伯克利&英伟达提出PS3,首次实现4K分辨率视觉预训练,多模态大模型VILA-HD在4KPro基准测试中,精度提升3.2%,速度提升3倍。
原文标题:4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理
原文作者:机器之心
冷月清谈:
怜星夜思:
2、VILA-HD通过选择性处理高清图片来提升效率,那么在实际应用中,如何确定哪些区域是需要处理的“相关区域”?使用图像显著性或自然语言控制,各自的优缺点是什么?
3、4KPro数据集强调了高分辨率图像感知能力的重要性,那么在哪些具体的行业或应用场景中,真正需要并能够充分利用4K甚至更高分辨率的视觉信息?仅仅是分辨率的提升就足够了吗?还需要哪些配套的技术或算法?
原文内容

当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
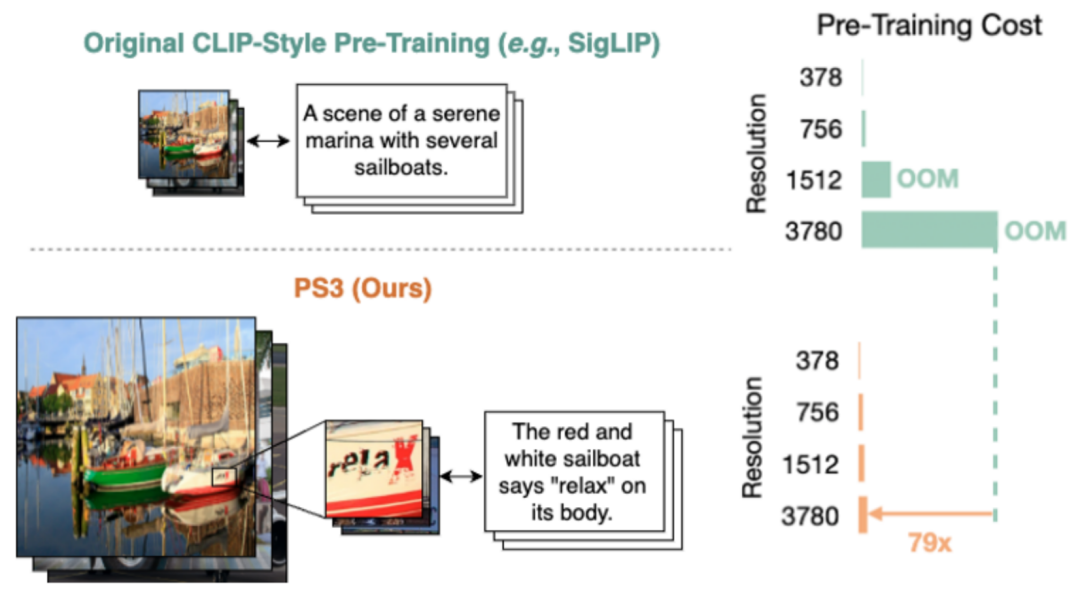
然而,当前视觉模型预训练很难提升到更高的分辨率,核心原因在于计算代价过于高昂。比如 SigLIP,在预训练过程中需要编码整张图像,计算复杂度至少与图像分辨率二次增长,导致训练成本暴涨,几乎无法承受。
近日,伯克利联合英伟达提出一项突破性成果:PS3 视觉编码器,首次实现了在 4K超高分辨率下的高效视觉预训练并且没有额外开销,并在此基础上提出多模态大模型 VILA-HD。相比于目前最先进的多模态大模型(如 Qwen2-VL),VILA-HD 提升了高清场景下的表现和效率。
更关键的是,研究团队还发布了一个强挑战性的高分辨率视觉基准测试集:4KPro。在这个数据集上,VILA-HD 相比于 Qwen2-VL 提升了 3.2% 的准确率并且实现了三倍的加速。
研究团队也开放了全部内容,该研究已被 CVPR 2025评为 Highlight 论文。

论文标题:Scaling Vision Pre-Training to 4K Resolution
论文地址:https://arxiv.org/abs/2503.19903
项目主页:https://nvlabs.github.io/PS3/
代码库(即将开源):https://github.com/NVLabs/PS3
模型权重:即将发布
一、PS3
4K 超高清视觉预训练
高清预训练所遇到的困难
当前主流视觉模型之所以不能在 4K 下预训练,是因为在高分辨率下需要整图编码,计算复杂度至少与图像分辨率二次增长。这使得目前模型很难在 1K 或以上的分辨率进行预训练。
但伯克利 & 英伟达团队发现,识别局部细节无需整图理解。于是他们提出局部对比学习的训练范式,使得 PS3 能够在没有额外开销的情况下将预训练分辨率提高到 4K。
局部对比学习:「免费」的高清预训练
传统方法,例如 SigLIP,会对全局视觉表征和全局文字描述表征做对比学习。与之相比,PS3 采用局部对比学习策略:仅对图像中的局部区域与局部区域的细节描述进行编码和对比。这种方式不仅保留了高分辨率的细节理解能力,由于模型不需要处理整张高清图像而只需要处理局部区域,也极大降低了计算成本。
实验显示,该方法训练时间可以比直接在 4K 分辨率上预训练节省 79 倍,与低分辨率预训练 SigLIP 相近,却能处理高达 4K 分辨率图像,实现前所未有的精细表示能力。
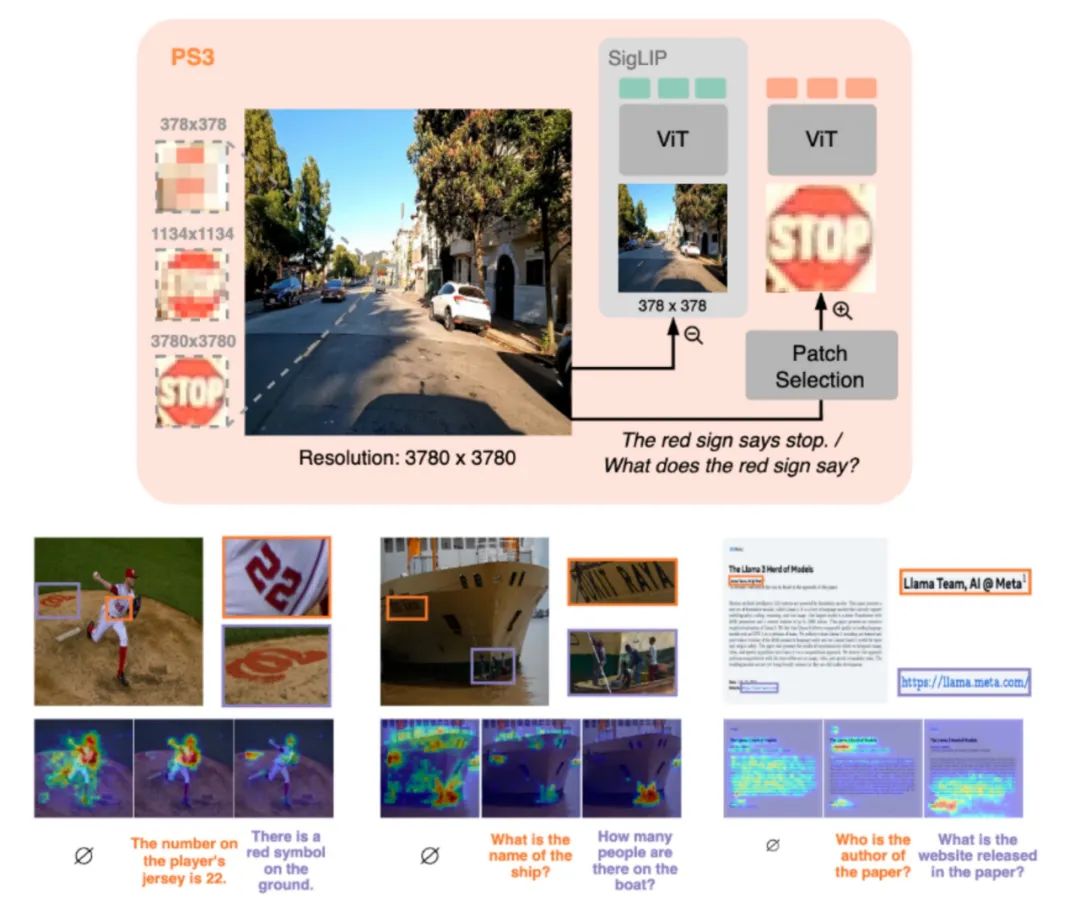
PS3 关键设计:选择性处理高清图片
PS3 并非盲目处理所有像素,而是动态选择性地采样图像区域:既可以使用图像显著性,也可以用任何自然语言来控制处理的区域。
此外,PS3 设计支持灵活的计算资源控制 —— 用户可以根据场景需要,调整高分辨率 patch 的数量,平衡速度与性能。
二、VILA-HD
基于 PS3 的高分辨率 MLLM
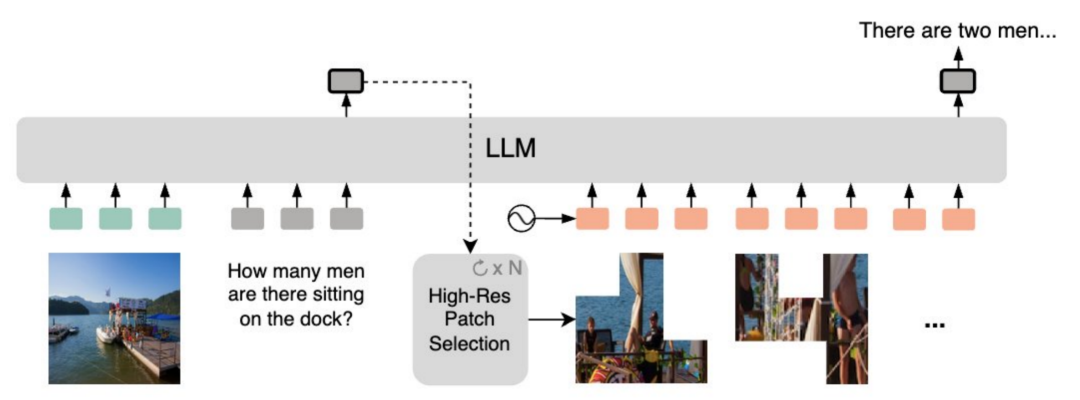
基于 PS3,团队构建了多模态大模型 VILA-HD,其核心优势在于:
-
细节感知能力超过现有 MLLMs(如 Qwen2-VL)。这得益于 PS3 的高清视觉预训练提升了细节理解能力。
-
响应速度也比现有 MLLM 更快:VILA-HD 可根据提示只处理图像中相关区域,而不是一口吃下整张图。这使得 VILA-HD 比当前基于 AnyRes/S2 等处理整张高清图的 MLLM 速度更快。
-
根据用户需求灵活调整响应速度:VILA-HD 可以灵活调整处理的高清区域大小,从而可以适应不同的推理开销要求。

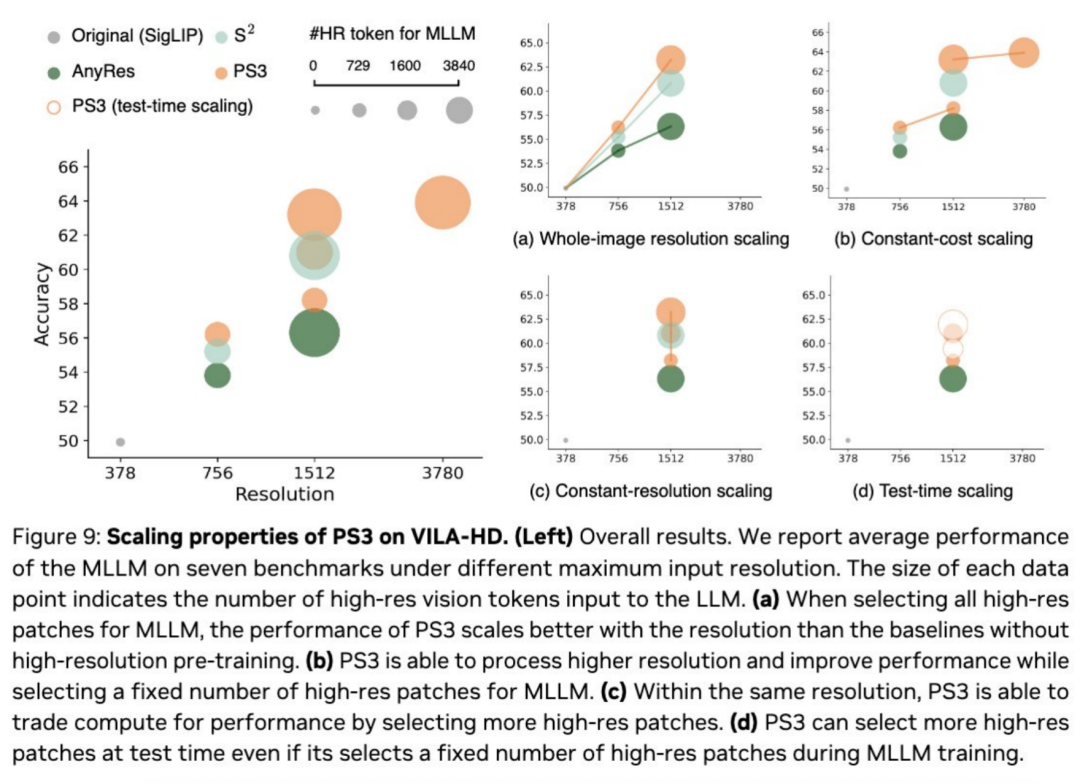
更有趣的是,团队发现在 VILA-HD 上,PS3 展现了不同的有趣的扩展能力。在提升下游任务分辨率时,PS3 的性能比没有高清预训练的模型性能提升的要更快。PS3 还可以在提升分辨率的同时选择固定大小的高清区域,从而在训练与推理开销保持不变的情况下提升性能。除此之外,PS3 还可以通过扩展训练或测试时的计算量来进一步提高性能。
三、仅有高分辨率还不够
我们还需要高分辨率的 Benchmark
研究者们发现,当前绝大多数视觉问答评测集,即使图像是 4K 分辨率,实际任务却不需要这么高的分辨率来解题。他们引入了一个新概念:MRR(Minimum Recognizable Resolution):完成某个任务所需的最小有效图像分辨率。
分析显示,大量数据集的 MRR 实际低于 1K,因此难以衡量高分辨率模型的真实优势。
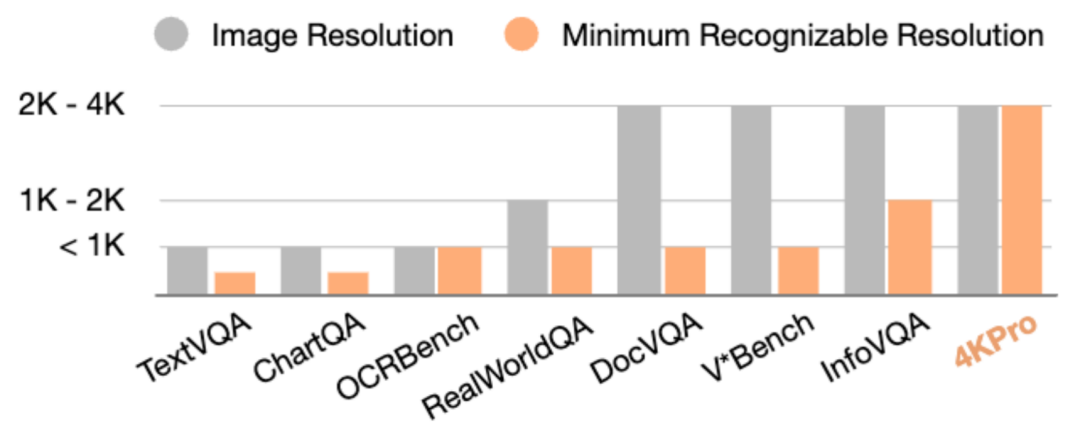
为此,研究团队推出了 4KPro —— 这是一个真正需要 4K 级图像感知能力才能完成的高分辨率基准测试。4KPro 在自动驾驶,家务家居,游戏 agent,UI 理解四个专业领域收集了 4K 分辨率的图片以及需要 4K 分辨率才能回答的问题。
在 4KPro 上,VILA-HD 显著优于现有 SOTA 多模态模型,比如相对 Qwen2-VL 提升了 3.2% 的准确率,同时在处理速度上可以实现最高 3 倍加速。
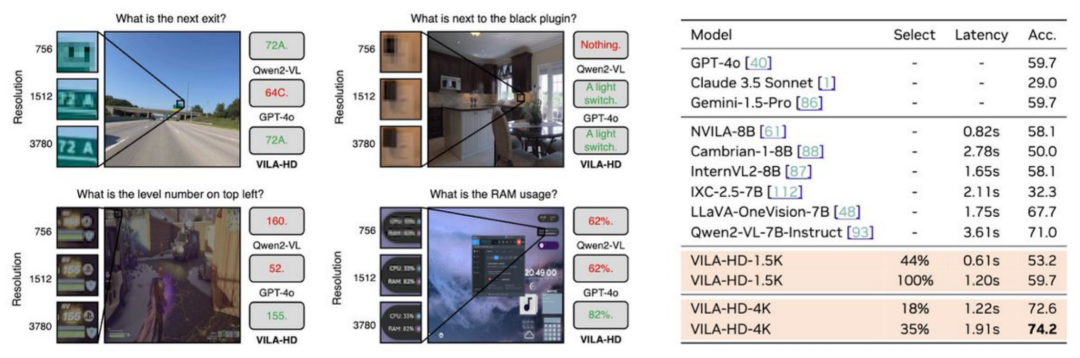
PS3 + VILA-HD 打破了长久以来视觉预训练只能处理小图像的桎梏,为真实世界应用(如自动驾驶、自动代理、家用机器人、工业检测、医学图像等)打开了新的可能。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com