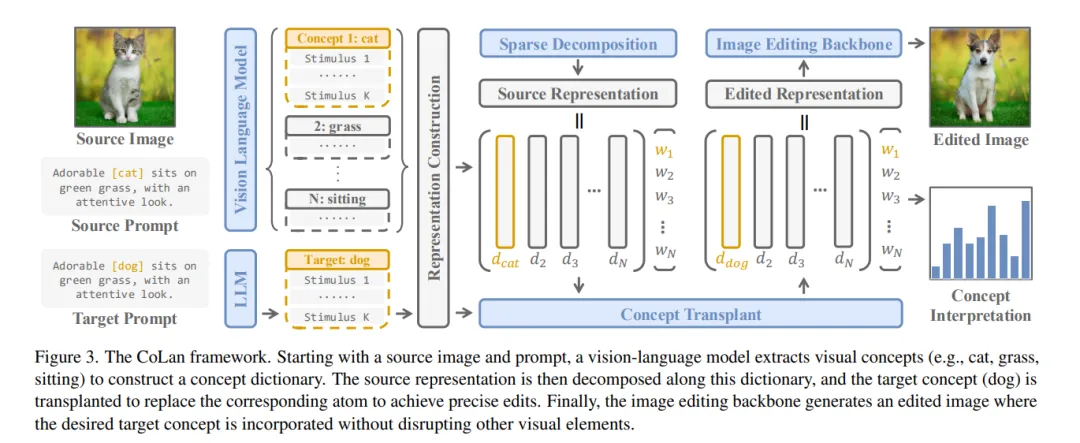
CoLan提出一种零样本图像编辑框架,通过概念移植实现精准编辑,有效解决编辑强度控制难题,在编辑有效性和一致性上均达最优。
原文标题:【CVPR2025】基于组合表示移植的图像编辑方法
原文作者:数据派THU
冷月清谈:
本文介绍了一种名为Concept Lancet(CoLan)的全新零样本、即插即用的扩散式图像编辑框架。该框架旨在解决现有图像编辑方法中编辑强度难以控制的问题,通过将源图像分解为预先收集的视觉概念表示的稀疏线性组合,从而准确估计图像中概念的存在程度,并指导编辑方向。CoLan通过定制化的概念移植过程,实现对图像的精确编辑,同时保持图像一致性。实验结果表明,使用CoLan进行增强的方法在编辑有效性与图像一致性保留方面均达到了当前最优性能。该研究还构建了一个包含丰富视觉术语与短语描述的CoLan-150K概念表示数据集,以支持潜在表示字典的构建。
怜星夜思:
1、CoLan框架中“概念移植”的具体实现方式是怎样的?除了替换、添加或移除概念,未来是否有可能实现更复杂的概念操作,例如概念融合或变形?
2、CoLan-150K概念表示数据集在CoLan框架中扮演什么角色?这个数据集的质量和多样性对最终图像编辑效果有多大影响?
3、CoLan框架宣称是“零样本”的,这意味着什么?它与需要大量训练数据的图像编辑方法相比,有什么优势和劣势?
2、CoLan-150K概念表示数据集在CoLan框架中扮演什么角色?这个数据集的质量和多样性对最终图像编辑效果有多大影响?
3、CoLan框架宣称是“零样本”的,这意味着什么?它与需要大量训练数据的图像编辑方法相比,有什么优势和劣势?
原文内容

来源:专知本文约1000字,建议阅读5分钟
实验结果表明,使用 CoLan 进行增强的方法在编辑有效性与图像一致性保留方面均达到了当前最优性能。

扩散模型(Diffusion Models)被广泛应用于图像编辑任务中。现有的编辑方法通常通过在文本嵌入空间或得分(score)空间中构建某种编辑方向,来设计特征操作流程。然而,这类方法面临一个关键挑战:编辑强度设置不当会影响最终效果——过强会破坏图像的一致性,过弱则无法实现预期编辑。此外,每张源图像可能需要不同的编辑强度,而通过反复试验寻找合适强度代价高昂。
为解决这一问题,我们提出了 Concept Lancet(CoLan),一个零样本、即插即用的扩散式图像编辑框架,能够以原理性方式对表示空间进行操作。在推理阶段,我们将源图像在潜在空间(包括文本嵌入或扩散得分空间)中分解为一组稀疏线性组合,这些组合来自预先收集的视觉概念表示。这一分解机制使我们能够准确估计图像中概念的存在程度,从而指导编辑方向。
根据具体的编辑任务(如替换、添加或移除某一概念),我们执行一个定制化的概念移植(concept transplant)过程,以施加相应的编辑操作。为了更充分地建模概念空间,我们构建了一个概念表示数据集 CoLan-150K,其中包含丰富的视觉术语与短语的描述与场景信息,用于支持潜在表示字典的构建。
在多个基于扩散模型的图像编辑任务中,实验结果表明,使用 CoLan 进行增强的方法在编辑有效性与图像一致性保留方面均达到了当前最优性能。
更多项目信息请见:https://peterljq.github.io/project/colan