新加坡国立大学提出DexSinGrasp,一种基于强化学习的统一策略,提升灵巧手在杂乱环境中分离和抓取物体的效率与成功率。
原文标题:面对杂乱场景,灵巧手也能从容应对!NUS邵林团队发布DexSinGrasp基于强化学习实现物体分离与抓取统一策略
原文作者:机器之心
冷月清谈:
怜星夜思:
2、在物流,生产或者日常场景中,如果目标物体被完全遮挡,该方案如何改进才能实现抓取?
3、文中的“杂乱环境课程学习”机制,从简单到复杂的训练方式,对提升策略的泛化性能起到了关键作用。那么,在实际应用中,如何设计更有效的课程,以适应不同场景和任务的需求?
原文内容

本文的作者均来自新加坡国立大学 LinS Lab。本文的共同第一作者为新加坡国立大学实习生许立昕和博士生刘子轩,主要研究方向为机器人学习和灵巧操纵,其余作者分别为硕士生桂哲玮、实习生郭京翔、江泽宇以及博士生徐志轩、高崇凯。本文的通讯作者为新加坡国立大学助理教授邵林。
在物流仓库、生产线或家庭场景中,机器人常常需要在大量杂乱摆放的物体中高效地抓取目标。
在这些场景中,如果使用机械夹爪,由于其自由度有限、灵活性不足,需要多次对场景进行操作;而高自由度的灵巧手虽然具有潜在优势,但因控制复杂和训练难度大,在密集遮挡与复杂排列场景下往往表现不佳。
现有方法常采用先分离、后抓取的策略,存在策略切换不够灵活,执行效率低下的问题。
为解决这一挑战,来自新加坡国立大学的邵林团队提出了 DexSinGrasp——一种基于强化学习的统一策略,通过整合物体分离与抓取任务,令灵巧手在杂乱环境中能够自适应调整分离与抓取策略,显著提高抓取成功率和操作效率。该项研究已投稿至 IROS 2025。

-
论文标题:DexSinGrasp: Learning a Unified Policy for Dexterous Object Singulation and Grasping in Cluttered Environments
-
论文链接:https://arxiv.org/abs/2504.04516
-
项目主页:https://nus-lins-lab.github.io/dexsingweb/
-
代码链接:https://github.com/davidlxu/DexSinGrasp
为了让机器人在多变的杂乱环境中高效分离物体并抓取目标,DexSinGrasp 提出了「统一策略」的设计。该方法通过强化学习构建了一体化的策略框架,实现了「分离—抓取」动作的无缝衔接。该项研究的主要贡献有:
-
统一强化学习策略:提出一种统一的强化学习策略,实现灵巧手在杂乱环境中对物体的有效分离和抓取。
-
课程学习与策略蒸馏:融入杂乱环境课程学习以提升不同场景下的策略性能,并通过策略蒸馏获得适用于实际部署的视觉抓取策略。
-
多难度抓取任务设计:设计一系列不同难度与排列的杂乱抓取任务,通过大量实验验证所提方法的高效性与有效性。

方法
统一强化学习策略
DexSinGrasp 的核心在于构建一个统一的策略框架,引入分离奖励项,将「分离障碍」、「抓取目标」整合为一个连续的动作决策过程,充分利用了分离与抓取融合的优势,避免传统多阶段方法中各模块间效率低下和动作衔接不畅的问题。为此,我们设计了一个分段式奖励函数,其关键组成包括:

-
接近奖励:奖励项
 引导手掌和手指在初始阶段向目标物体靠近,从而确保机器人迅速定位目标。
引导手掌和手指在初始阶段向目标物体靠近,从而确保机器人迅速定位目标。
-
抬升与目标对齐奖励:在目标接触后,奖励项
 鼓励机器人将物体抬升至预设位置,实现准确对齐。
鼓励机器人将物体抬升至预设位置,实现准确对齐。
-
分离奖励:通过奖励项
 ,使机器人在抓取过程中主动推动、滑动或轻推周围障碍物,从而为抓取创造足够空间。
,使机器人在抓取过程中主动推动、滑动或轻推周围障碍物,从而为抓取创造足够空间。
奖励函数依据手掌与手指到目标物体的距离![]() 来自动转换,从「接近」阶段逐步过渡到「抓取」阶段,使整个过程更加平滑和高效。该统一策略不仅提升了训练样本的利用效率,还使机器人能根据实时场景动态选择微调指尖、轻推障碍或直接抓取,从而在杂乱环境下实现稳定的抓取操作。
来自动转换,从「接近」阶段逐步过渡到「抓取」阶段,使整个过程更加平滑和高效。该统一策略不仅提升了训练样本的利用效率,还使机器人能根据实时场景动态选择微调指尖、轻推障碍或直接抓取,从而在杂乱环境下实现稳定的抓取操作。
杂乱环境课程学习
在高度杂乱的场景中直接训练机器人往往容易陷入局部最优,导致成功率低下。为此,我们引入了「杂乱环境课程学习」的机制,具体包括:
-
任务分级设计:从最简单的单目标抓取任务开始,逐步引入障碍物。我们设计了不同难度的任务,例如:
-
密集排列任务:用 D-4、D-6、D-8 表示,不同数字代表环境中障碍物数量的递增;
-
随机排列任务:用 R-4、R-6、R-8 表示,以验证策略在非规则分布场景下的泛化能力。
-
循序渐进训练:先在障碍物较少且排列较规则的环境中训练出初步策略,然后逐步过渡到障碍物数量更多、排列更随机的复杂场景。这样的训练策略能显著提高策略的稳定性和泛化性能,确保机器人在极端密集的环境下也能有效分离并抓取目标。

教师—学生策略蒸馏
在仿真环境中,我们能够利用精确的物体位置、力反馈等特权信息训练出高性能的教师策略。但在真实场景中,这些信息难以获取,为此我们设计了教师—学生策略蒸馏方案:
-
教师策略:利用仿真中丰富的特权信息训练出性能优异的策略,能够精细地控制物体的分离和抓取动作。
-
数据采集与行为克隆:通过教师策略生成大量示范数据(包括视觉观测、点云数据以及动作指令),并采用行为克隆的方法训练出只依赖摄像头采集的点云和机器人自感知数据的学生策略。这样,在真实环境中,机器人无需额外传感器信息也能保持高成功率,完成从仿真到实机的平滑迁移。
实验结果
为了测试 DexSinGrasp 策略在分离抓取时的有效性和泛化性,以及杂乱环境课程学习的有效性,设计了三组实验进行测试,并与两种基线比较。
基线 1 仅训练了一个抓取策略,没有鼓励对周围物体进行分离。基线 2 将分离和抓取策略分开且分阶段进行。
评价指标为抓取成功率(SR)和平均步数(AS)。抓取成功率越高,说明策略的有效性越高,平均步数越少,说明策略的效率越高。
实验 1
对教师策略和学生策略在不同数量障碍的紧密排列进行测试,证明了 DexSinGrasp 的有效性和高效率。图示是教师策略在密集摆放模式下障碍物数量为 4、6、8 时的仿真演示。


实验 2
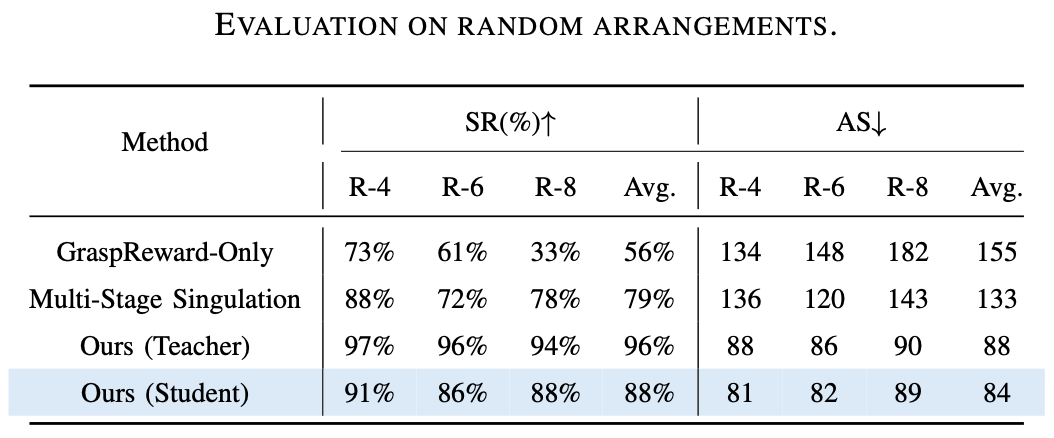
对教师策略和学生策略在不同数量障碍的随机排列进行测试,结果证明了 DexSinGrasp 在随机物体摆放下也可以实现成功分离抓取,对不同的场景有一定泛化性。图示是教师策略在随机摆放模式下障碍物数量为 4、6、8 时的仿真演示。

实验 3
对杂乱环境课程学习的方式进行测试。我们尝试了无课程学习、先随机排列再紧密排列的课程学习,以及先紧密排列再随机排列的课程学习的训练模式。

我们发现,无课程学习训练的各个策略中,随机排列的任务表现不佳;先随机排列再紧密排列的课程学习获得的各个策略中,紧密排列的任务表现不佳;而先紧密排列再随机排列的课程学习在不同的任务上均取得了不错的成功率,证实了所提出的课程学习机制在不同场景下的有效性。
此外,研究团队还在实机平台上进行了验证。使用 uFactory xArm6 搭载 LEAP 手,并配备两台 Realsense RGB-D 摄像头以进行实时点云数据融合与滤波处理。图示为实机实验中对密集与随机摆放的 4、6、8 个物体场景下成功分离与抓取的演示。实验表明,经过教师—学生策略蒸馏后的视觉策略在实际操作中也能有效完成杂乱环境的有效分离与抓取。


总结
研究团队所提出的 DexSinGrasp 是一种基于强化学习的统一框架,通过整合物体分离与抓取任务,实现了灵巧手在杂乱环境中的高效操作。
该方法突破以往直接抓取或多阶段分割的策略,利用推移、滑动等动作在抓取过程中直接调整障碍物布局,结合环境复杂度递进式的杂乱环境课程学习与教师—学生策略蒸馏技术,有效提升视觉策略的泛化能力与仿真到现实的迁移效果。
实验表明,该方法在多种测试场景中展现出优于传统方法的抓取成功率和操作效率。未来研究将拓展至动态复杂场景下的多形态物体操作,增强抗干扰能力,进一步提高系统在非结构化环境中的泛化性与适应性。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com