南洋理工&普渡提出CFG-Zero*,提升Flow Matching模型中无分类器引导的稳健性。通过优化缩放因子和零初始化,改善生成图像/视频的细节、文本对齐和稳定性。
原文标题:南洋理工&普渡大学提出CFG-Zero*:在Flow Matching模型中实现更稳健的无分类器引导方法
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到CFG在模型训练不足时会引入误差,CFG-Zero*通过零初始化缓解这个问题。那么,除了零初始化,是否存在其他方法来解决训练初期CFG的误差问题?例如,是否可以设计一种自适应的CFG强度调整策略,根据训练进度动态调整CFG的权重?
3、CFG-Zero*在文本生成图像和视频任务中都取得了不错的效果,那么它在其他生成任务中,例如音频生成、3D模型生成等方面是否也能适用?如果适用,需要进行哪些调整?
原文内容

本篇论文是由南洋理工大学 S-Lab 与普渡大学提出的无分类引导新范式,支持所有 Flow Matching 的生成模型。目前已被集成至 Diffusers 与 ComfyUI。

-
论文标题:CFG-Zero*: Improved Classifier-Free Guidance for Flow Matching Models
-
论文地址:https://arxiv.org/abs/2503.18886
-
项目主页:https://weichenfan.github.io/webpage-cfg-zero-star/
-
代码仓库:https://github.com/WeichenFan/CFG-Zero-star
随着生成式 AI 的快速发展,文本生成图像与视频的扩散模型(Diffusion Models)已成为计算机视觉领域的研究与应用热点。
近年来,Flow Matching 作为一种更具可解释性、收敛速度更快的生成范式,正在逐步取代传统的基于随机微分方程(SDE)的扩散方法,成为主流模型(如 Lumina-Next、Stable Diffusion 3/3.5、Wan2.1 等)中的核心方案。
然而,在这一技术迭代过程中,一个关键问题依然存在:如何在推理阶段更好地引导生成过程,使模型输出更加符合用户提供的文本描述。
Classifier-Free Guidance(CFG)是当前广泛采用的引导策略,但其引导路径在模型尚未充分训练或估计误差较大时,容易导致样本偏离真实分布,甚至引入不必要的伪影或结构崩塌。
对此,南洋理工大学 S-Lab 与普渡大学的研究者联合提出了创新方法——CFG-Zero*,针对传统 CFG 在 Flow Matching 框架下的结构性误差进行了理论分析,并设计了两项轻量级但效果显著的改进机制,使生成图像/视频在细节保真度、文本对齐性与稳定性上全面提升。

研究动机:CFG 为何失效?
传统的 CFG 策略通过对有条件与无条件预测结果进行插值来实现引导。然而在 Flow Matching 模型中,推理过程是通过解常微分方程(ODE)进行的,其每一步依赖于前一步的速度估计。
当模型训练不足时,初始阶段的速度往往较为不准确,而 CFG 此时的引导反而会将样本推向错误轨迹。研究者在高斯混合分布的可控实验中发现,CFG 在初始步的引导效果甚至不如「静止不动」,即设速度为 0。
方法介绍
研究者提出了 CFG-Zero*,并引入以下两项关键创新:

这两项策略可无缝集成至现有的 CFG 推理流程中,几乎不引入额外计算开销。下面我们具体介绍该方法的细节:
优化缩放因子
首先,CFG 的目标是能够估计出一个修正的速度,能够尽可能接近真实速度:
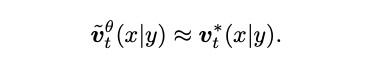
为了提升引导的精度,研究者引入了一个修正因子 s:
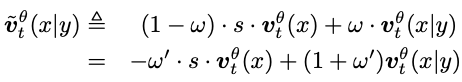
基于此可以建立优化的目标:
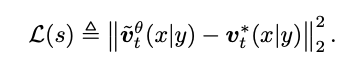
代入化简可以得到:
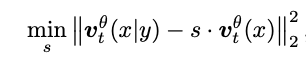
求解最优值为:
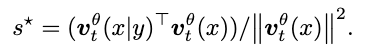
因此新的 CFG 形式为:
零初始化
研究者在 2D 多元高斯分布上进行进一步定量分析,可以求解得到扩散过程中每一步的最优速度的 closed-form:
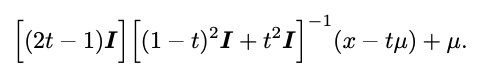
基于此,他们在训练了一个模型,并分析训练不同轮数下模型的误差,如下图所示。
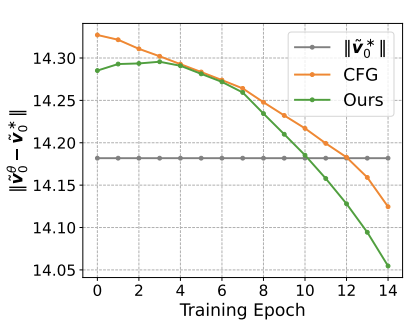
研究者发现在训练早期阶段,无分类引导得到的速度误差较大,甚至不如将速度设置为 0:
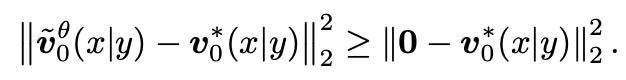
他们进一步在高维情况下验证了这一观察,如下图所示。
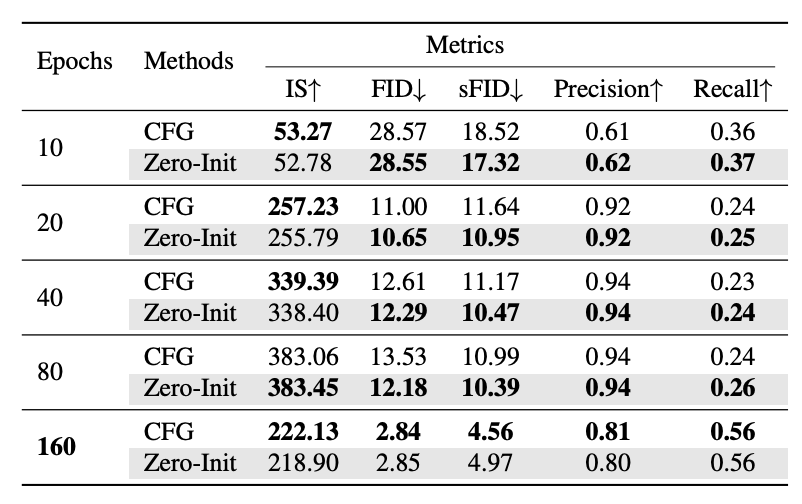
研究者对比原始 CFG 与仅使用零初始化的 CFG,发现随着模型的收敛,零初始化的收益逐渐变小,在 160 轮训练后出现拐点,与多元高斯实验结果吻合。
实验结果
研究者在多个任务与主流模型上验证了 CFG-Zero* 的有效性,涵盖了文本生成图像(Text-to-Image)与文本生成视频(Text-to-Video)两大方向。
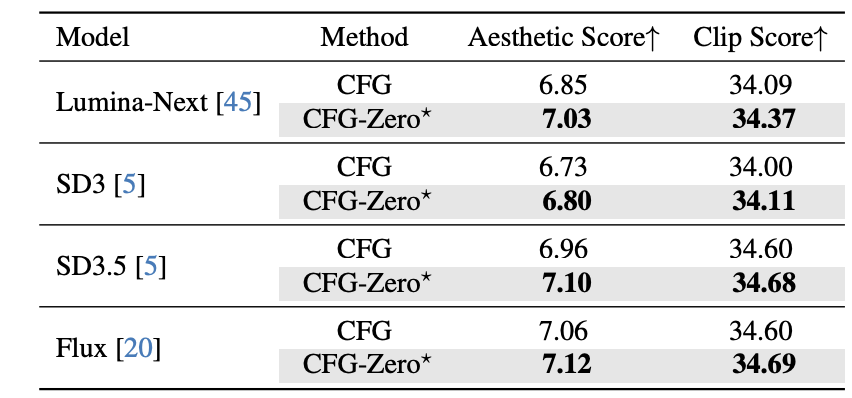
在图像生成任务中,研究团队选用了 Lumina-Next、SD3、SD3.5、Flux 等当前 SOTA 模型进行对比实验,结果显示 CFG-Zero* 在 Aesthetic Score 与 CLIP Score 两项核心指标上均优于原始 CFG。
例如在 Stable Diffusion 3.5 上,美学分有明显提高,不仅图像美感更强,而且语义一致性更好。在 T2I-CompBench 评测中,CFG-Zero* 在色彩、纹理、形状等多个维度均取得更优表现,特别适用于需要精准表达复杂语义的生成任务。
在视频生成任务中,研究者将 CFG-Zero* 集成到 Wan2.1 模型中,评估标准采用 VBench 基准套件。结果表明,改进后的模型在 Aesthetic Quality、Imaging Quality、Motion Smoothness 等方面均有所提升,呈现出更连贯、结构更稳定的视频内容。CFG-Zero* 有效减少了图像跳变与不自然的位移问题。
实际测试
CFG-Zero* 在开源社区中实现了快速落地。目前,该方法已正式集成至 ComfyUI 与 Diffusers 官方库,并被纳入视频生成模型 Wan2.1GP 的推理流程。借助这些集成,普通开发者与创作者也能轻松体验该方法带来的画质与文本对齐提升。

该方法可以用于图生视频。我们使用官方的 repo 用这张测试图:
输入 prompt:「Summer beach vacation style. A white cat wearing sunglasses lounges confidently on a surfboard, gently bobbing with the ocean waves under the bright sun. The cat exudes a cool, laid-back attitude. After a moment, it casually reaches into a small bag, pulls out a cigarette, and lights it. A thin stream of smoke drifts into the salty breeze as the cat takes a slow drag, maintaining its nonchalant pose beneath the clear blue sky.」
得到的视频如下:(第一个为原始 CFG 生成的,第二个为 CFG-Zero* 生成的),效果还是比较明显,值得尝试。


该方法对 Wan2.1 文生视频同样适用:(图 1 为原始 CFG,图 2 为 CFG-Zero*)


使用的 Prompt:「A cat walks on the grass, realistic.」
该方法同时兼容 LoRA:
使用的 LoRA 为:https://civitai.com/models/46080?modelVersionId=1473682
Prompt:「Death Stranding Style. A solitary figure in a futuristic suit with a large, intricate backpack stands on a grassy cliff, gazing at a vast, mist-covered landscape composed of rugged mountains and low valleys beneath a rainy, overcast sky. Raindrops streak softly through the air, and puddles glisten on the uneven ground. Above the horizon, an ethereal, upside-down rainbow arcs downward through the gray clouds — its surreal, inverted shape adding an otherworldly touch to the haunting scene. A soft glow from distant structures illuminates the depth of the valley, enhancing the mysterious atmosphere. The contrast between the rain-soaked greenery and jagged rocky terrain adds texture and detail, amplifying the sense of solitude, exploration, and the anticipation of unknown adventures beyond the horizon.」

该方法对最强文生图模型 Flux 同样支持:

使用的 Prompt:「a tiny astronaut hatching from an egg on the moon.」
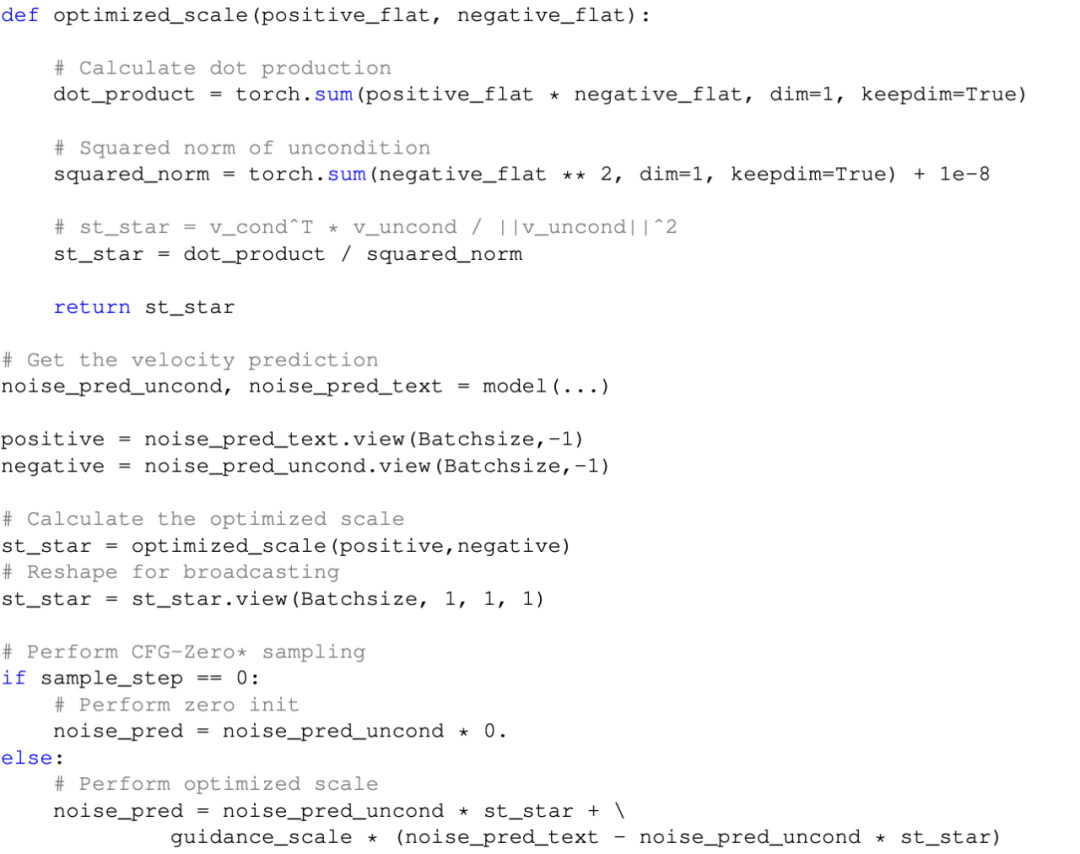
该方法实现也比较简单,作者在附录中直接附上了代码,如下图:

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com