大连理工&莫纳什大学提出VLIPP框架,利用视觉语言模型提升视频扩散模型生成的物理真实性。实验证明该框架在物理规律视频生成上表现优异。
原文标题:物理视频真实生成!大连理工&莫纳什大学团队提出物理合理的视频生成框架
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到VLIPP在机械运动、流体运动、热力学和材料学等方面表现突出,那么在哪些物理现象的视频生成上可能还存在挑战?为什么?
3、VLIPP框架将视觉语言模型和视频扩散模型结合,这种结合方式有哪些潜在的优势和局限性?未来可能的发展方向是什么?
原文内容

最近,来自大连理工和莫纳什大学的团队提出了物理真实的视频生成框架 VLIPP。通过利用视觉语言模型来将物理规律注入到视频扩散模型的方法来提升视频生成中的物理真实性。

-
论文主页: https://madaoer.github.io/projects/physically_plausible_video_generation/
-
论文链接: https://arxiv.org/abs/2503.23368
视频扩散模型近年来取得了显著进展,能够生成高度逼真的视频内容,其作为世界模拟器的潜力已引起学界广泛关注。然而,尽管功能强大,这类模型由于内在物理理解的缺失,相信大家在使用 VDMs 的时候一定会发现问题:VDMs 生成的视频并不符合物理规律。即使是商用的闭源模型,在物理场景上的表现也不够理想。

本文认为这样的局限有两个原因,首先是视频扩散模型的训练数据一般是文本 - 视频对,其中包含物理现象的数据占比很少,且物理现象在视频中表现存在高度的抽象性和多样性,很难去获取合适的数据来进行训练。其次,扩散模型更多依赖记忆和案例模仿,无法抽象出一般的物理规则,无法真正理解物理。
为突破这一局限,本文提出了一种新颖的符合物理规律的视频生成框架,通过显式引入物理约束来解决该问题。作者发现语言模型对于物理有一定的理解能力,如果告诉语言模型两个正在发生碰撞的小球的位置,它能够大概地预测出这两个小球在发生碰撞之后的后续位置。受此启发,本文提出的生成框架包含两个阶段,第一阶段将视觉语言模型作为粗粒度的运动规划器,使其提供一个粗略的物理可能的运动路径,第二阶段将视频扩散模型作为一个细粒度的运动合成器,根据上一阶段预测的物理可能的路径来生成细粒度的运动。
实验结果表明,本文提出的框架能生成符合物理规律的运动序列,对比评估显示了该方法相较于现有技术在物理视频生成上的显著优越性。这一成果证明了将语言模型的物理知识先验引入扩散模型的可能性,并为扩散模型作为世界模拟器带来了更大的可能性。
方法
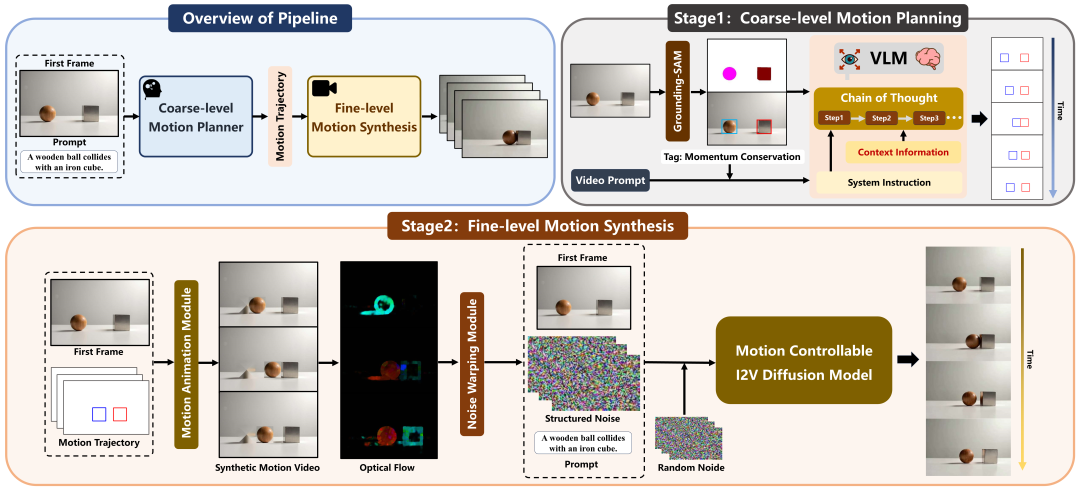
在这项工作中,研究者们提出了一种针对物理场景的视频生成框架,如上图所示,利用视觉语言模型理解物理定律和规划可能的运动路径,根据预测的路径在运动可控的扩散模型中生成视频。
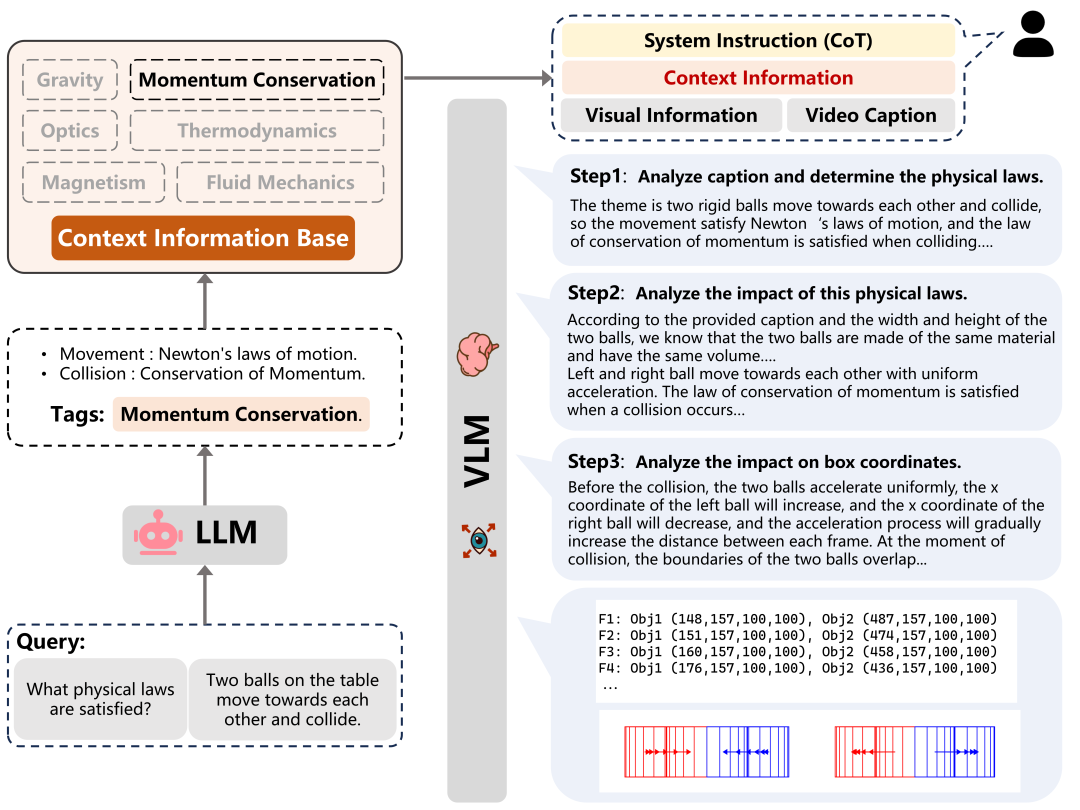
具体来说,在第一阶段中,作者将视频中常见的物理现象分为六类:重力、动量守恒、光学、热力学、磁学和流体力学,语言模型根据视频的场景描述提取符合该场景的物理定律,结合物理定律和图像信息进行思维链式推理,逐步分析物理定律带来的影响,以及其在视觉空间上的对应,最终预测出图像空间内对象的未来边界框位置。
第二阶段中,扩散模型需要根据预测的运动路径进行视频生成。作者认为在上一阶段中视觉语言模型可能存在幻觉和规划错误的情况,因此规划的路径只能作为粗粒度的运动引导。在本阶段通过规划的运动路径合成运动序列,并根据光流计算得到结构化噪声,结合视频扩散模型的生成先验来细化粗略的生成先验,以生成与真实世界动态一致的物理上合理的运动。
实验结果

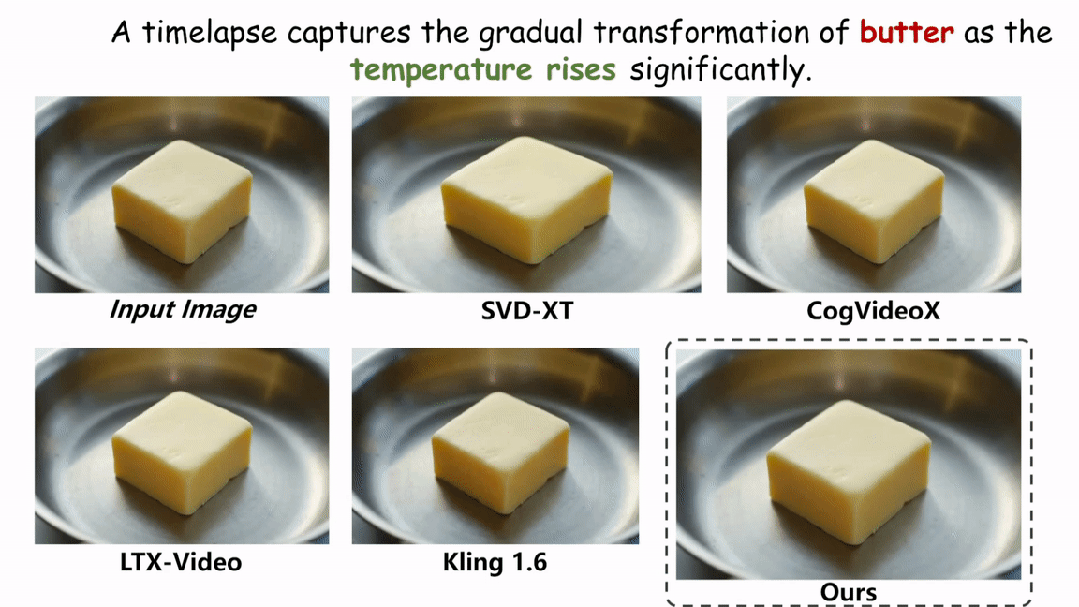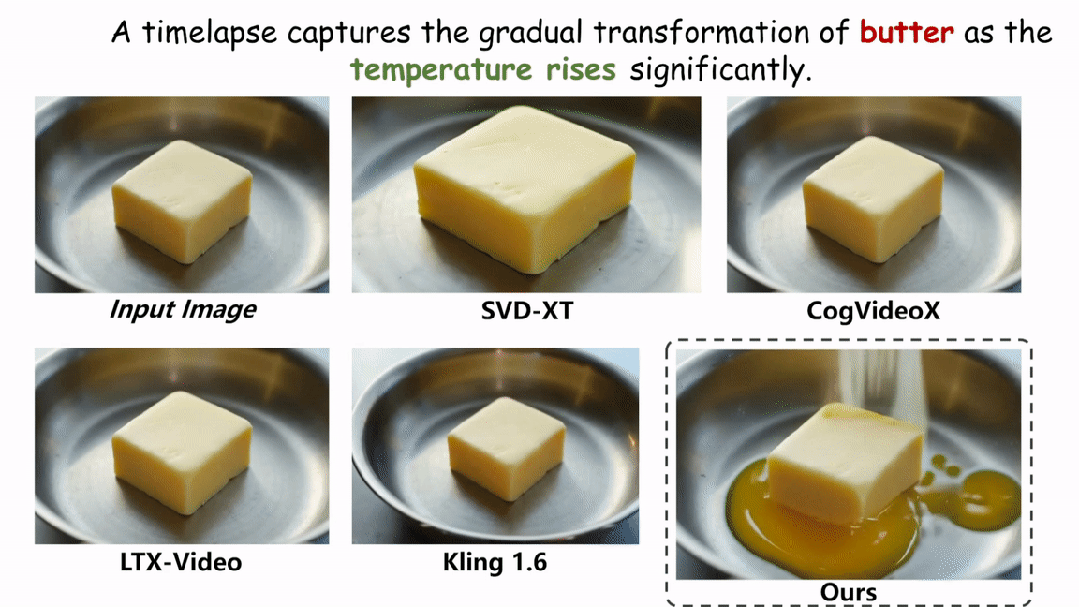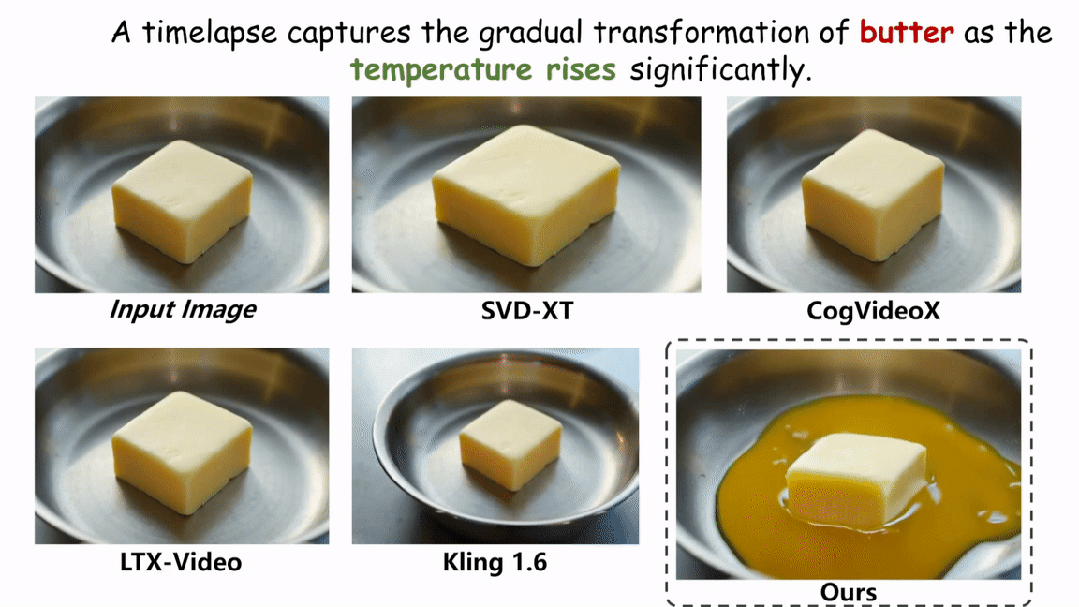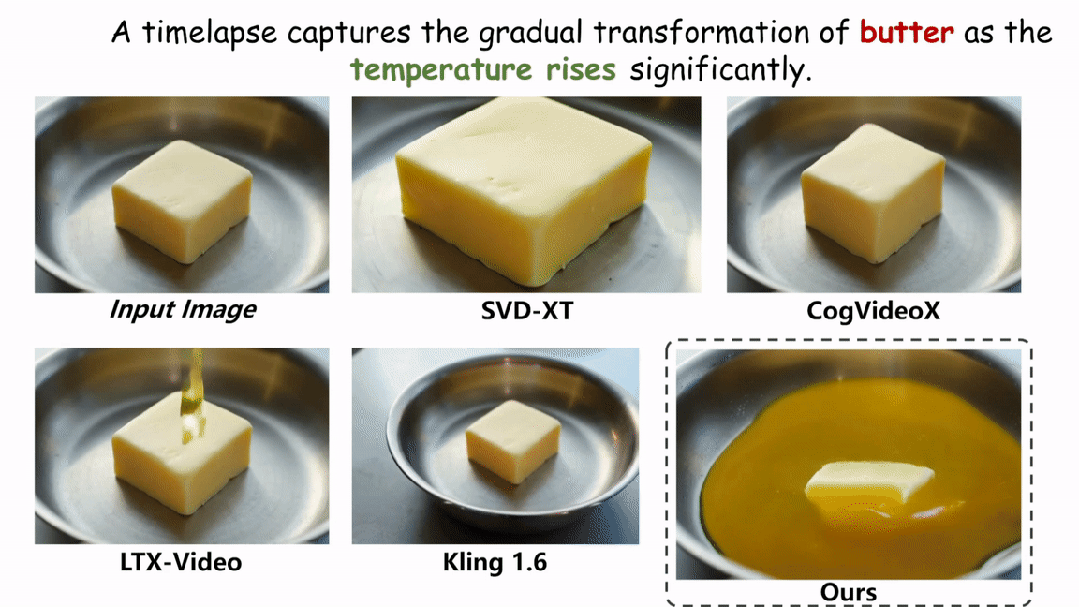


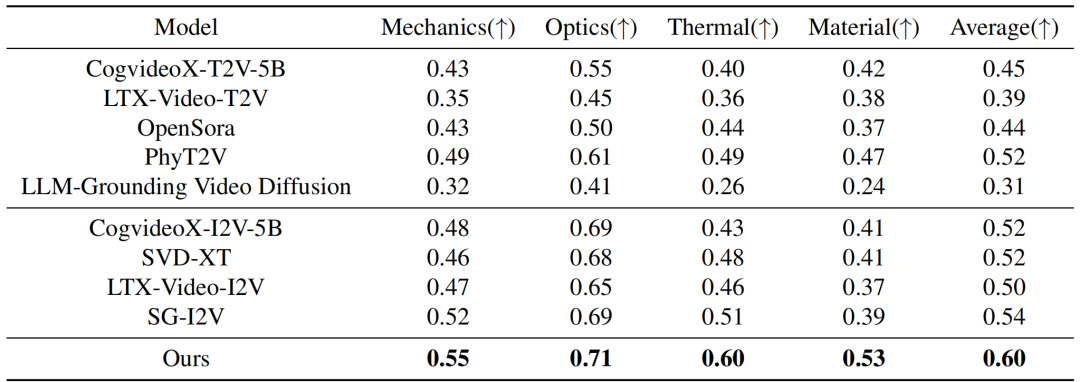
在实验环节,本文在两个评估物理场景视频真实性的指标上与现有的方法进行了定性和定量的对比。如图和表所示,本文的方法在两个评估指标 Physical-IQ 和 PhyGenBench 上都取得了最佳的表现效果,并在机械运动、流体运动、热力学和材料学等方面表现突出。

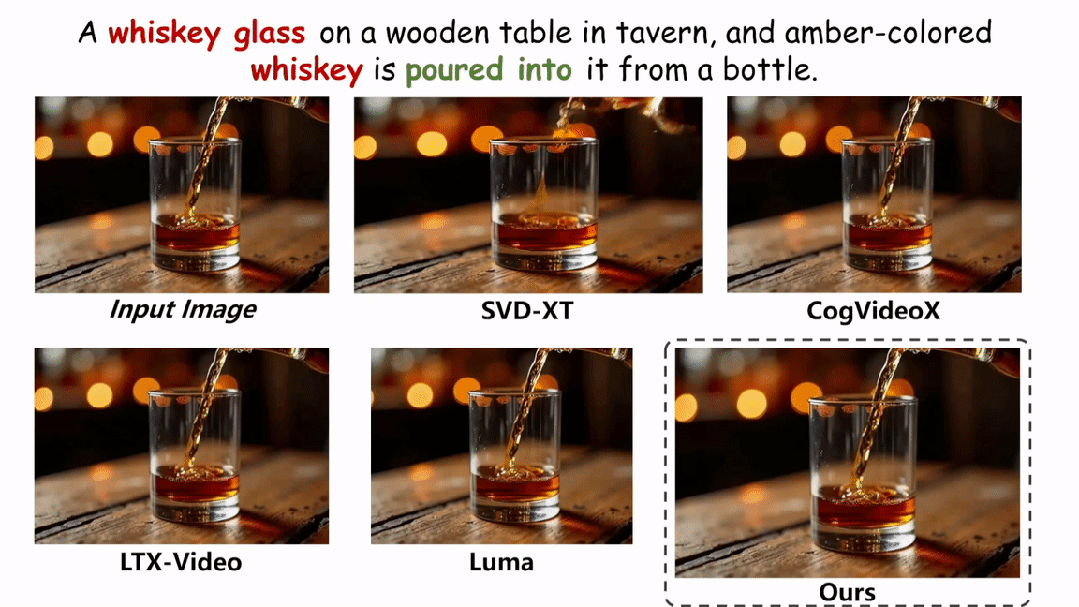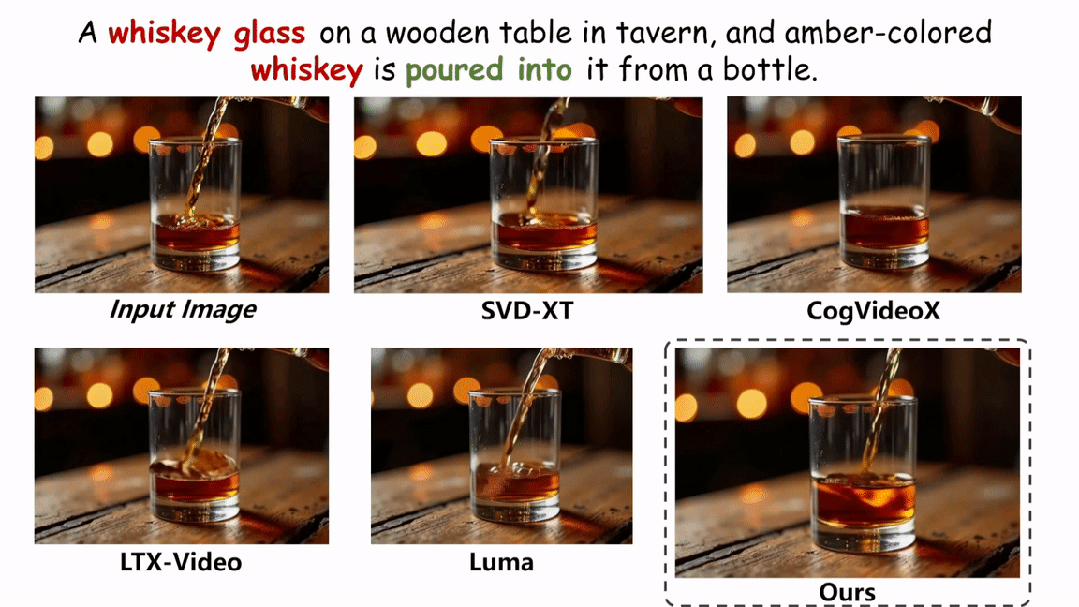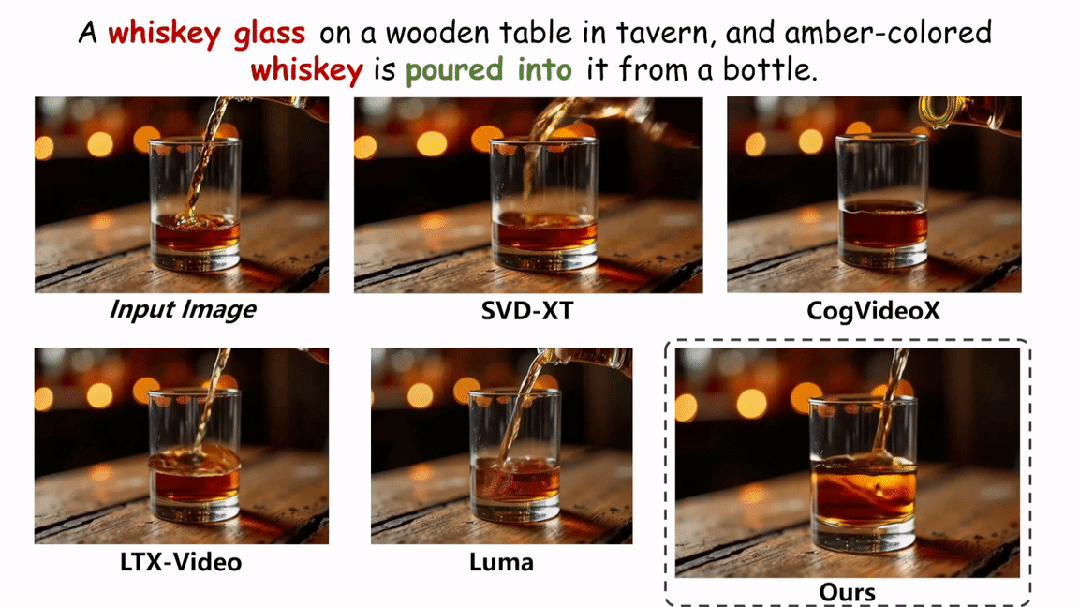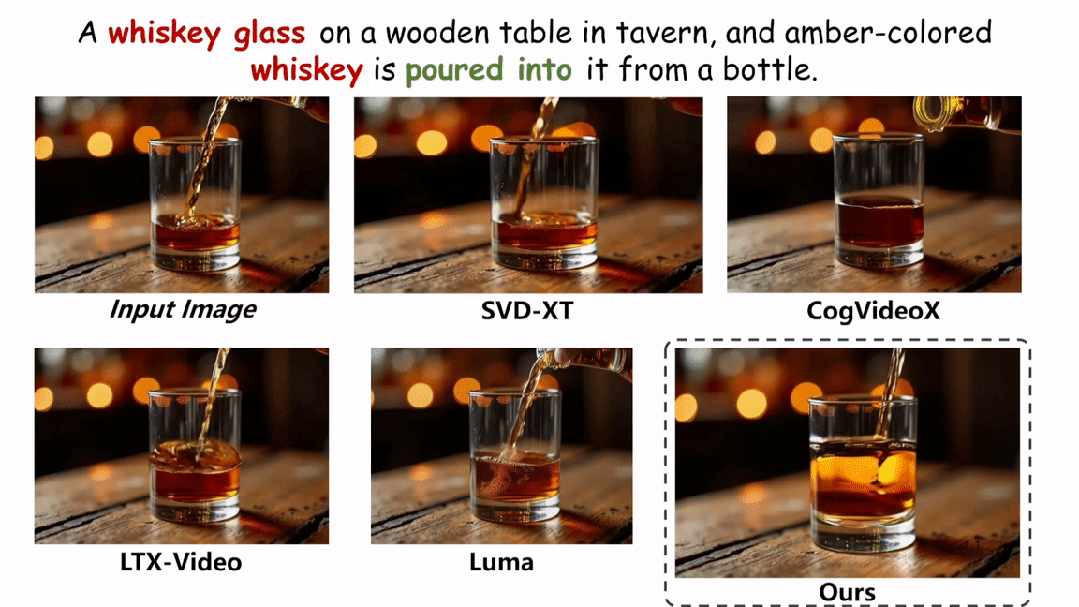
下面展示更多的实验结果。


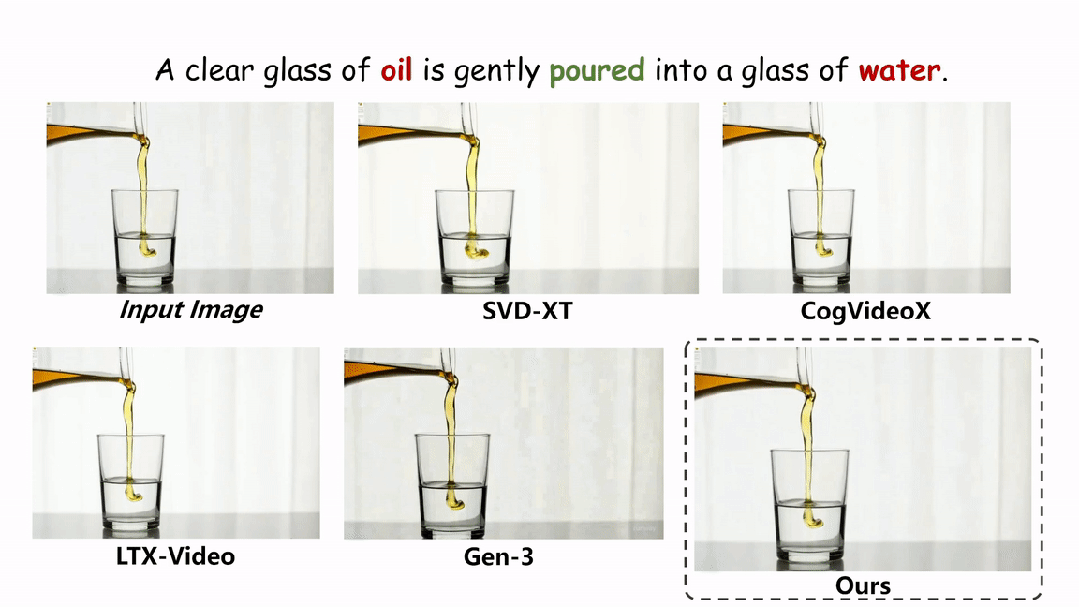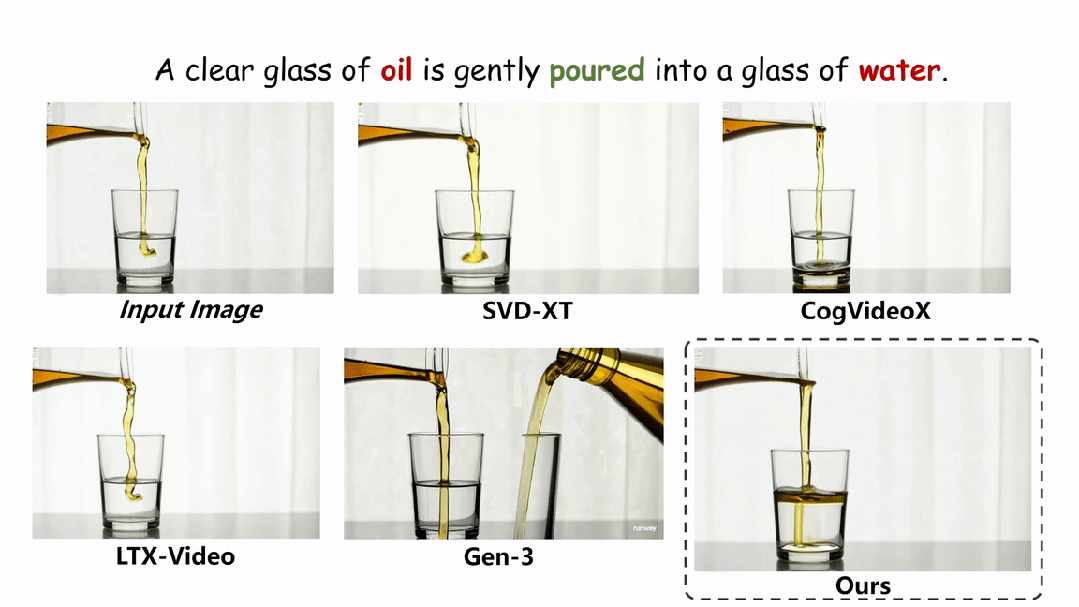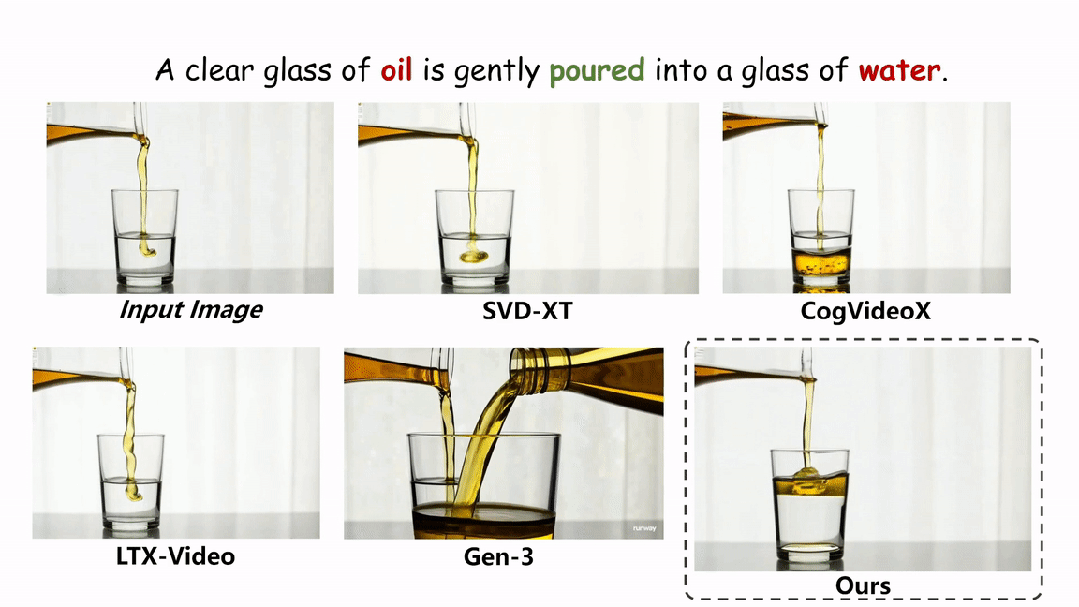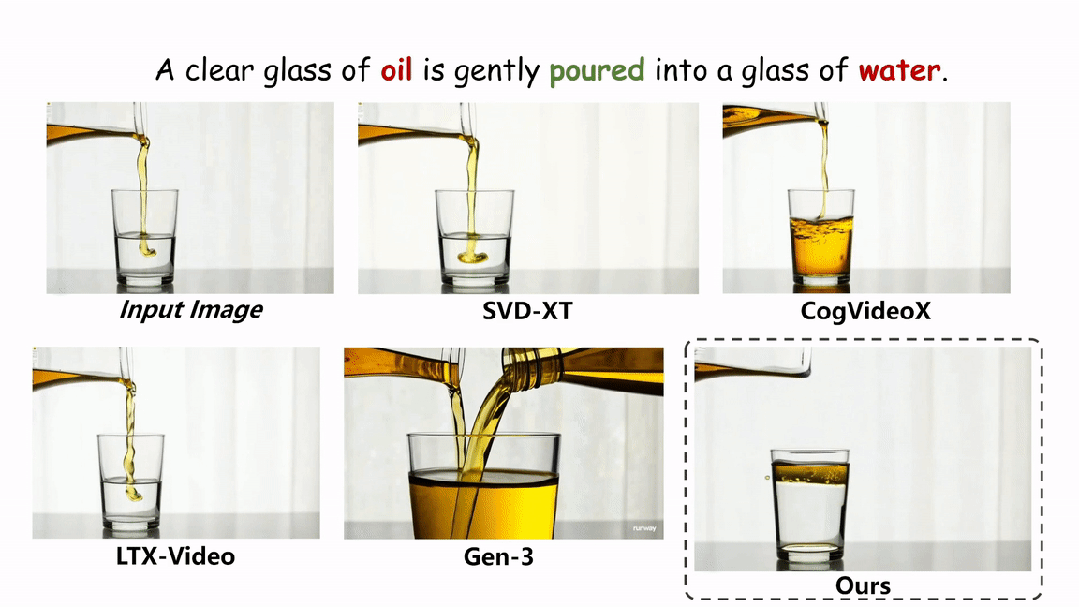


结论
虽然 VDMs 现在能够生成视觉真实程度非常高的视频,但由于它本身缺乏对于物理定律的理解从而无法生成物理可能的视频。本论文提出了新颖的视频生成框架,通过将物理定律注入到 VDMs 中来提升对物理的理解。实验结果验证了我们的视频生成框架要明显优于现在的方法。这一成果证明了将语言模型的物理知识先验引入扩散模型的可能性,并为扩散模型作为世界模拟器带来了更大的可能性。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com