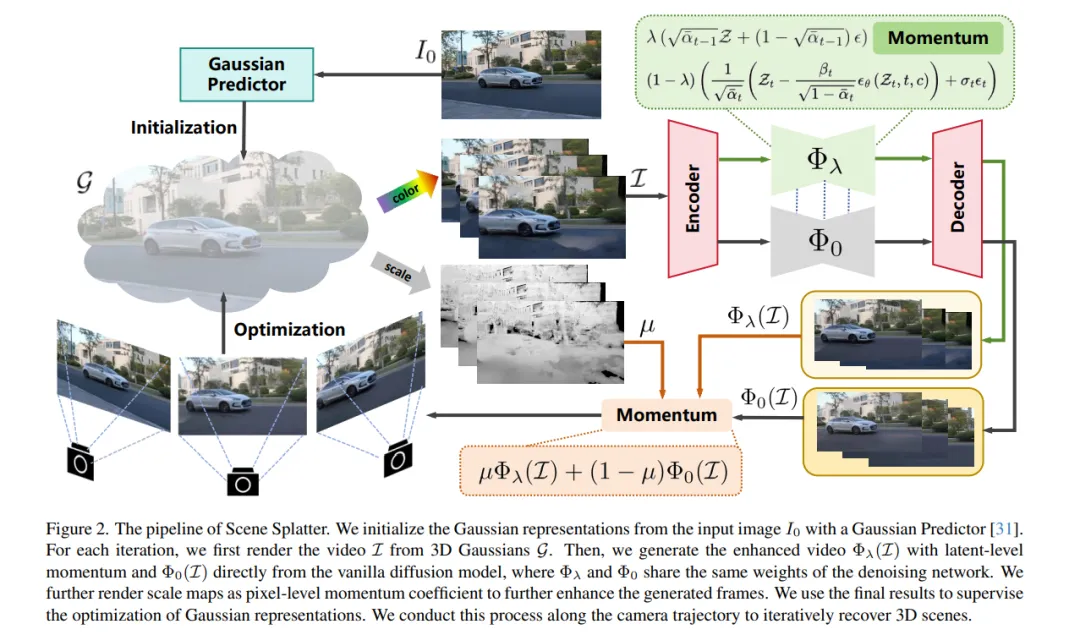
本文提出了一种名为Scene Splatter的新方法,它是一种基于动量机制的视频扩散模型,用于从单张图像生成通用的三维场景。该方法通过构造噪声样本作为“动量”来增强视频细节并保持场景一致性。为了进一步提升未知区域的信息恢复,该方法引入一致性较强的视频作为像素级动量,并与不含动量的视频融合。通过级联式动量机制,引导视频扩散模型生成具有高保真度与一致性的多视角新视频。此外,通过对全局高斯表示进行微调,结合增强后的帧进行新帧渲染和动量更新,突破了传统方法在视频长度上的限制,实现了三维场景的逐步恢复。实验结果表明,该方法在生成高质量且一致的场景方面表现出良好的泛化能力与领先性能。
怜星夜思:
1、Scene Splatter方法中提到的“动量”具体指的是什么?它在增强视频细节和保持场景一致性方面是如何发挥作用的?
2、文中提到的“全局高斯表示”微调在新帧渲染和动量更新中起到了什么作用?为什么这种方式能够突破传统方法在视频长度上的限制?
3、Scene Splatter方法在哪些场景下具有应用潜力?你认为它在未来的发展方向会是什么?
2、文中提到的“全局高斯表示”微调在新帧渲染和动量更新中起到了什么作用?为什么这种方式能够突破传统方法在视频长度上的限制?
3、Scene Splatter方法在哪些场景下具有应用潜力?你认为它在未来的发展方向会是什么?
原文内容

来源:专知本文约1000字,建议阅读5分钟
我们进一步引入上述一致性较强的视频作为像素级动量,将其与不含动量直接生成的视频融合,以更好地恢复未知区域的信息。

在本文中,我们提出了一种名为 Scene Splatter 的新范式,该方法基于动量机制的视频扩散模型,旨在从单张图像生成通用三维场景。现有方法通常利用视频生成模型合成新视角,但普遍存在视频长度受限与场景一致性差的问题,进而在后续重建过程中容易出现伪影与失真。
为了解决这一问题,我们从原始特征中构造噪声样本,作为“动量”以增强视频细节并保持场景一致性。然而,在感知范围覆盖已知与未知区域的潜在特征(latent features)中,这种基于潜在层的动量会限制扩散模型在未知区域的生成能力。
因此,我们进一步引入上述一致性较强的视频作为像素级动量,将其与不含动量直接生成的视频融合,以更好地恢复未知区域的信息。通过这种级联式动量机制,我们的方法能够引导视频扩散模型生成具有高保真度与一致性的多视角新视频。
此外,我们对全局高斯表示进行微调,结合增强后的帧进行新帧渲染,并用于下一步的动量更新。借助这种方式,我们可实现对三维场景的逐步恢复,突破传统方法在视频长度上的限制。
大量实验结果表明,我们的方法在生成高质量且一致的场景方面表现出良好的泛化能力与领先性能。