上海AI Lab开源AccVideo,利用合成数据加速视频生成,效率提升8.5倍!显著降低训练成本,高质量视频触手可及。
原文标题:合成数据助力视频生成提速8.5倍,上海AI Lab开源AccVideo
原文作者:机器之心
冷月清谈:
怜星夜思:
2、AccVideo 使用对抗训练策略,避免了无效数据点的蒸馏。那么,在实际应用中,如何判断哪些数据点是“无效”的?
3、AccVideo 依赖于高质量的教师模型 HunyuanVideo。如果教师模型本身存在缺陷,例如容易生成不一致的画面,是否会影响 AccVideo 的性能?
原文内容

虽然扩散模型在视频生成领域展现出了卓越的性能,但是视频扩散模型通常需要大量的推理步骤对高斯噪声进行去噪才能生成一个视频。这个过程既耗时又耗计算资源。例如,HunyuanVideo [1] 需要 3234 秒才能在单张 A100 上生成 5 秒、720×1280、24fps 的视频。
为了解决上述问题,上海AI Lab提出了一种创新性的高效蒸馏方法 AccVideo,旨在利用合成数据集加速视频扩散模型。AccVideo 相比于教师模型(HunyuanVideo)[1] 提升了 8.5 倍的生成速度并保持相当的性能。此外,通过使用合成数据集,AccVideo 显著提升训练效率并减少数据需求。仅需 8 块 A100 显卡,使用 3.84 万条合成数据训练 12 天,即可生成高质量 5s、720×1280、24fps 的视频。

-
开源链接:https://github.com/aejion/AccVideo
-
项目主页:https://aejion.github.io/accvideo
-
论文链接:https://arxiv.org/abs/2503.19462
该模型受到包括 Reddit 等在内的社区广泛关注,目前已经集成 ComfyUI,并且支持 Lora。

-
Reddit 讨论链接:https://www.reddit.com/r/StableDiffusion/comments/1jnb5rt/accvideo_85x_faster_than_hunyuan/
研究动机
作者首先在 1D toy 实验上对现有蒸馏扩散模型的方法进行了细致的分析。如图 1 所示,现有的方法在通常需要前向扩散来计算蒸馏数据点,但是由于数据集不匹配(教师模型和学生模型训练时使用的数据集不匹配)或者高斯噪声不匹配(高斯噪声和真实数据的不匹配)的问题,计算出来的数据点可能是无用的。这会导致教师模型为学生模型提供不可靠的指导(如图 1 红框所示),从而影响模型的蒸馏效率以及生成结果。

图 1. 1D toy 实验图,展示了现有蒸馏方法在蒸馏时会使用无用数据点的问题。e) 无用数据点的频率会随着数据集不匹配的程度大幅增长
方法概述
本文方法旨在通过蒸馏预训练视频扩散模型(HunyuanVideo)来减少推理步数,从而加速视频生成。基于上面的分析,作者尝试在蒸馏过程中避免了无效数据点的使用。具体而言,作者首先构建了一个合成视频数据集 SynVid,该数据集利用教师模型生成高质量合成视频及其去噪轨迹。随后,作者提出了一种基于轨迹的少步指导机制和一种对抗训练策略,从而以更少推理步数生成视频并充分利用 SynVid 所捕获的每个扩散时间步的数据分布特性,进一步提升模型性能。图 2 展示了本方法的总览图。

图 2. AccVideo 方法总览图
(1)合成视频数据集,SynVid
作者采用 HunyuanVideo 作为生成器来构建合成数据,如图 3 所示。作者构建的合成数据集![]() 包含高质量的合成视频
包含高质量的合成视频![]() 、潜在空间中的去噪轨迹
、潜在空间中的去噪轨迹![]() 以及它们对应的文本提示
以及它们对应的文本提示![]() ,其中
,其中![]() 表示数据数量,n=50表示推理步数,
表示数据数量,n=50表示推理步数,![]() 表示推理扩散时间步。文本提示
表示推理扩散时间步。文本提示![]() 通过使用 InternVL2.5 标注互联网上的高质量视频获得。对于高斯噪声
通过使用 InternVL2.5 标注互联网上的高质量视频获得。对于高斯噪声![]() ,去噪轨迹可以通过以下方式求解:
,去噪轨迹可以通过以下方式求解:

合成视频![]() 可以通过 VAE 解码干净的潜在编码
可以通过 VAE 解码干净的潜在编码![]() 得到。值得注意的是,
得到。值得注意的是,![]() 中的数据点是通向正确视频的中间结果,因此它们都是有效且有意义的。这有助于高效蒸馏并显著减少对数据量的需求。
中的数据点是通向正确视频的中间结果,因此它们都是有效且有意义的。这有助于高效蒸馏并显著减少对数据量的需求。

图 3. 合成视频数据集 SynVid 构建图
(2)基于轨迹的少步指导机制
视频扩散模型通常需要大量的推理步骤来生成视频。为了加速生成过程,作者设计了一个学生模型![]() ,该学生模型从预训练视频扩散模型(即教师模型)生成的去噪轨迹中学习,能以更少的推理步数生成视频。具体而言,作者提出了一种基于轨迹的损失函数,以 m 步学习教师模型的去噪过程。该损失选择m+1个关键扩散时间步
,该学生模型从预训练视频扩散模型(即教师模型)生成的去噪轨迹中学习,能以更少的推理步数生成视频。具体而言,作者提出了一种基于轨迹的损失函数,以 m 步学习教师模型的去噪过程。该损失选择m+1个关键扩散时间步 ,并在每条去噪轨迹上获取它们对应的潜在编码
,并在每条去噪轨迹上获取它们对应的潜在编码 ,并通过这些关键潜在编码学习高斯噪声到视频的映射关系:
,并通过这些关键潜在编码学习高斯噪声到视频的映射关系:

其中![]() 。这些关键潜在编码构建了一条从高斯噪声到视频潜在编码的更短路径,通过学习这个更短路径,学生模型显著减少了推理步数。在实验中,作者m=5设置,与教师模型相比,推理步骤数量减少了 10 倍,从而大大加速了视频生成过程。
。这些关键潜在编码构建了一条从高斯噪声到视频潜在编码的更短路径,通过学习这个更短路径,学生模型显著减少了推理步数。在实验中,作者m=5设置,与教师模型相比,推理步骤数量减少了 10 倍,从而大大加速了视频生成过程。
(3)对抗训练策略
除了高斯噪声与视频潜在编码之间的一对一映射外,SynVid 还包含每个扩散时间步![]() 的许多潜在编码
的许多潜在编码 ,这些潜在编码隐式地代表了在这个扩散时间步下的数据分布
,这些潜在编码隐式地代表了在这个扩散时间步下的数据分布![]() 。为了充分释放合成数据集中的知识并提升学生模型
。为了充分释放合成数据集中的知识并提升学生模型![]() 的性能,作者提出了一种对抗训练策略,以最小化对抗散度
的性能,作者提出了一种对抗训练策略,以最小化对抗散度 ,其中
,其中 表示学生模型
表示学生模型![]() 在扩散时间步
在扩散时间步![]() 生成的数据分布。训练目标遵循标准的生成对抗网络:
生成的数据分布。训练目标遵循标准的生成对抗网络:
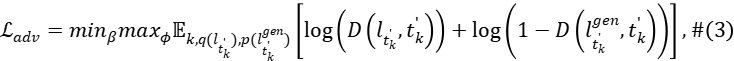
其中D表示判别器。由于判别器需要区分不同扩散时间步的噪声潜在编码,作者设计的判别器D包含一个噪声感知的特征提取器和m个扩散时间步感知的投影头![]()
需要注意的是,该对抗训练策略避免了现有方法中常用的前向扩散操作,从而防止了对无用数据点进行蒸馏。这确保了教师模型能够为学生模型提供准确的指导。此外,基于轨迹的少步指导机制提升了对抗学习的稳定性,无需复杂的正则化设计。
实验结果
视频展示了 AccVideo 在不同分辨率下和 VideoCrafter2 [2]、T2V-Turbo-V2 [3]、LTX-Video [4]、CogVideoX [5]、PyramidFlow [6] 以及 HunyuanVideo [1] 的定性对比结果。AccVideo 生成的视频伪影更少(例如小女孩的手部细节)。相比 CogVideoX1.5,本方法生成的视频具有更高保真度的画面和更优质的背景效果。与 HunyuanVideo 相比,本方法的结果能更好地匹配文本描述(例如复古 SUV 的呈现效果)。
总结
在本文中,作者首先系统分析了现有扩散蒸馏方法因使用无效数据点而导致的关键问题。基于这一发现,作者提出了一种高效蒸馏新方法以加速视频扩散模型。具体而言:1)构建了包含有效蒸馏数据点的合成视频数据集 SynVid;2)提出基于轨迹的少步指导机制,使学生模型仅需 5 步即可生成视频,较教师模型实现显著加速;3)设计了利用合成数据集分布特性的对抗训练策略以提升视频质量。实验表明,AccVideo 在保持性能相当的前提下,生成速度较教师模型提升 8.5 倍。
参考文献
[1] Kong, Weijie, et al. "Hunyuanvideo: A systematic framework for large video generative models." arXiv preprint arXiv:2412.03603 (2024).
[2] Chen, Haoxin, et al. "Videocrafter2: Overcoming data limitations for high-quality video diffusion models." CVPR. 2024.
[3] Li, Jiachen, et al. "T2v-turbo-v2: Enhancing video generation model post-training through data, reward, and conditional guidance design." ICLR. 2025.
[4] HaCohen, Yoav, et al. "Ltx-video: Realtime video latent diffusion." arXiv preprint arXiv:2501.00103 (2024).
[5] Yang, Zhuoyi, et al. "Cogvideox: Text-to-video diffusion models with an expert transformer." ICLR. 2025.
[6] Jin, Yang, et al. "Pyramidal flow matching for efficient video generative modeling." ICLR. 2025.

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com