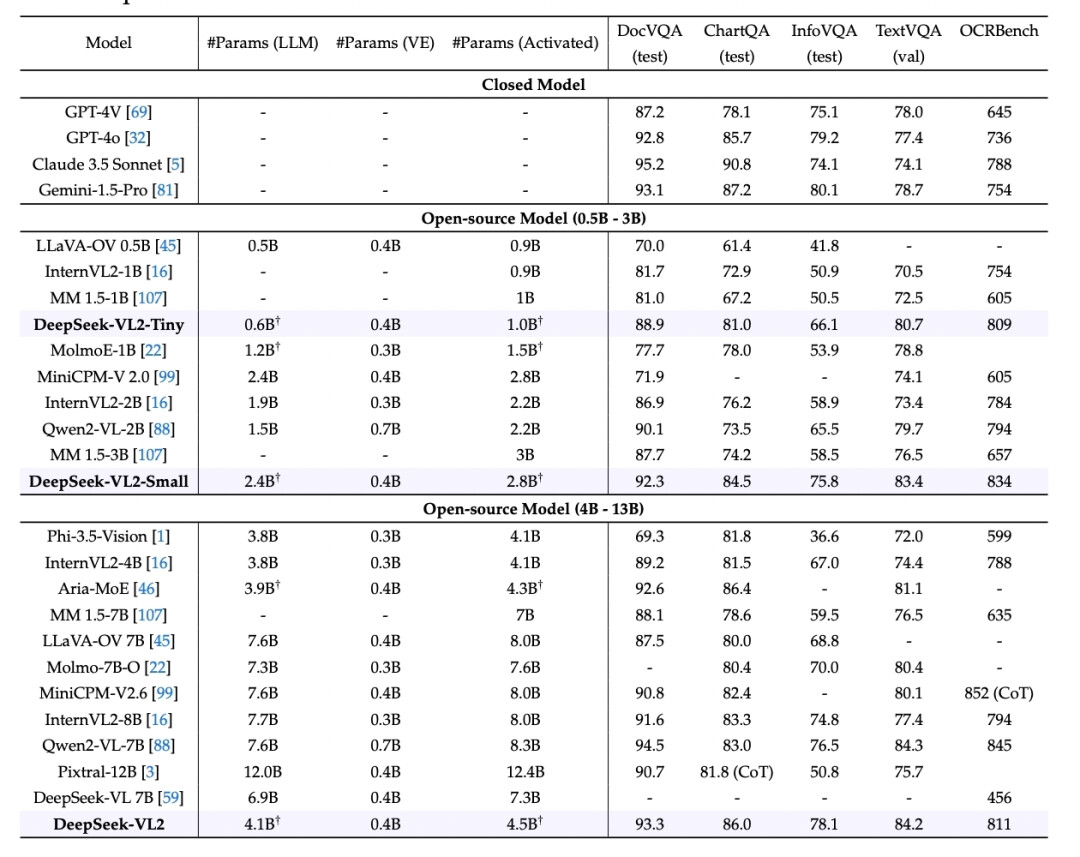
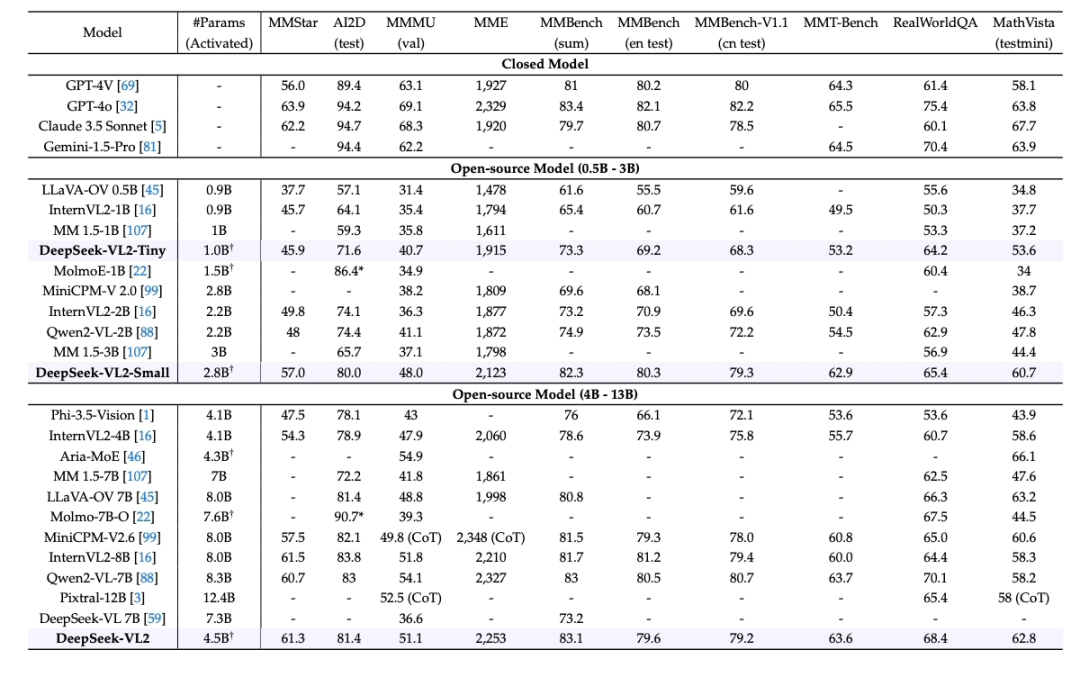
DeepSeek-VL2是基于MoE架构的多模态大模型,通过动态切片和MLA机制提升效率,PaddleMIX已支持其推理训练。
原文标题:前沿多模态模型开发与应用实战3:DeepSeek-VL2多模态理解大模型算法解析与功能抢先体验
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、DeepSeek-VL2 的动态图像切片编码策略是如何提升模型性能的?在处理不同长宽比和分辨率的图像时,这种策略有哪些局限性?
3、DeepSeek-VL2 的训练过程分为三个阶段:视觉-语言对齐、视觉-语言预训练和监督微调。这三个阶段分别侧重于哪些能力的训练?为什么需要这样分阶段训练?
原文内容


-
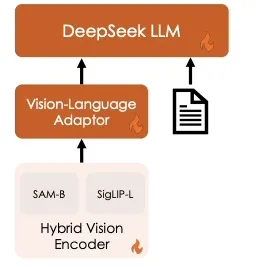
Hybrid Vision Encoder:混合视觉编码器,采用 SigLIP-L 作为视觉编码器,结合 SAM-B 和 SigLIP-L 编码器,能够高效处理高分辨率图像(1024×1024),同时保留语义和细节信息。高分辨率特征图经过插值和卷积处理后,与低分辨率特征图连接,生成具有2048个维度的视觉 token。
-
VL Adaptor:视觉语言适配器,使用两层混合 MLP 桥接视觉编码器和语言模型。高分辨率和低分辨率特征分别经过单层 MLP 处理后沿维度连接,再通过另一层 MLP 转换到语言模型的输入空间。
-
DeepSeek LLM:语言模型是 DeepSeek-LLM,其设计遵循 LLaMA,采用 Pre-Norm 结构和 SwiGLU 激活函数,使用旋转嵌入进行位置编码。

-
Vision Encoder:DeepSeek-VL2采用的也是 SigLIP,同时引入了动态切片策略(Dynamic Tiling Strategy),能够处理不同分辨率和长宽比的高分辨率图像。传统的图像编码方法往往固定分辨率,导致在处理较大或不规则图像时性能下降。动态切片策略通过将高分辨率图像分割成多个小块进行处理,减少了计算成本,同时保留了详细的视觉特征。该方法避免了传统视觉编码器的固定分辨率限制,使得模型在处理复杂图像任务(如视觉引导、文档分析等)时具有更好的性能。
-
VL Adaptor:DeepSeek-VL2采用两层多层感知器(MLP),然后再使用2×2 pixel shuffle 操作压缩每个图像块的 token 数目,用于视觉特征映射到文本空间。
-
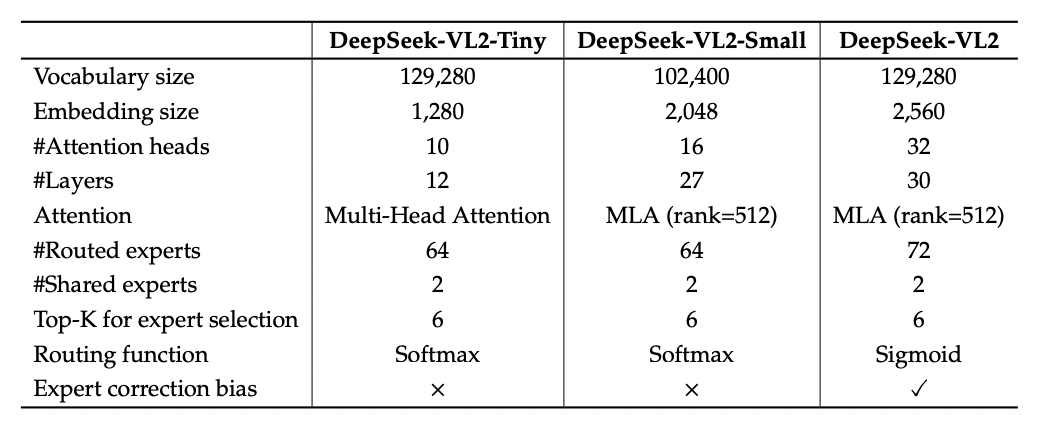
DeepSeek-MoE LLM:语言模型采用了 DeepSeek-MoE(Mixture of Experts)架构,并结合了多头潜在注意力机制(Multi-head Latent Attention,MLA)。MLA 机制能够有效压缩键值缓存(KV Cache),提升推理效率。MoE 架构则通过稀疏计算进一步提升了效率,使得模型在处理大规模数据时能够实现更高的吞吐量。

-
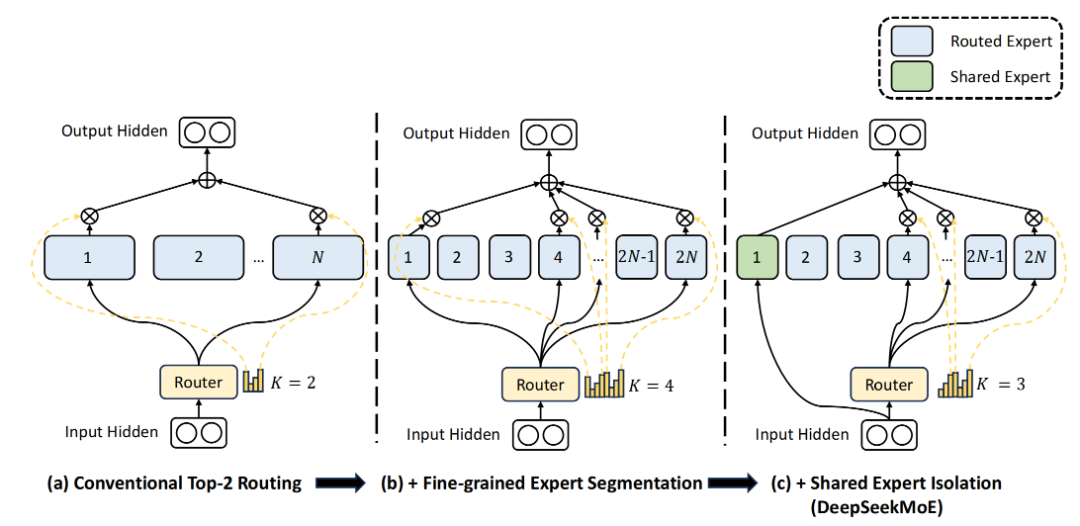
Fine-Grained Expert Segmentation-细粒度的专家分割,通过细化 FFN 中间隐藏维度,维持参数数量不变的同时激活更多细粒度的专家,使得激活的专家更加灵活和适应性更强;
-
Shared Expert Isolation-共享专家隔离,将某些专家隔离为共享专家,始终激活,旨在捕捉和巩固不同上下文中的共同知识。
-
DeepSeek-VL 通用的 VQA 数据。
-
表格、图表和文档理解数据。PubTabNet、FinTabNet 和 Docmatix。
-
Web-to-code 和 plot-to-Python 生成。Websight,并遵循 DeepSeek-VL 的方法,使用公开的 Jupyter 笔记本中的 Python 图表。通过使用 DeepSeek V2.5对 Websight 部分数据增强。作者还利用 DeepSeek V2.5生成的 Python 图表代码来减少 plot-to-code 中的噪声。
-
包括视觉提示的 QA 数据:参考 Vip-llava 构建具有不同视觉提示(箭头、方框、圆圈和涂鸦)的数据。
-
Prompt: \texttt{Locate <|ref|><|/ref|> in the given image.}
-
Response: \texttt{<|ref|><|/ref|><|det|>[[x1, y1, x2, y2],\ldots]<|/det|>}
-
Prompt: \texttt{<|grounding|>Can you describe the content of the image?}
-
Response: $\texttt{Two <|ref|>dogs<|/ref|><|det|>[[x1, y1, x2, y2],\ldots]<|/det|> are running on the grass.}
-
初始阶段:使用3.1.1节中详细描述的图文配对数据,训练视觉编码器和视觉-语言适配器 MLP,同时保持语言模型固定。
-
预训练阶段:使用3.1.2节描述的数据进行视觉-语言预训练。在此阶段,所有模型参数,包括视觉编码器、视觉-语言适配器和语言模型,都会解锁并同时训练。
-
微调阶段:使用第3.1.3节概述的数据进行有监督的微调,进一步优化模型性能。

-
计算缩放比例:对于每个候选分辨率,计算其相对于原始图像尺寸的缩放比例(取宽度和高度缩放比例中的最小值)。
-
计算缩放后的尺寸:使用上述缩放比例计算缩放后的图像宽度和高度。
-
计算有效分辨率:有效分辨率是缩放后的图像分辨率与原始图像分辨率中较小的一个。这是为了确保缩放后的图像不会比原始图像具有更高的分辨率。
-
计算浪费的分辨率:浪费的分辨率是候选分辨率的面积减去有效分辨率的面积。
-
选择最佳匹配:遍历所有候选分辨率,找到有效分辨率最大且浪费分辨率最小的那个作为最佳匹配。如果两个候选分辨率的有效分辨率相同,则选择浪费分辨率较小的那个。
def select_best_resolution(image_size, candidate_resolutions): original_width, original_height = image_size best_fit = None max_effective_resolution = 0 min_wasted_resolution = float("inf")for width, height in candidate_resolutions:
scale = min(width / original_width, height / original_height)
downscaled_width, downscaled_height = int(original_width * scale), int(original_height * scale)
effective_resolution = min(downscaled_width * downscaled_height, original_width * original_height)
wasted_resolution = width * height - effective_resolutionif (
effective_resolution > max_effective_resolution
or effective_resolution == max_effective_resolution
and wasted_resolution < min_wasted_resolution
):
max_effective_resolution = effective_resolution
min_wasted_resolution = wasted_resolution
best_fit = width, height
return best_fit
VL Adapter
-
conversation:包含 $\texttt{}$ 标签的原始文本对话。
-
images:与文本对话中的 $\texttt{}$ 标签相对应的图像列表。
-
bos:布尔值,指定是否在分词结果的开头添加开始序列(Begin Of Sequence, BOS) token。默认为 True。
-
eos:布尔值,指定是否在分词结果的末尾添加结束序列(End Of Sequence, EOS)token。默认为 True。
-
cropping:布尔值,指定是否对图像进行裁剪以适应特定的分辨率。默认为 True。
-
断言检查:确保文本对话中的 $\texttt{}$ 标签数量与提供的图像数量相匹配。
-
文本分割:使用 $\texttt{}$ 标签将文本对话分割成多个部分。
-
初始化列表:用于存储处理后的图像、图像序列掩码、图像空间裁剪信息、图像 token 数量以及分词后的字符串。
-
遍历文本和图像:对于每个文本部分和对应的图像,执行以下操作:
-
文本分词:将文本部分分词,但不添加 BOS 和 EOS token。
-
图像分辨率选择:根据裁剪标志选择最佳图像分辨率。
-
全局视图处理:将图像调整为固定大小(self.image_size),并填充背景色。
-
局部视图处理:根据最佳分辨率将图像裁剪成多个小块,并对每个小块进行处理。
-
记录裁剪信息:记录每个图像在宽度和高度上被裁剪成的小块数量。
-
添加图像 token:为每个图像(全局和局部视图)生成一系列图像 token,并添加到分词后的字符串中。
-
更新掩码和 token 数量:更新图像序列掩码和图像 token 数量列表。
-
处理最后一个文本部分:对最后一个文本部分进行分词处理(但不添加 BOS 和 EOS token),并更新分词后的字符串和图像序列掩码。
-
添加 BOS 和 EOS token:根据参数设置,在分词结果的开头和末尾添加 BOS 和 EOS token。
-
断言检查:确保分词后的字符串长度与图像序列掩码的长度相匹配。
-
tokenized_str:分词后的字符串,包含文本和图像 token。
-
images_list:处理后的图像列表,包括全局视图和局部视图。
-
images_seq_mask:图像序列掩码,用于指示哪些 token 是图像 token。
-
images_spatial_crop:图像空间裁剪信息,记录每个图像在宽度和高度上的裁剪小块数量。
-
num_image_tokens:每个图像对应的 token 数量列表。
def tokenize_with_images( self, conversation: str, images: List[Image.Image], bos: bool = True, eos: bool = True, cropping: bool = True ): """Tokenize text with <image> tags.""" assert conversation.count(self.image_token) == len(images) text_splits = conversation.split(self.image_token) images_list, images_seq_mask, images_spatial_crop = [], [], [] num_image_tokens = [] tokenized_str = [] for text_sep, image in zip(text_splits, images): """encode text_sep""" tokenized_sep = self.encode(text_sep, bos=False, eos=False) tokenized_str += tokenized_sep images_seq_mask += [False] * len(tokenized_sep) """select best resolution for anyres""" if cropping: best_width, best_height = select_best_resolution(image.size, self.candidate_resolutions) else: best_width, best_height = self.image_size, self.image_size“”“process the global view”“”
global_view = ImageOps.pad(
image, (self.image_size, self.image_size), color=tuple(int(x * 255) for x in self.image_transform.mean)
)
images_list.append(self.image_transform(global_view))“”“process the local views”“”
local_view = ImageOps.pad(
image, (best_width, best_height), color=tuple(int(x * 255) for x in self.image_transform.mean)
)for i in range(0, best_height, self.image_size):
for j in range(0, best_width, self.image_size):
images_list.append(
self.image_transform(local_view.crop((j, i, j + self.image_size, i + self.image_size)))
)“”“record height / width crop num”“”
num_width_tiles, num_height_tiles = (best_width // self.image_size, best_height // self.image_size)
images_spatial_crop.append([num_width_tiles, num_height_tiles])“”“add image tokens”“”
h = w = math.ceil(self.image_size // self.patch_size / self.downsample_ratio)
tokenized_image = [self.image_token_id] * h * (w + 1)
tokenized_image += [self.image_token_id]
tokenized_image += [self.image_token_id] * (num_height_tiles * h) * (num_width_tiles * w + 1)
tokenized_str += tokenized_image
images_seq_mask += [True] * len(tokenized_image)
num_image_tokens.append(len(tokenized_image))“”“process the last text split”“”
tokenized_sep = self.encode(text_splits[-1], bos=False, eos=False)
tokenized_str += tokenized_sep
images_seq_mask += [False] * len(tokenized_sep)
“”“add the bos and eos tokens”“”
if bos:
tokenized_str = [self.bos_id] + tokenized_str
images_seq_mask = [False] + images_seq_mask
if eos:
tokenized_str = tokenized_str + [self.eos_id]
images_seq_mask = images_seq_mask + [False]
assert len(tokenized_str) == len(
images_seq_mask
), f"tokenize_with_images func: tokenized_str’s length {len(tokenized_str)} is not equal to imags_seq_mask’s length {len(images_seq_mask)}"
return (tokenized_str, images_list, images_seq_mask, images_spatial_crop, num_image_tokens)
MLA(Multi-head Latent Attention)
-
config:DeepseekV2Config 类型的配置对象,包含模型的各种配置参数。
-
layer_idx:可选参数,表示当前层的索引,用于缓存机制。
-
hidden_states:paddle.Tensor 类型的输入张量,表示隐藏状态。
-
attention_mask:可选参数,paddle.Tensor 类型的注意力掩码,用于屏蔽不需要关注的位置。
-
position_ids:可选参数,paddle.Tensor 类型的位置编码,用于 RoPE。
-
past_key_value:可选参数,Tuple[paddle.Tensor] 类型的缓存键值对,用于加速推理。
-
output_attentions:布尔类型,表示是否输出注意力权重。
-
use_cache:布尔类型,表示是否使用缓存机制。
-
**kwargs:其他可选参数。
-
如果 q_lora_rank 为 None,则使用 q_proj 对查询进行投影。
-
否则,使用基于 LoRA 的投影(q_a_proj、q_a_layernorm 和 q_b_proj)。
-
使用 kv_a_proj_with_mqa 对键和值进行投影。
-
将结果拆分为 LoRA 和 RoPE 组件。
-
RoPE 应用(RoPE Application)。
-
计算 RoPE 的余弦和正弦值。
-
将 RoPE 应用于查询和键。
-
如果 use_cache 为 True,则更新缓存的键和值。
-
使用缩放点积注意力计算注意力分数。
-
应用注意力掩码和 softmax。
-
输出投影(Output Projection)。
-
使用注意力权重和投影后的值计算注意力输出。
-
应用输出投影(o_proj)。
class DeepseekV2Attention(paddle.nn.Layer): """Multi-headed attention from 'Attention Is All You Need' paper"""def init(self, config: DeepseekV2Config, layer_idx: Optional[int] = None):
super().init()
self.config = config
“”"
…
“”"
if self.q_lora_rank is None:
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.q_head_dim, bias_attr=False)
else:
self.q_a_proj = nn.Linear(self.hidden_size, config.q_lora_rank, bias_attr=config.attention_bias)
self.q_a_layernorm = DeepseekV2RMSNorm(config=config, hidden_size=config.q_lora_rank)
self.q_b_proj = nn.Linear(config.q_lora_rank, self.num_heads * self.q_head_dim, bias_attr=False)self.kv_a_proj_with_mqa = nn.Linear(self.hidden_size, config.kv_lora_rank + config.qk_rope_head_dim, bias_attr=config.attention_bias)
self.kv_a_layernorm = DeepseekV2RMSNorm(config=config, hidden_size=config.kv_lora_rank)
self.kv_b_proj = nn.Linear(config.kv_lora_rank, self.num_heads * (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim), bias_attr=False)self.o_proj = nn.Linear(self.num_heads * self.v_head_dim, self.hidden_size, bias_attr=config.attention_bias)
self._init_rope()
self.softmax_scale = self.q_head_dim**-0.5
if self.config.rope_scaling is not None:
mscale_all_dim = self.config.rope_scaling.get(“mscale_all_dim”, 0)
scaling_factor = self.config.rope_scaling[“factor”]
if mscale_all_dim:
mscale = yarn_get_mscale(scaling_factor, mscale_all_dim)
self.softmax_scale = self.softmax_scale * mscale * mscaledef forward(
self,
hidden_states: paddle.Tensor,
attention_mask: Optional[paddle.Tensor] = None,
position_ids: Optional[paddle.Tensor] = None,
past_key_value: Optional[Tuple[paddle.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
**kwargs,
) -> Tuple[paddle.Tensor, Optional[paddle.Tensor], Optional[Tuple[paddle.Tensor]]]:bsz, q_len, _ = tuple(hidden_states.shape)
if self.q_lora_rank is None:
q = self.q_proj(hidden_states)
else:
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))q = q.reshape([bsz, q_len, self.num_heads, self.q_head_dim]).transpose(perm=[0, 2, 1, 3])
q_nope, q_pe = paddle.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], axis=-1)compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = paddle.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], axis=-1)
compressed_kv = self.kv_a_layernorm(compressed_kv)
k_pe = k_pe.reshape([bsz, q_len, 1, self.qk_rope_head_dim]).transpose(perm=[0, 2, 1, 3])kv_seq_len = tuple(k_pe.shape)[-2]
if past_key_value is not None:
kv_seq_len += past_key_value[0].shape[1]
cos, sin = self.rotary_emb(q_pe, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)if use_cache and past_key_value is not None:
compressed_kv = compressed_kv.unsqueeze(axis=2)
k_pe = k_pe.transpose(perm=[0, 2, 1, 3]) # (b h l d) to (b l h d)
k_pe = paddle.concat([past_key_value[0], k_pe], axis=1)
compressed_kv = paddle.concat([past_key_value[1], compressed_kv], axis=1)past_key_value = (k_pe, compressed_kv)
k_pe = k_pe.transpose(perm=[0, 2, 1, 3]) # go back to (b l h d)
compressed_kv = compressed_kv.squeeze(2)
elif use_cache:
past_key_value = (k_pe.transpose([0, 2, 1, 3]), compressed_kv.unsqueeze(axis=2))
else:
past_key_value = Noneshit tranpose liner weight
kv_b_proj = self.kv_b_proj.weight.T.reshape([self.num_heads, -1, self.kv_lora_rank])
q_absorb = kv_b_proj[:, :self.qk_nope_head_dim, :]
out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]q_nope = paddle.matmul(q_nope, q_absorb)
attn_weights = (
paddle.matmul(q_pe, k_pe.transpose([0, 1, 3, 2])) # [1, 16, 1304, 64] * [1, 1, 1304, 64]
- paddle.matmul(q_nope, compressed_kv.unsqueeze(axis=-3).transpose([0, 1, 3, 2])) # [1, 16, 1304, 512] * [1, 1, 1304, 512]
) * self.softmax_scaleif tuple(attn_weights.shape) != (bsz, self.num_heads, q_len, kv_seq_len):
raise ValueError(
f"Attention weights should be of size {bsz, self.num_heads, q_len, kv_seq_len}, but is {tuple(attn_weights.shape)}"
)
assert attention_mask is not None
if attention_mask is not None:
if tuple(attention_mask.shape) != (bsz, 1, q_len, kv_seq_len):
raise ValueError(
f"Attention mask should be of size {bsz, 1, q_len, kv_seq_len}, but is {tuple(attention_mask.shape)}"
)
attn_weights = attn_weights + attention_maskupcast attention to fp32
attn_weights = F.softmax(attn_weights, axis=-1, dtype=“float32”).to(q_pe.dtype)
attn_weights = F.dropout(attn_weights, self.attention_dropout, training=self.training)
attn_output = paddle.einsum(“bhql,blc->bhqc”, attn_weights, compressed_kv)
attn_output = paddle.matmul(attn_output, out_absorb.transpose([0, 2, 1]))
if tuple(attn_output.shape) != (bsz, self.num_heads, q_len, self.v_head_dim):
raise ValueError(
f"attn_outputshould be of size {bsz, self.num_heads, q_len, self.v_head_dim}, but is {tuple(attn_output.shape)}"
)
attn_output = attn_output.transpose([0, 2, 1, 3])
attn_output = attn_output.reshape([bsz, q_len, self.num_heads * self.v_head_dim])
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
DeepSeekV2-MoE
-
从配置对象中读取参数,如专家数量、共享专家数量、中间层大小等。
-
根据分布式环境(ep_size)分配专家网络到不同的设备上。
-
初始化专家网络列表(self.experts)和共享专家网络(self.shared_experts)。
-
初始化门控机制(self.gate)。
-
保存输入张量的原始形状和值(identity 和 orig_shape)。
-
使用门控机制(self.gate)计算路由索引(topk_idx)、路由权重(topk_weight)和辅助损失(aux_loss)。
-
将输入张量展平以便处理。
-
训练模式:·将输入张量复制多次以匹配每个专家的输入。·根据路由索引将输入分配给对应的专家网络,并计算输出。·对专家输出进行加权求和,并恢复原始形状。·添加辅助损失(AddAuxiliaryLoss.apply)。
-
推理模式:·调用 moe_infer 方法处理输入,并恢复原始形状。·如果存在共享专家网络,将其输出与专家网络的输出相加。·返回最终的输出张量。
class DeepseekV2MoE(paddle.nn.Layer): """ A mixed expert module containing shared experts. """ def __init__(self, config): super().__init__() self.config = config self.num_experts_per_tok = config.num_experts_per_tok if hasattr(config, "ep_size") and config.ep_size > 1: assert config.ep_size == dist.get_world_size() self.ep_size = config.ep_size self.experts_per_rank = config.n_routed_experts // config.ep_size self.ep_rank = dist.get_rank() self.experts = nn.ModuleList( [ ( DeepseekV2MLP( config, intermediate_size=config.moe_intermediate_size ) if i >= self.ep_rank * self.experts_per_rank and i < (self.ep_rank + 1) * self.experts_per_rank else None ) for i in range(config.n_routed_experts) ] ) else: self.ep_size = 1 self.experts_per_rank = config.n_routed_experts self.ep_rank = 0 self.experts = nn.LayerList( [ DeepseekV2MLP(config, intermediate_size=config.moe_intermediate_size) for i in range(config.n_routed_experts) ] ) self.gate = MoEGate(config) if config.n_shared_experts is not None: intermediate_size = config.moe_intermediate_size * config.n_shared_experts self.shared_experts = DeepseekV2MLP(config=config, intermediate_size=intermediate_size)def forward(self, hidden_states):
identity = hidden_states
orig_shape = hidden_states.shape
topk_idx, topk_weight, aux_loss = self.gate(hidden_states)
hidden_states = hidden_states.reshape([-1, hidden_states.shape[-1]])
flat_topk_idx = topk_idx.reshape([-1])remove the infer method
if self.training:
hidden_states = hidden_states.repeat_interleave(self.num_experts_per_tok, axis=0)
y = paddle.empty_like(hidden_states)
for i, expert in enumerate(self.experts):y[flat_topk_idx == i] = expert(hidden_states[flat_topk_idx == i])
if paddle.any(flat_topk_idx == i):
y[flat_topk_idx == i] = expert(hidden_states[flat_topk_idx == i])
y = (y.reshape([*topk_weight.shape, -1]) * topk_weight.unsqueeze(-1)).sum(axis=1)
y = paddle.cast(y, hidden_states.dtype).reshape([*orig_shape])
if self.gate.alpha > 0.0:
y = AddAuxiliaryLoss.apply(y, aux_loss)
else:
y = self.moe_infer(hidden_states, topk_idx, topk_weight).reshape([*orig_shape])
if self.config.n_shared_experts is not None:
y = y + self.shared_experts(identity)
return y
MoEGate
-
从配置对象中读取参数,如专家数量、路由缩放因子、评分函数等。
-
初始化门控权重(self.weight)和路由策略相关参数。
-
如果使用 noaux_tc 路由策略,初始化专家评分校正偏置(self.e_score_correction_bias)。
-
调用 reset_parameters 方法初始化权重。
-
使用 Kaiming 均匀分布初始化门控权重。
-
将输入张量展平以便处理。
-
使用线性变换计算路由得分(logits)。
-
根据评分函数(如 softmax 或 sigmoid)计算路由权重(scores)。
-
如果 top_k > 1 且 norm_topk_prob 为 True,对路由权重进行归一化。
-
在训练模式下,计算辅助损失(aux_loss)以优化路由机制。
-
返回路由索引(topk_idx)、路由权重(topk_weight)和辅助损失(aux_loss)。
class MoEGate(paddle.nn.Layer): def __init__(self, config): super().__init__() self.config = config self.top_k = config.num_experts_per_tok self.n_routed_experts = config.n_routed_experts self.routed_scaling_factor = config.routed_scaling_factor self.scoring_func = config.scoring_func self.alpha = config.aux_loss_alpha self.seq_aux = config.seq_aux self.topk_method = config.topk_method self.n_group = config.n_group self.topk_group = config.topk_group # topk selection algorithm self.norm_topk_prob = config.norm_topk_prob self.gating_dim = config.hidden_size self.weight = paddle.base.framework.EagerParamBase.from_tensor( tensor=paddle.empty(shape=(self.gating_dim, self.n_routed_experts)) ) if self.topk_method == "noaux_tc": self.e_score_correction_bias = paddle.base.framework.EagerParamBase.from_tensor( tensor=paddle.empty(shape=[self.n_routed_experts]) )def forward(self, hidden_states):
bsz, seq_len, h = tuple(hidden_states.shape)
hidden_states = hidden_states.reshape([-1, h])
logits = paddle.nn.functional.linear(
x=hidden_states.astype(“float32”), weight=self.weight.astype(“float32”), bias=None
)
if self.scoring_func == “softmax”:
scores = paddle.nn.functional.softmax(logits, axis=-1, dtype=“float32”)
elif self.scoring_func == “sigmoid”:
scores = logits.sigmoid()
else:
raise NotImplementedError(f"insupportable scoring function for MoE gating: {self.scoring_func}")
if self.topk_method == “greedy”:
topk_weight, topk_idx = paddle.topk(k=self.top_k, sorted=False, x=scores, axis=-1)
elif self.topk_method == “group_limited_greedy”:
group_scores = scores.reshape(bsz * seq_len, self.n_group, -1).max(dim=-1).valuesgroup_idx = paddle.topk(k=self.topk_group, sorted=False, x=group_scores, axis=-1)[1]
group_mask = paddle.zeros_like(x=group_scores)
group_mask.put_along_axis_(axis=1, indices=group_idx, values=1, broadcast=False)
score_mask = (
group_mask.unsqueeze(axis=-1)
.expand(shape=[bsz * seq_len, self.n_group, self.n_routed_experts // self.n_group])
.reshape([bsz * seq_len, -1])
)
tmp_scores = scores.masked_fill(mask=~score_mask.astype(dtype=“bool”), value=0.0)
topk_weight, topk_idx = paddle.topk(k=self.top_k, sorted=False, x=tmp_scores, axis=-1)
elif self.topk_method == “noaux_tc”:
assert not self.training
scores_for_choice = scores.reshape([bsz * seq_len, -1]) + self.e_score_correction_bias.unsqueeze(axis=0)
group_scores = scores_for_choice.reshape([bsz * seq_len, self.n_group, -1]).topk(k=2, axis=-1)[0].sum(axis=-1)group_idx = paddle.topk(k=self.topk_group, sorted=False, x=group_scores, axis=-1)[1]
group_mask = paddle.zeros_like(x=group_scores)
group_mask.put_along_axis_(axis=1, indices=group_idx, values=1, broadcast=False)todo
score_mask = (
group_mask.unsqueeze(axis=-1)
.expand(shape=[bsz * seq_len, self.n_group, self.n_routed_experts // self.n_group])
.reshape([bsz * seq_len, -1])
)
tmp_scores = scores_for_choice.masked_fill(mask=~score_mask.astype(dtype=“bool”), value=0.0)
_, topk_idx = paddle.topk(k=self.top_k, sorted=False, x=tmp_scores, axis=-1)
topk_weight = scores.take_along_axis(axis=1, indices=topk_idx, broadcast=False)
if self.top_k > 1 and self.norm_topk_prob:
denominator = topk_weight.sum(axis=-1, keepdim=True) + 1e-20
topk_weight = topk_weight / denominator * self.routed_scaling_factor
else:
topk_weight = topk_weight * self.routed_scaling_factor
if self.training and self.alpha > 0.0:
scores_for_aux = scores
aux_topk = self.top_k
topk_idx_for_aux_loss = topk_idx.reshape([bsz, -1])
if self.seq_aux:
scores_for_seq_aux = scores_for_aux.reshape([bsz, seq_len, -1])
ce = paddle.zeros(shape=[bsz, self.n_routed_experts])
ce.put_along_axis_(
axis=1,
indices=topk_idx_for_aux_loss,
values=paddle.ones(shape=[bsz, seq_len * aux_topk]),
reduce=“add”,
).divide_(y=paddle.to_tensor(seq_len * aux_topk / self.n_routed_experts))
aux_loss = (ce * scores_for_seq_aux.mean(axis=1)).sum(axis=1).mean() * self.alpha
else:
mask_ce = paddle.nn.functional.one_hot(
num_classes=self.n_routed_experts, x=topk_idx_for_aux_loss.reshape([-1])
).astype(“int64”)
ce = mask_ce.astype(dtype=“float32”).mean(axis=0)
Pi = scores_for_aux.mean(axis=0)
fi = ce * self.n_routed_experts
aux_loss = (Pi * fi).sum() * self.alpha
else:
aux_loss = None
return topk_idx, topk_weight, aux_loss
-
AI Studio 教程链接:
# clone PaddleMIX代码库 git clone https://github.com/PaddlePaddle/PaddleMIX.git
cd PaddleMIX
安装 PaddlePaddle:
# 提供三种 PaddlePaddle 安装命令示例,也可参考PaddleMIX主页的安装教程进行安装3.0.0b2版本安装示例 (CUDA 11.8)
python -m pip install paddlepaddle-gpu==3.0.0b2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
Develop 版本安装示例
python -m pip install paddlepaddle-gpu==0.0.0.post118 -f https://www.paddlepaddle.org.cn/whl/linux/gpu/develop.html
sh 脚本快速安装
sh build_paddle_env.sh
安装 PaddleMIX 环境依赖包:
# Deepseek-vl2-tiny multi image understanding
python paddlemix/examples/deepseek_vl2/multi_image_infer.py \
--model_path="deepseek-ai/deepseek-vl2-tiny" \
--image_file_1="paddlemix/demo_images/examples_image1.jpg" \
--image_file_2="paddlemix/demo_images/examples_image2.jpg" \
--image_file_3="paddlemix/demo_images/twitter3.jpeg" \
--question="Can you tell me what are in the images?" \
--dtype="bfloat16"
输出结果:
<|User|>: This is image_1: <image>
This is image_2: <image>
This is image_3: <image>
Can you tell me what are in the images?
<|Assistant|>: The first image shows a red panda resting on a wooden platform. The second image features a giant panda sitting among bamboo plants. The third image captures a rocket launch at night, with the bright trail of the rocket illuminating the sky.<|end▁of▁sentence|>
