佐治亚理工学院发布ReC4TS基准,评估推理能力对零样本时间序列预测的影响,发现自我一致性策略效果显著,多模态模型受益更多。
原文标题:时间序列预测是否受益于推理能力?佐治亚理工学院构建首个基准
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、DeepSeek-R1 使用的 Group Relative Policy Optimization (GRPO) 强化学习策略,为什么更符合时序预测中未来的不确定性?它与传统的 PPO 算法有什么本质区别?
3、文章提到多模态时序预测模型比单模态模型更能从推理能力增强中获益,这是为什么?未来多模态时序预测的发展方向是什么?
原文内容

来源:时序人本文约2000字,建议阅读6分钟
本文介绍一篇来自美国佐治亚理工学院的工作,该工作研究者提出了 ReC4TS,这是首个系统地评估流行推理策略在零样本时间序列预测任务中有效性的基准。
随着基础模型的发展,如 LLMs 的出现,已经提出了广泛的推理策略,包括测试时增强策略(如Chain-of-Thought)和 DeepSeek-R1 中使用的训练后优化策略。
本文介绍一篇来自美国佐治亚理工学院的工作,该工作研究者提出了 ReC4TS,这是首个系统地评估流行推理策略在零样本时间序列预测任务中有效性的基准。

【论文标题】
Evaluating System 1 vs. 2 Reasoning Approaches for Zero-Shot Time-Series Forecasting: A Benchmark and Insights
【论文链接】
https://arxiv.org/abs/2503.01895
【论文代码】
https://github.com/AdityaLab/OpenTimeR
问题背景
推理能力对解决复杂问题至关重要,近年来因基础模型(尤其是LLM)的发展而受到广泛关注。然而,其在时间序列预测(TSF)中的有效性尚未被探索,包括:
-
时序预测是否受益于推理能力?
-
时序预测需要何种推理策略?
为此,作者构建了 ReC4TS ,首个用于评估多种主流推理策略在零样本 TSF 任务中有效性的基准,覆盖8个领域的数据集,评估单模态与多模态结合短期与长期预测四个场景。
该研究揭示了三点关键见解:
-
测试时的 自我一致性(self-consistency)可稳定提升时序预测表现;
-
后训练时的相对群体策略优化(Group Relative Policy Incentivizing, 以 DeepSeek-R1 为代表)更契合时序预测需求;
-
多模态时序预测模型比单模态模型更能从推理能力增强中获益。
此外,作者提供了两项关键工具:
-
基于 self-consistency 的测试时 scaling-law ,在多个时序预测基础模型进行了验证;
-
Time-Thinking 数据集:蒸馏自多个先进 LLM 的推理过程标注的TSF样本 。
ReC4TS 基准
ReC4TS (Comparing Resoning Strategies for Time Series Forecasting) 由四个核心模块组成:数据集、推理策略、模型和评估。

01 数据集模块
ReC4TS 的数据集涵盖农业、气候、经济、能源、健康、安全、就业和交通八大领域,提供数值时间序列与对齐的、基于关键词的网络搜索的文本上下文序列,以支持时序预测任务,并确保全面评估推理策略的有效性。
02 推理策略模块
ReC4TS 结合三种推理策略:(1)直接使用生成模型的推理(System 1),(2)在推理时增强的System 1推理(如 Chain of Thought, Self-Consistency, Self-Correction),以及(3)post-training优化的推理(System 2)(如 DeepSeek-R1), 其具备内在的长链推理能力。
03 基础模型模块
ReC4TS 评估了三大系列的基础模型(OpenAI、Google、DeepSeek),涵盖封闭源与开源模型,并提供 对应的 System 1(如 DeepSeek-V3)和 System 2(如 DeepSeek-R1)版本。由于时间序列基础模型的推理策略仍未被探索且难以直接实现,复用基础语言模型是当前的最佳方案。
04 评估模块
ReC4TS 评估了四种零样本时序预测场景(单模态/多模态 × 短期/长期),其中多模态任务结合数值数据与文本上下文。长期预测窗口为六个月,短期预测窗口为三个月,采用 MSE 作为评估指标。为避免数据污染,评估数据限定在 2023 年 10 月 (即 LLMs知识截止日期)之后。
实验结果与见解
为了回答之前提出的问题,作者基于 ReC4TS 架构对比了 System1 模型和 System2 模型时序预测效果。所有实验均在 ReC4TS 提供的数据集模块下进行了三次重复实验防止随机偏差。实验结果如图所示,其中50%代表了推理增强的模型同直接的 System 1模型效果相当。
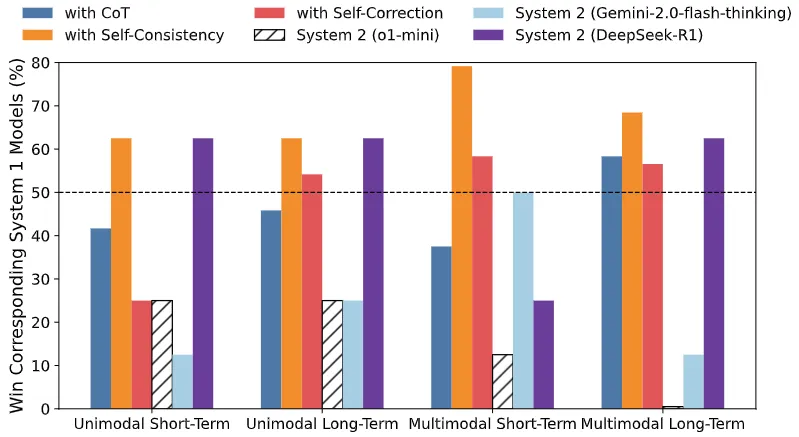
-
问题1:时序预测是否受益于推理能力?
回答:是的。
从预测窗口的长短方面来看,长期预测受益于推理能力更加明显。从模型模态方面来看,多模态模型收益更显著。
-
问题2:时序预测需要何种推理策略?
回答:自我一致性(Self-Consistency)方法是目前最好的推理策略对于时序预测。
具体来说,自我一致性方法是指模型平行采样多条推理路径,选取最能代表采样一致性的结果。这契合了时序预测的逻辑:考虑多种未来的可能情况并选择最有大概率的情况进行预测
-
问题3:System 2 是时序预测的答案吗?
回答:或许不是。
从实验结果上看,使用自我一致性方法的 System 1 模型在预测效果上甚至胜过 System 2 模型,而大多数 System 2 模型的提升是负面的,即低于50%的概率优于 System 1 模型。
这说明在时序预测任务上,单纯的 System 2 或许不是最有效的。这符合时序预测任务的认知:不是一个纯粹的推理任务,需要结合 System 1 的典型能力,例如模式识别。
-
问题4:各种时兴的 System 2 模型孰优孰劣?
回答:DeepSeek-R1 遥遥领先。
全部的3个 System 2 模型中(o1-mini, Gemini-2.0-flash-thinking,DeepSeek-R1),只有 DeepSeek-R1 是有效的,并且跨场景表现稳定。
作者认为,DeepSeek-R1 创新性地使用了 Group Relative Policy Optimization (GRPO) 强化学习策略,抛弃了 PPO 算法中直接对推理路径标注标签的行为更符合时序预测中未来的不确定性。
验证试验
由于 GPRO 算法仍处于探索阶段,作者将以上发现在两个常用的时序预测基础模型(Chronos,Moirai)上进行了验证试验。实验发现自我一致性方法中推理路径的采样数量和预测效果有着简明的正相关关系,同样印证了自我一致性方法的优势。

总结
ReC4TS 是首个针对零样本时序预测任务的推理策略评估基准。作者探讨了两个关键问题:(RQ1)推理能力是否有助于零样本时序预测?(RQ2)哪种推理策略最有效?
结果表明:零样本时序预测确实能从推理能力中受益 ,并进一步证明使用自我一致性方法的推理策略在零样本时序预测任务中带来了最显著的提升。
作者期待评估结果,洞见和工具库能有助于推理能增强的时序模型研究。
完整的评估套件、实验日志,以及Time-Thinking 数据集(蒸馏自多个先进LLM的 推理过程标注的TSF样本 ) 开源在https://github.com/AdityaLab/OpenTimeR。
编辑:王菁
