小鹏汽车发布720亿参数世界基座模型,加速端到端智驾发展,并自研AI芯片,预计2025年底落地L3级智能驾驶。
原文标题:72B世界基座模型启动,小鹏的端到端智驾正在验证Scaling Laws
原文作者:机器之心
冷月清谈:
怜星夜思:
2、小鹏的“云端模型工厂”概念很有意思,可以为不同需求的汽车定制不同的“大脑”。你觉得这种定制化,未来可能体现在哪些方面?例如驾驶风格、特定场景优化等等?
3、小鹏提到未来会将基模部署到AI机器人、飞行汽车等设备上。你认为这种通用模型思路,在不同物理形态的AI终端上,会面临哪些技术挑战和伦理考量?
原文内容
作者:泽南
最近一段时间,各家新势力都在角力部署端到端的智能驾驶系统。
作为公认的新范式,它可以让整个智能驾驶系统反应更快,更加拟人,能处理以往方法无法解决的大量 corner case,被认为是自动驾驶通向 L3、L4 的正确方向。
在国内,小鹏于去年 7 月就宣布了量产端到端大模型上车,并构建了从算力、算法到数据的全面体系,在端到端方向上一直保持着领先的身位。
本周,小鹏在 AI 技术分享会上介绍了自己在智能驾驶领域的重要突破和进展,首次披露了正在研发 720 亿参数的超大规模自动驾驶大模型,即「小鹏世界基座模型」。
小鹏的技术人员表示,在物理世界,信息和模态的复杂程度要比数字世界复杂数倍,自动驾驶本质上是物理世界中的复杂 AI 问题,也是具身智能的第一步。
小鹏发展的云端世界基座模型以大语言模型为骨干,使用海量的优质多模态驾驶数据进行训练,具备视觉理解、链式推理和动作生成能力。通过强化学习训练,其基座模型可以不断自我进化,逐步发展出更全面、更拟人的自动驾驶技术。

小鹏汽车自动驾驶负责人李力耘表示,小鹏早在去年就开始布局 AI 基础设施,建成了国内汽车行业首个万卡智算集群,用以支持基座模型的预训练、后训练、模型蒸馏、车端模型训练等任务,小鹏将这套从云到端的生产流程称为「云端模型工厂」。
端到端大模型虽然是各家车企的共识,但仍然面临着算力等瓶颈。当前主流的智驾系统,如运行在 2× 英伟达 Orin 芯片上的系统,大部分只能支持 0.5-1 亿参数,在部署时必须对学习到的知识进行取舍。相比之下,云端大模型体量可以达到车端模型的 140 倍以上。
自去年下半年开始,小鹏面向 L4 级别的自动驾驶启动研发全新的「AI 大脑」,即小鹏世界基座模型。
其团队利用优质自动驾驶训练数据先后开发了多个尺寸的基座模型,目前正在着手推进 72B(72 Billion,即 720 亿)超大规模参数世界基座模型的研发,参数量是主流 VLA 模型的 35 倍左右。

据介绍,该模型的一大优势是具备链式推理能力(CoT),能在充分理解现实世界的基础上像人类一样进行复杂常识推理,并做出行动决策,如输出方向盘、刹车等控制信号,实现和物理世界的交互。
小鹏希望通过基座模型的能力让智驾系统从「模仿人类」进化到「超越人类」,最终能够处理全场景的自动驾驶问题,包括一些模型从未在训练数据中遇到的问题。
更进一步,端到端模型的研究也可以延伸到整个具身智能领域。李力耘表示:「世界基座模型是小鹏自动驾驶真正走向 L3、L4 的基础,也会是未来小鹏所有物理 AI 终端的通用模型。」
从零打造云端模型工厂
小鹏的云端模型工厂「车间」涵盖基座模型预训练和后训练(强化学习)、模型蒸馏、车端模型预训练到部署上车的完整生产链路。整个体系采用强化学习、模型蒸馏的技术路线,能够生产出小体量、高智能的端侧模型,甚至为不同需求的汽车定制不同的「大脑」,让「千人千面」的模型研发成为可能。

目前,小鹏依靠自有万卡集群已拥有 10 EFLOPS 的算力,集群运行效率常年保持在 90% 以上,从云到端的全链路迭代周期可达平均 5 天一次。
小鹏世界基座模型负责人刘博士介绍,多模态模型训练的主要瓶颈不仅是 GPU,也需要解决数据访问的效率问题。小鹏汽车自主开发了底层的数据基础设施(Data Infra),使数据上传规模提升 22 倍、训练中的数据带宽提升 15 倍;通过联合优化 GPU / CPU 以及网络 I/O,最终使模型训练速度提升了 5 倍。目前,小鹏汽车用于训练基座模型的视频数据量已达到 2000 万 clips,这一数字今年还将增加到 2 亿 clips。
依托强大的 AI 算力基础设施和数据处理机制,小鹏开启了全新的基座模型研发范式,从云端模型预训练到车端模型部署,整个「云端模型工厂」的迭代周期达到平均 5 天一次。
三大阶段性成果
在率先量产端到端大模型的同时,小鹏在物理世界大模型研发上也再进一步,其分享了基础大模型研发的三个阶段性成果:
验证了 Scaling Laws 在自动驾驶领域持续生效:

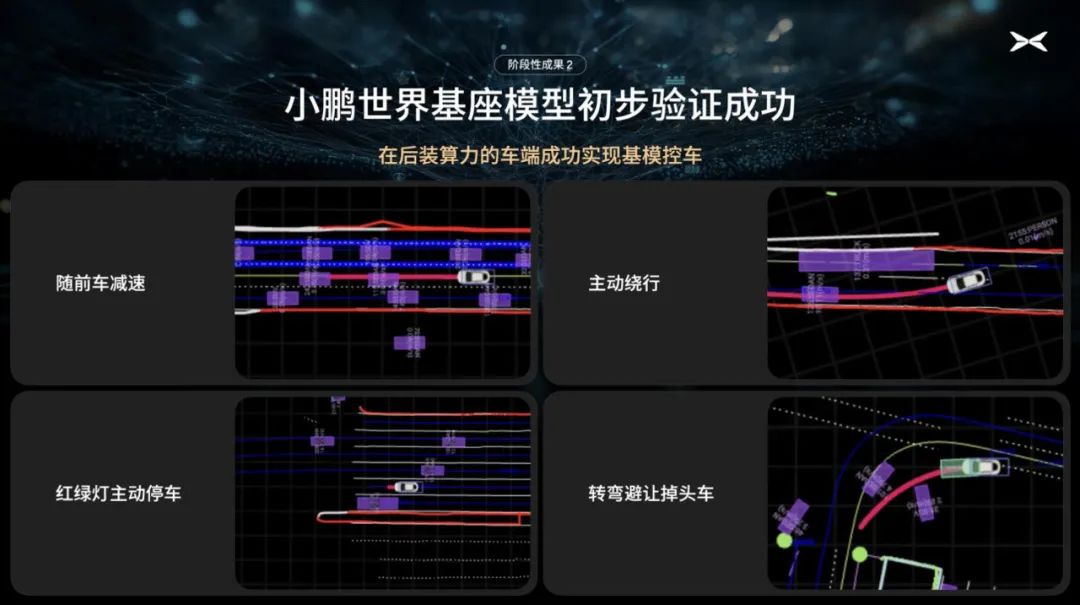
在后装算力的车端上成功实现基模控车:
启动 72B 参数模型训练,搭建针对强化学习的模型训练框架:

规模法则(Scaling Law)揭示了大模型的性能随着模型的计算量、训练数据量和参数量的提升而提升,在大语言模型(LLM)领域一直是人们追逐的目标。而在自动驾驶领域上,训练数据远不止单模态的文本数据,还包括摄像头、激光雷达等关于物理世界的多模态数据,本质上,这要求模型对物理世界形成认知和理解。
小鹏团队首次验证了 Scaling Laws 在自动驾驶领域持续生效,刘博士表示:「过去一年,我们做了大量实验,在 10 亿、30 亿、70 亿、720 亿参数的模型上都看到了明显的规模法则效应:参数规模越大,模型的能力越强。同样的模型大小,训练数据量越大,模型的能力也会越强。」
不久前,小鹏实践了理论,在后装算力的车端上用小尺寸模型实现了控车。尽管只是非常早期的实车测试,全新基模已经展现出令人惊讶的智驾能力。例如模型在未训练的情况下就能适应香港的右舵驾驶环境。
在 AI 技术上,小鹏也一直在探索最新方向,自去年就已开始研发大模型中的强化学习技术。强化学习能够帮助模型自我进化,学会处理训练数据中未出现的长尾问题,做到更安全的自动驾驶。只有足够强大的基座模型,才能被强化学习不断激发出能力上限。这也是小鹏汽车选择云端蒸馏路线的原因之一:在云端不计成本地训练出高智能、泛化能力强的模型,再将其蒸馏到适配车端算力的小模型上,才可以让车端模型的性能超越算力限制。
值得一提的是,强化学习、云端蒸馏等技术的思路,在今年初爆火的 DeepSeek R1 中得到了验证,目前正在逐渐成为行业共识。
基础模型是小鹏汽车 AI 化转型的重要一步,不过在智能驾驶的大模型时代,过去规则时代的经验仍能发挥作用。在开发强化学习的奖励模型(Reward Model)时,小鹏研发团队基于规则经验设计了奖励函数,将规则时代的沉淀转化为了新的生产力。

小鹏也在推动世界模型(World Model)的研发,小鹏的世界模型是一种实时建模和反馈系统,能够基于动作信号模拟出真实环境状态,渲染场景,并生成场景内其他智能体(即交通参与者)的响应,从而构建一个闭环的反馈网络,可以帮助基座模型不断进化,逐渐突破过去「模仿学习」的天花板。
这也意味着人们能够以更有效的方式构建新模型,产生新能力。小鹏工程师表示,我们或许可以像黄仁勋展望的那样,用 AI 模型来生成一个新模型。
据介绍,小鹏世界基座模型研发和训练成果更多的细节,预计还会再今年 6 月的全球 AI 顶会 CVPR 上进行分享。
昨天,小鹏又宣布开启自研 AI 芯片计划,预计将在 2025 年底在中国内地率先实现 L3 级智能驾驶落地。

未来,小鹏还希望通过云端蒸馏小模型的方式将基模部署到车端,给「AI 汽车」配备全新的大脑。这款模型的能力同时也将拓展至小鹏的 AI 机器人、飞行汽车等。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com