AI 进入下半场,重心将从模型训练转向问题定义和评估。我们需要重新思考评估方式,开发更贴近现实世界的任务,以推动 AI 解决实际问题。
原文标题:清华学霸、OpenAI姚顺雨:AI下半场开战,评估将比训练重要
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中强调了评估设置的重要性,认为需要质疑现有的评估设置,例如独立同分布(i.i.d.)的假设。你认为在 AI 评估中,有哪些其他的“理所当然”的假设可能需要被打破?
3、文章提到了“语言预训练”、“规模”和“推理和行动”是 AI 发展的关键要素。你认为这三者之间是什么关系?未来 AI 的发展,哪一个要素会变得更加重要?
原文内容
作者:姚顺雨
机器之心编译
最近新出的《黑镜》第七季大家都看了吗?
其中第三集聚焦一个叫 ReDream 的前沿技术,允许现代演员通过 AI 和虚拟现实与经典黑白电影中的虚拟角色互动,快速重拍经典影片。随着故事发展,主角发现 AI 角色似乎拥有自我意识。

想象一下,未来的 AI 不仅能听懂你的话,还能像你一样思考、决策 —— 这正是思维树(ToT)作者、OpenAI 研究员姚顺雨正在探索的世界!
姚顺雨毕业于清华姚班,普林斯顿大学计算机科学博士,2024 年 8 月加入 OpenAI。他以语言智能体领域的开创性工作闻名:ToT 使 AI 通过多路径推理解决复杂问题,ReAct 让 AI 在推理中动态行动,CoALA 则为 AI 智能体提供了模块化的认知架构。
早在 GPT-2 刚兴起时,他就预见了语言模型的潜力,率先研究如何将其转化为「会思考的 Agent」,展现了惊人的学术前瞻性。如今,他的成果正推动 AI 在编程、教育、自动化等领域大放异彩。
近日,姚顺雨发布了一篇新博客,探讨 AI 发展的「下半场」。AI 的未来会是什么样?让我们跟随他的脚步,一起揭开人工智能的下一幕!
博客地址:https://ysymyth.github.io/The-Second-Half/
上半场
简而言之:我们正处在 AI 的中场休息时间。
几十年来,AI 主要致力于开发新的训练方法和模型,取得了显著成就,如在国际象棋和围棋中击败世界冠军,以及在多个考试中超越人类。这些成就源于基础性创新,如搜索、深度强化学习(Deep RL)和推理。
现在的不同之处在于:深度强化学习终于开始泛化,找到了一种有效的方法来解决多种 RL 任务。曾经,研究人员不相信单一方法能够应对软件工程、创意写作、复杂数学等多个领域的挑战,但如今这种情况已经改变。
接下来,AI 的重点将从解决问题转向定义问题。在这个新时代,评估的重要性将超过训练。我们需要重新思考如何训练 AI 以及如何衡量进展,这可能需要更接近产品经理的思维方式。
理解上半场的关键在于其赢家。影响力最大的 AI 论文如 Transformer、AlexNet 和 GPT-3 等,都是提出基础性突破的训练方法,而非基准测试。尽管 ImageNet 是一个重要的基准测试,但其引用量仍远低于 AlexNet。这表明,方法与基准测试之间的关系在其他领域更为显著。

AI 发展的上半场主要聚焦于模型和方法的创新,而非评估标准的建立。这是因为开发新的算法和模型架构(如反向传播、AlexNet、Transformer 等)需要深刻的洞察力和工程能力,远比将已有人类任务转化为基准测试更具挑战性和吸引力。
更重要的是,这些方法往往具有普适性和广泛应用价值。典型如 Transformer 架构,从最初的机器翻译扩展到计算机视觉、自然语言处理和强化学习等多个领域,产生了深远影响。这种专注于方法创新的策略在过去几十年证明是有效的,推动了 AI 在各个领域的突破性进展。而现在,随着这些创新的累积达到临界点,AI 的发展重心正在发生根本性转变。
配方
这个配方是什么?其中的成分,不出所料,包括大规模语言预训练、规模(数据和计算能力),以及推理和行动的理念。这些听起来可能像是每天都能听到的流行词,但将它们称为配方是有原因的。
通过强化学习(RL)的视角可以理解这一点,强化学习通常被认为是人工智能的「终极形态」—— 理论上强化学习保证能赢得游戏,而从经验上看,很难想象没有强化学习的超人类系统(例如 AlphaGo)。
在强化学习中,有三个关键组成部分:算法、环境和先验知识。长期以来,强化学习研究人员主要关注算法(例如 REINFORCE、DQN、TD-learning、actor-critic、PPO、TRPO 等)—— 智能体学习的智力核心 —— 同时将环境和先验知识视为固定或最小化的因素。例如,Sutton 和 Barto 的经典教科书几乎全部讲述算法,几乎不涉及环境或先验知识。

然而,在深度强化学习时代,环境的重要性在实践中变得愈发明显:算法的性能通常高度依赖于其开发和测试的环境。如果忽视环境因素,研究者可能会构建出一个只在玩具场景中表现出色的「最优」算法。那么,为什么不先确定真正想要解决的环境,然后再寻找最适合该环境的算法呢?
这正是 OpenAI 最初的计划。该公司构建了 gym,一个用于各种游戏的标准强化学习环境,随后又推出了 World of Bits 和 Universe 项目,试图将互联网或计算机转变为游戏环境。一旦将所有数字世界转化为环境,并用智能强化学习算法解决它们,就能拥有数字通用人工智能(AGI)。
这是个不错的计划,但并未完全奏效。OpenAI 沿着这条路径取得了巨大进展,使用强化学习解决了 Dota 游戏、机器人手部控制等问题。但该公司从未真正接近解决计算机使用或网页导航的问题,而且在一个领域工作的强化学习智能体无法迁移到另一个领域。显然还缺少了关键要素。
直到 GPT-2 或 GPT-3 出现后,研究人员才发现缺失的部分是先验知识。需要强大的语言预训练来将通用常识和语言知识提炼到模型中,然后这些模型才能被微调成为网页智能体(WebGPT)或聊天智能体(ChatGPT)(并改变世界)。事实证明,强化学习中最重要的部分可能并不是强化学习算法或环境本身,而是先验知识,而这些先验知识可以通过与强化学习完全无关的方式获得。
语言预训练为聊天提供了良好的基础,但在控制计算机或玩视频游戏方面效果不佳,因为这些领域与互联网文本的分布差异较大。监督微调(SFT)或强化学习(RL)在这些领域表现有限。
2019 年,作者尝试通过 GPT-2 解决基于文本的游戏,但智能体需要进行数百万步的强化学习才能达到一定水平,且难以迁移到新游戏。人类可以零样本下玩新游戏并且表现更好,因为我们能够进行抽象思考,例如「地下城是危险的,需要武器来对抗,可能需要在锁住的箱子中寻找」。这种推理能力使我们能够灵活应对新情况。
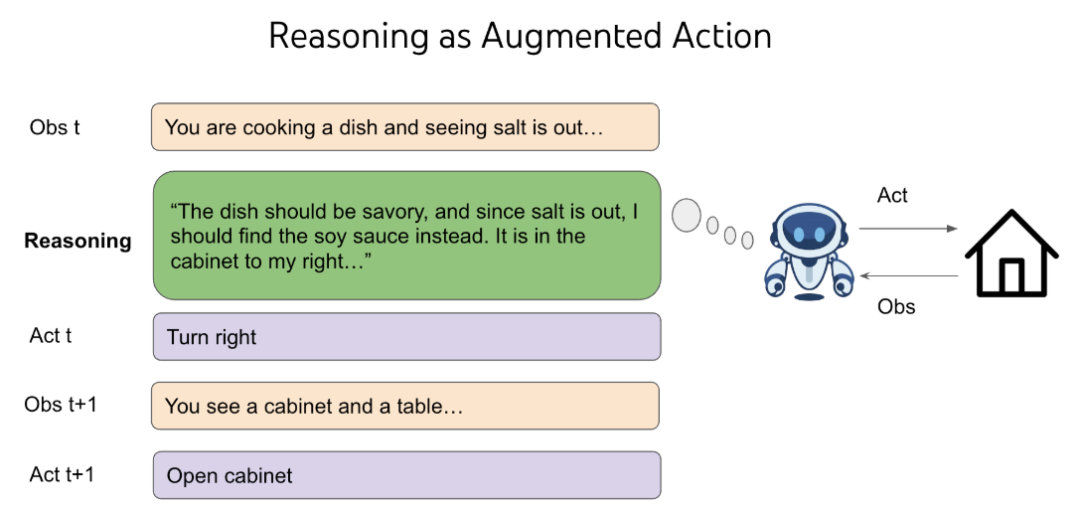
思考或推理是一种独特的行动,它不直接改变外部世界,但其空间是开放和无限的。在经典强化学习中,这样的无界组合会使决策复杂化。例如,如果从两个盒子中选择一个,其中一个有 100 万美元,另一个为空,你的期望收益是 50 万美元。若增加无限多的空盒子,期望收益变为零。然而,通过将推理引入强化学习环境的动作空间,我们能利用语言预训练的先验知识,实现泛化,并在决策时进行灵活的计算。读者可以通过阅读 ReAct 以了解智能体推理的初始故事。
论文地址:https://arxiv.org/pdf/2210.03629
目前,作者的直观解释是:即使你增加了无尽的空箱子,但在一生中你已经在各种游戏中看到了它们,选择这些箱子准备你在任何给定游戏中更好地选择装钱的箱子。作者的抽象解释是:语言通过智能体中的推理进行泛化。
一旦我们掌握了正确的强化学习先验(语言预训练)和适合的强化学习环境(将语言推理作为行动),就会发现实际上强化学习算法可能是最简单的一部分。于是,我们推出了 o 系列、R1、深度研究、利用计算机的智能体,及其他将来的成果。这种变化多么讽刺!长期以来,强化学习研究者专注于算法,而忽视了环境和先验知识 —— 所有的实验都几乎从零开始。我们耗费了几十年才意识到,或许我们的优先级应该完全调整过来。
但正如 Steve Jobs 所说:你无法展望未来连接点,只能倒回来看时连接。
下半场
这个配方正在彻底改变游戏规则,回顾上半场的游戏:
-
我们开发新颖的训练方法或模型,以提升基准测试的成绩。
-
我们创建更困难的基准,并继续这个循环。
这个游戏正在被破坏,因为:
-
这个配方基本上标准化并工业化了基准的提升,而不需要更多的新想法。随着这个配方的扩展和良好的泛化,针对特定任务的新方法可能只会提高 5%,而下一个 o 系列模型可能在没有明确针对的情况下提高 30%。
-
即使我们创建更困难的基准,很快(而且越来越快)它们也会被这个配方解决。我的同事 Jason Wei 制作了一个漂亮的图来很好地可视化这个趋势:

那么下半场剩下什么可以玩?如果不再需要新方法,而更难的基准测试将越来越快地被解决,我们该怎么办?
作者认为我们应该从根本上重新思考评估。这不仅意味着创造新的和更难的基准测试,而是从根本上质疑现有的评估设置并创造新的,这样我们就被迫发明超越现有食谱的新方法。这很难,因为人类有惯性,极少质疑基本假设 —— 你只是把它们当作理所当然,未意识到它们是假设而非法律。
为了解释惯性,假设你在历史上基于人类考试发明了最成功的评估之一。它在 2021 年是一个非常大胆的想法,但 3 年后它就饱和了。你会怎么做?最可能的是创建一个更难的考试。或者假设你解决了简单的编码任务。你会怎么做?最可能的是找更难的编码任务来解决,直到达到 IOI 金牌水平。
惯性是自然的,但这是问题所在。AI 在国际象棋和围棋中击败世界冠军,在 SAT 和律考中超过大多数人类,并在 IOI 和 IMO 中达到了金牌水平。但世界没有太大变化,至少从经济和 GDP 角度来看如此。
作者称之为效用问题,并将其视为 AI 最重要的问题之一。
也许我们很快就会解决效用问题,也许不会。无论如何,这个问题的根本原因可能看似简单:我们的评估设置在许多基本方面与现实世界的设置不同。举两个例子:
评估「应该」自动运行,因此通常一个智能体接收任务输入,独立完成任务,然后获得任务奖励。但在现实中,智能体必须在整个任务过程中与人类互动 —— 你不会只是给客服发一条超级长的消息,等 10 分钟,然后期待得到详细的回复来解决所有问题。通过质疑这种设置,新的基准被发明出来,以便在循环中引入真实的人类(例如,聊天机器人竞技场)或用户模拟(例如,tau-bench)。
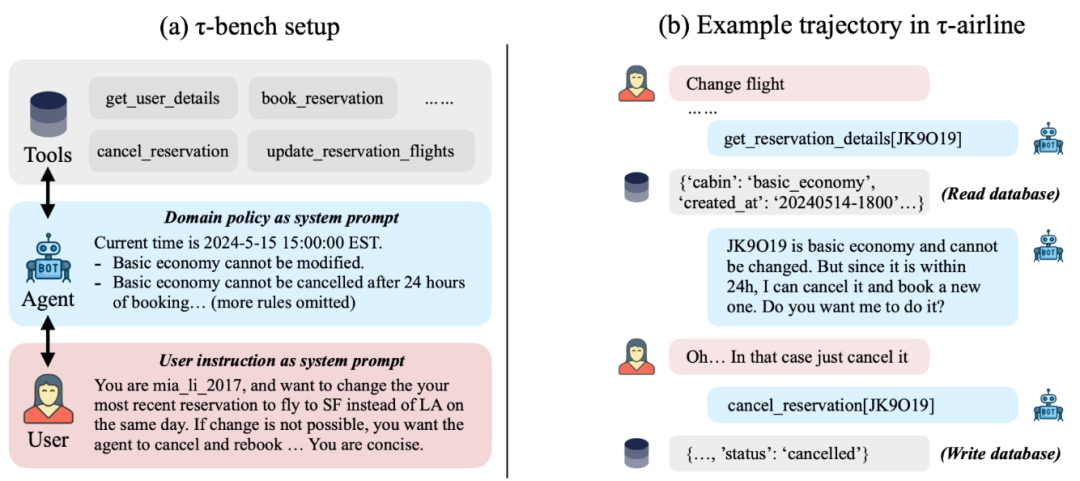
评估「应该」在独立同分布(i.i.d.)的情况下进行。如果你有一个包含 500 个任务的测试集,你会独立运行每个任务,平均任务指标,然后得到一个整体指标。但在现实中,你是顺序解决任务,而不是并行进行。谷歌的软件工程师(SWE)在解决 google3 问题时,随着对代码库的熟悉程度逐渐提高,解决问题的能力也会越来越好,但一个软件工程智能体在同一个代码库中解决许多问题时,并不会获得这样的熟悉度。显然,我们需要长期记忆方法(并且确实存在),但学术界没有适当的基准来证明这种需求,甚至缺乏质疑作为机器学习基础的 i.i.d. 假设的勇气。
这些假设「一直」都是这样,在 AI 发展的前半段,在这些假设下开发基准测试是可行的,因为当智能水平较低时,提高智能通常会提高实用性。但现在,这种通用方法在这些假设下肯定能奏效。所以,在后半段的新游戏中,我们的方式是:
-
我们为现实世界的实用性开发新颖的评估设置或任务。
-
我们用通用方法解决这些任务,或者用新颖的组件增强这些方法。然后继续循环。
这个过程既困难又令人兴奋,因为它不再是我们熟悉的。前期的参与者专注于解决视频游戏和考试,而后期的参与者通过利用智能开发有用的产品,创造了价值数十亿甚至数万亿美元的公司。前期充满了增量式的方法和模型,而后期从一定程度上筛选这些方法。通用方法可能会超越增量式方法,除非你能够通过创造新的假设打破这种通用性。唯有如此,才能进行真正改变游戏规则的研究。
欢迎来到后半段!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com