国产开源 HiDream-I1 模型效果媲美 GPT-4o,支持商用。采用 Sparse DiT 架构,提升图像质量,即将开源 HiDream-E1。
原文标题:「开源版GPT-4o」来了!这个17B国产模型生图效果比肩4o,还可商用
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 HiDream-I1 采用了 Sparse Diffusion Transformer 架构,这个架构具体有什么优势?除了文中提到的提高模型性能和控制运算开销,还有其他潜在的优点吗?
3、HiDream-I1 已经表现出接近 GPT-4o 的能力,那么在哪些方面,你认为开源模型还有进一步提升的空间?
原文内容
作者:张倩
前段时间,GPT-4o 火出了圈,其断崖式提升的生图、改图能力让每个人都想尝试一下。虽然 OpenAI 后来宣布免费用户也可以用,但出图慢、次数受限仍然困扰着没有订阅 ChatGPT 的普通人。
那除了 GPT-4o,我们还有没有其他选择呢?去 Artificial Analysis 的文生图大模型竞技场找一下就知道了。
在这个竞技场上,我们发现前段时间排到第二名的模型 —— 拥有 17B 参数的 HiDream-I1 和 GPT-4o 得分很接近。
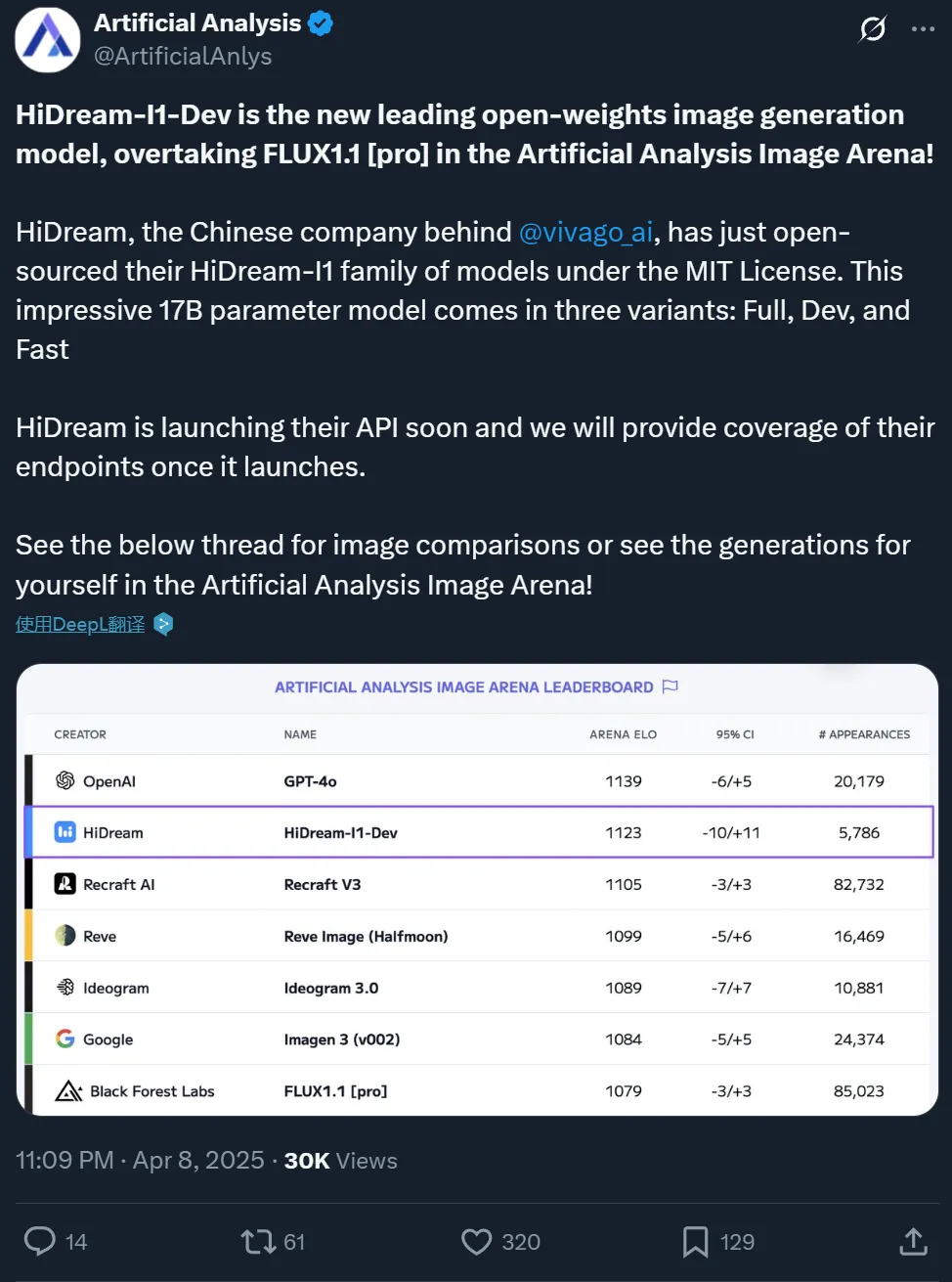
AI 基准测试和分析平台 Artificial Analysis 发推宣布 HiDream-I1 成为文生图开源模型新 SOTA。这个平台采用竞技场模式来评估模型,即同时给两张不同模型生成的图像,让人类从中选出和 prompt 最贴合的。
值得一提的是,这个模型在上线的 24 小时之内就登顶了 Artificial Analysis 竞技场榜首,也是首个登顶该榜单的中国自研生成式 AI 模型。
通过一些对比图可以看到,HiDream-I1 的生成效果似乎不输 GPT-4o,比之前「把 Midjourney 打下神坛」的 FLUX1.1 [pro] 效果还要好。重点是,这三个模型里,只有 HiDream-I1 是开源的,而且是允许商用的那种开源(MIT 协议)。

-
HiDream-I1 模型:https://huggingface.co/HiDream-ai/HiDream-I1-Full
-
HiDream-I1 代码:https://github.com/HiDream-ai/HiDream-I1
而且,开源这个模型的国内公司 —— 智象未来刚刚宣布,他们即将开源的另一个模型 ——HiDream-E1 还支持交互式图像编辑,可以像 GPT-4o 那样把你提供的图修改为任意风格、任意内容。二者合在一起,实现了类似于 GPT-4o 图像生成和编辑的「言出法随」效果,填补了「开源版 GPT-4o」的空白。

HiDream-E1 的图像编辑效果,模型将于近期开源。
那么,HiDream-I1 的效果究竟好在哪儿?我们可以多看一些案例详细分析。
HiDream-I1 生图效果如何?
GPT-4o、FLux 之所以能够走红,其生成画面的真实感、细腻度和遵循指令的能力起到了重要作用。
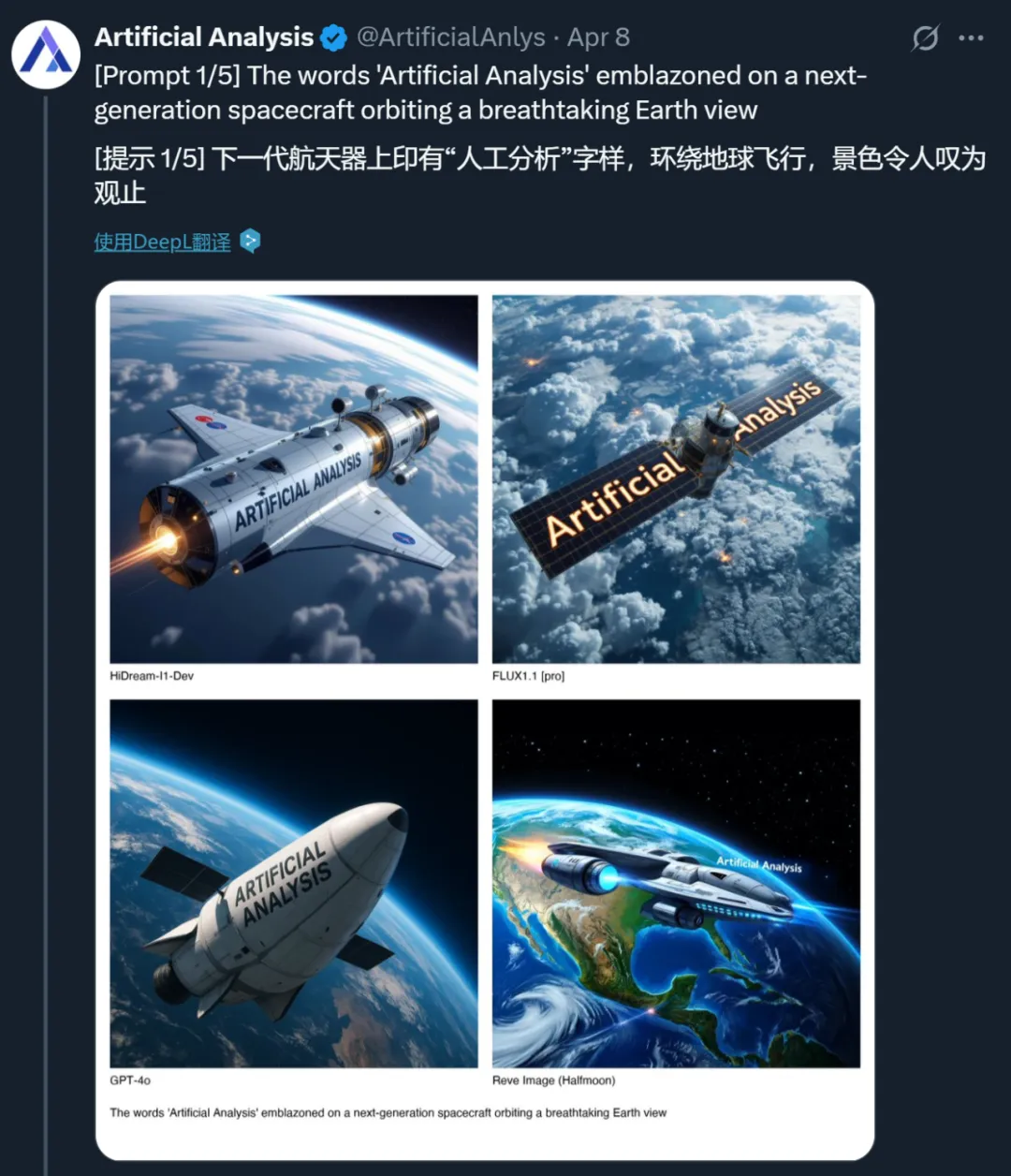
为了测试 HiDream-I1 能不能担得起「开源版 GPT-4o」这个称号,我们参考前段时间 OpenAI 官宣 GPT-4o 新能力时发布的一些 prompt 测试了一下。

GPT-4o 博客中给到的生成案例与 prompt。
HiDream-I1 生成的结果如下:

提示词:写实的照片,一匹马从右到左奔驰在一个巨大的,平静的海面上,准确地描绘了溅起的水花,反射,和马蹄下微妙的涟漪图案。夸张马的动作,但其他一切都应该是静止的,安静的,以显示与马的力量形成对比。干净的构图,电影般的。广阔的全景构图,展示远处的地平线。大气透视创造深度。放大后的马与浩瀚的海洋相比显得微不足道。

提示词:真实水果与微型行星(木星、土星、火星、地球)混合而成的果盘照片,保持真实的反射、光照、阴影与原图一致,构图干净,纹理真实,细节渲染清晰

提示词:一个真实的水下场景,海豚从一辆废弃的地铁车厢的窗户游进来,气泡和水流的细节被精确地模拟出来。

提示词:这是一张狗仔队风格的偷拍照片,卡尔・马克思匆忙穿过美国购物中心的停车场,他带着惊讶的表情瞥了一眼,试图避免被拍到。他手里拿着几个锃亮的购物袋,里面装满了奢侈品。他的外套在风中飘动,其中一个包在摇摆,好像他正在大步前进。模糊的背景与汽车和发光的商场入口,以强调运动。相机发出的闪光部分过度曝光了图像,给人一种混乱的小报感。
整体上看,HiDream-I1 生成的图在真实感、细腻度上和 GPT-4o 是非常接近的,有时还能更胜一筹。在和 Flux 相比时,这个特点更加明显。
比如在下面这个例子中,HiDream-I1 生成的图像具有更多精细的元素,包括纹理、背景细节以及物体之间的层次感(猫毛在光的照耀下根根分明,给人一种强烈的生机感;咖啡壶的不锈钢材质恰到好处地反射光线,呈现出真实的质感)。相比之下,Flux 虽然也能生成具有良好细节的图像,但在细节材质上不如 HiDream-I1 细腻丰富。

提示词:一只可爱的橙色猫咪坐在咖啡研磨机旁,用爪子慢吞吞地转动着研磨机的把手。猫咪专注的表情和温柔的咕噜声在舒适宁静的厨房里被捕捉到。柔和、温暖的光线透过窗户,在猫和磨床上投射出柔和的光芒,增强了宁静的氛围。这一场景以写实的风格呈现,强调平静和亲密。
在色彩的呈现上,HiDream-I1 的表现也更出色,能够生成层次分明、色调多样的图像(仔细看下图中狼的脸部毛发,HiDream-I1、GPT-4o 的颜色层次都更丰富)。Flux 的色彩使用虽然也相当丰富,但在某些场景下,色彩的搭配和过渡显得较为单一,缺乏一定的饱和度和层次感。

提示词:一只穿着音乐家燕尾服的 3D 狼。像人一样两条腿直立站着,拿着吉他,周围是放大器和舞台,这里散发着艺术和优雅的气息。
此外,这种真实感、细腻感还来自模型对客观规律的理解。从下图可以看出,HiDream-I1 对客观规律的理解较为精确。无论是物体的摆放、人物的动作姿势,还是环境中的光影效果,HiDream-I1 都能展现出符合现实世界的自然规律。而 Flux 则在这方面存在一定局限,特别是在处理动态场景和复杂物理互动时,模型的表现不够真实,常常出现不符合物理定律的情况。

提示词:一只穿着音乐家燕尾服的 3D 猫,两条腿直立,拿着小提琴,周围是旋转的音符和大钢琴,散发着艺术和优雅的氛围,聚光灯照亮了现场,创造了一个戏剧性和精致的环境。
即使是遇到复杂的提示词,这些特点依然能够在 HiDream-I1 生成的图中得到保留。这是模型复杂文本理解、遵循能力的体现。

HiDream-I1 生成的图像。提示词:中世纪城堡的石砌城墙,身披铠甲的战士面向镜头,跃动的火焰在他身后勾勒出粗犷的面部轮廓。火星随风溅落在生锈的锁子甲上,右手不自觉地握紧腰间剑柄,深褐色的斗篷在热浪中剧烈翻卷。燃烧的箭矢在远处塔楼持续坠落,橙红火光与靛蓝夜空形成强烈对比,照亮了城墙垛口剥落的青苔和战士眉骨处的陈旧伤疤。
在各项基准测试数据中,以上视觉效果得到了印证:
-
首先是 HPSv2.1,这是一个基于人类偏好选择数据集训练的偏好预测模型,能够对同一提示下产生的不同图像进行评分比较。在这个基准上,HiDream-I1 在多种风格(如动漫、概念艺术、绘画和真实摄影)上达到最优。这说明,HiDream-I1 生成的各种风格图像都更符合人类审美。
-
其次是 GenEval 和 DPG-Bench,前者通过检测对象和颜色分类来验证生成图像与文本提示之间的匹配程度,后者专注于检测生成图像中的多个对象、详细属性和复杂关系(当提示又长又复杂的时候适合用这个基准评测)。在这两个基准上,HiDream-I1 都达到了最优。这说明,HiDream-I1 的指令遵循能力很强。
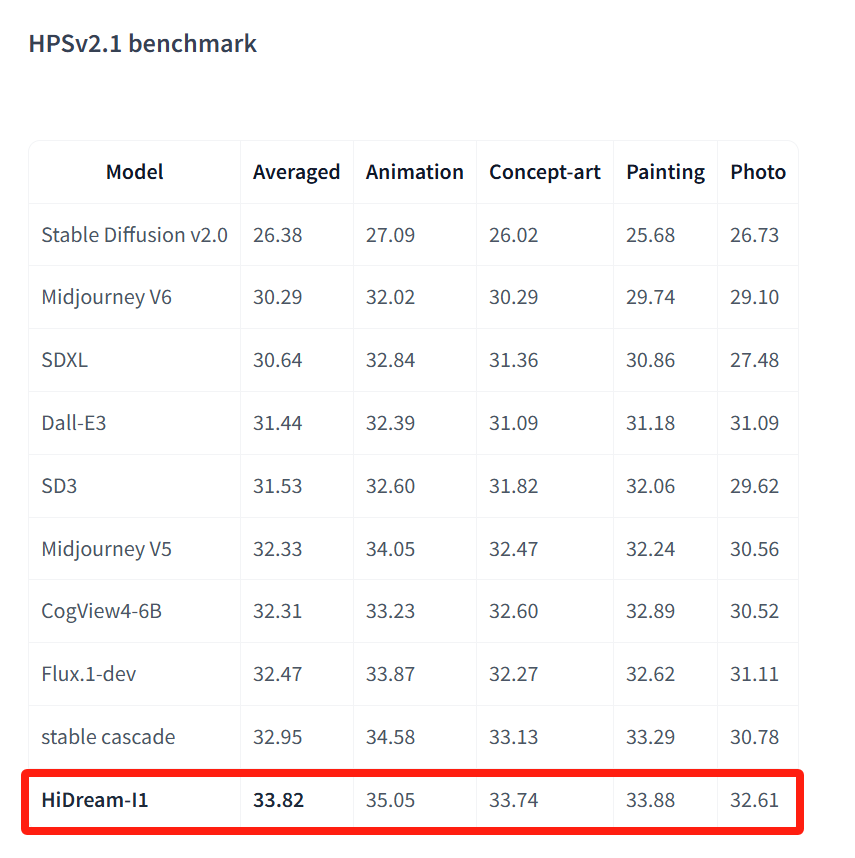
HiDream-I1 在 HPSv2.1 上的得分数据。
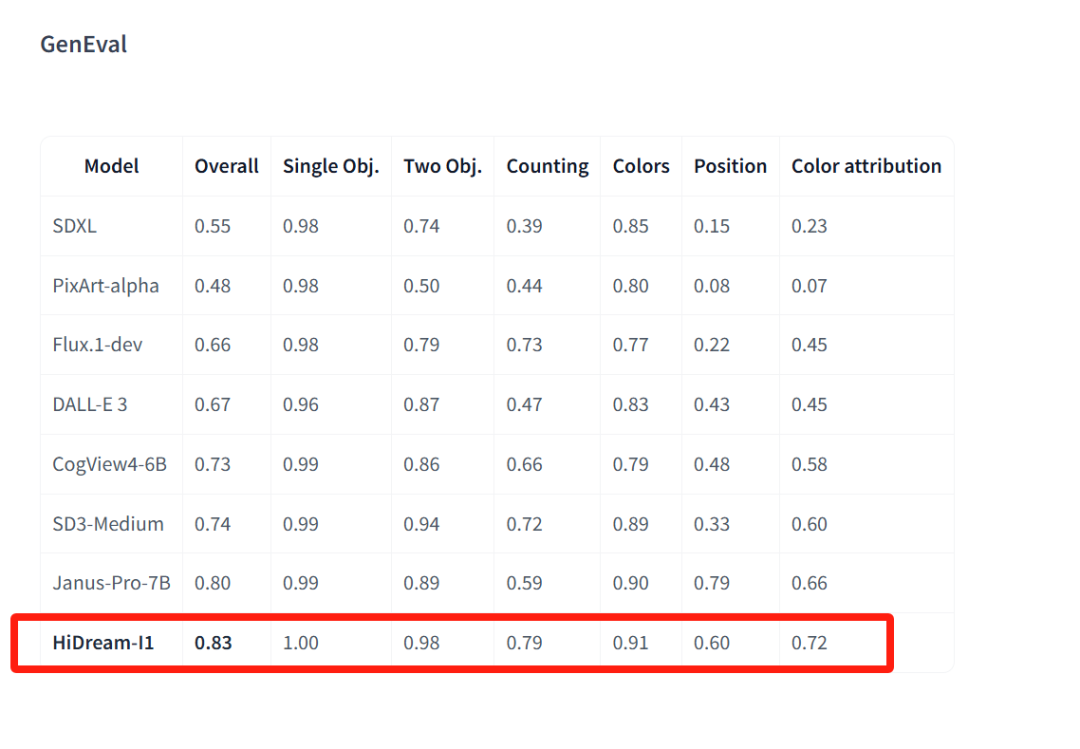
HiDream-I1 在 GenEval 上的得分数据。
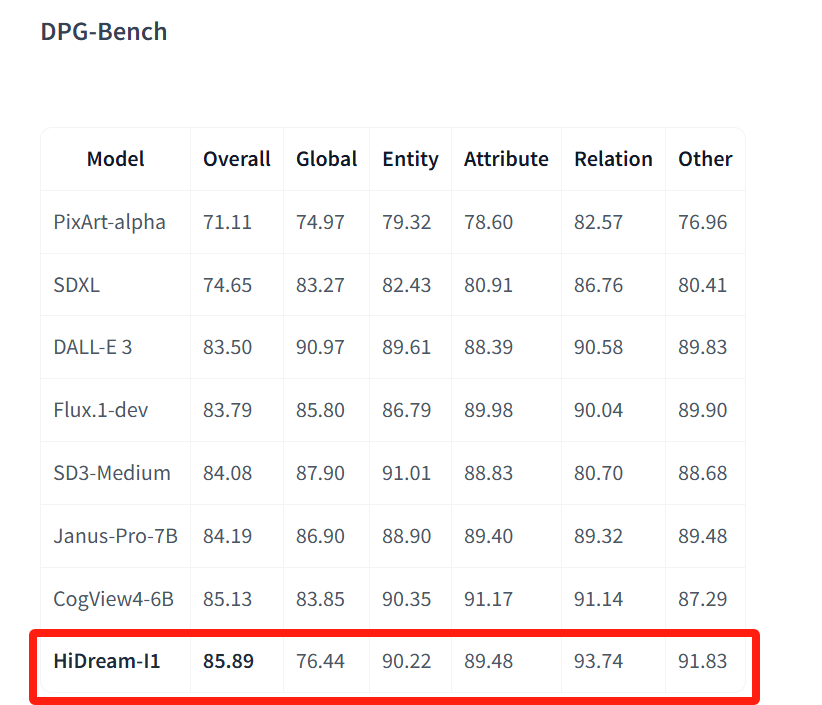
HiDream-I1 在 DPG-Bench 上的得分数据。
为了提升生图效果
智象未来做了哪些技术改进?
强大的指令遵循能力和逼真、细腻的生成效果本质上都要归功于技术改进。
为了提高模型理解文本的能力,HiDream-I1 采用了新的被称为「Sparse Diffusion Transformer(Sparse DiT)」的架构设计。这个架构在 DiT 框架下融合了 Sparse Mixture-of-Expert (MoE)技术,让不同的专家模型处理不同类型的文本输入,各有专精。
同时,这个架构设计还带来了一个额外的好处 —— 在提高模型性能的同时控制运算开销,使得 HiDream-I1 用起来性价比很高。对于关注开源模型算力消耗的个人开发者、创业公司来说,这是一个很有用的优化。
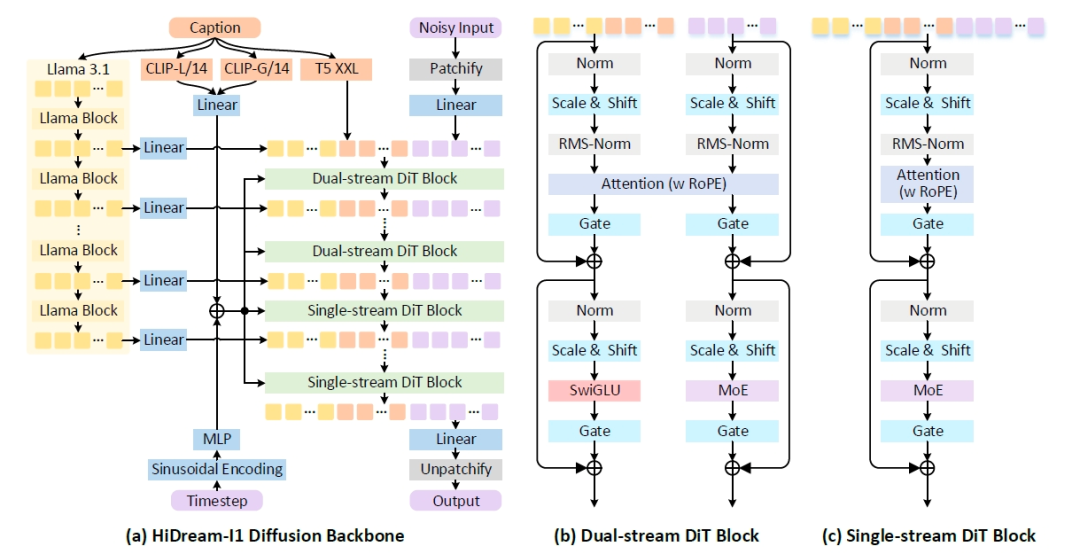
HiDream-I1 模型架构图。
图像质量的提升则要归功于研究者在扩散模型蒸馏中融入生成对抗学习,借助 GAN 捕捉细节、锐化边缘的能力,在蒸馏扩散模型的同时进一步提升了生成图像的真实感和清晰度,实现速度与质量的双重优化。
值得一提的是,这样训练出来的 HiDream-I1 具有很强的可扩展性。所以在模型训练出来后不久,智象未来就将其扩展到了交互式图像编辑大模型 HiDream-E1,让图像编辑场景也有了「开源版 GPT-4o」可用。
HiDream 系列模型开源
影响力已初步彰显
无论从实测效果还是基准测试结果来看,智象未来的 HiDream-I1 都已经非常接近 GPT-4o,站稳了国内图像生成第一梯队。

而且,由于模型是开源的,其国际影响力也在逐步显现。在开源后两天,文生图大模型竞技场上的另一家模型公司 ——Recraft AI 就宣布,他们已经集成了 HiDream-I1,还手把手教网友怎么选用这个模型。

在 HuggingFace Trending 榜单上,HiDream-I1 飙升到了第二名。这说明 HiDream-I1 的下载量、点赞数都很可观,在社区中非常受欢迎。
当然,没有本地部署需求的朋友也可以在智象未来的官方平台 Vivago 上体验 HiDream-I1。该平台上有更完整的工作流,支持在生成图像的基础上进行视频制作等二次创作。
Vivago 上的图像转视频效果。
据悉,过段时间,智象未来还将发布多模态 Agent 产品。它的核心是让大家用对话聊天的形式来生成图片 / 视频,并使用自然语言对图片 / 视频内容进行相应的编辑,从而渐进式地生成有故事情节的内容。便利之处在于不需要用户自己去跨平台选择调用需要的功能以及调节复杂的参数。
对于这样的模型改进、产品开发理念,智象未来 CTO 姚霆曾做出过解释 —— 在应用端,真实感、指令遵循和叙事性的能力是用户愿意为之付费的基础,所以智象未来在改进模型的过程中始终关注这三大属性。如今,他们把这三点做到了新的高度,还开源了模型,可以说为想在这一领域开发应用的开发者或公司扫除了基础障碍。
智象的研发人员透露,下一个开源模型--HiDream-E1 即将开源,相关基准测试数据也将在近日发布。期待这个模型带来优秀的编辑体验。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]