上海交大等机构开源MAYE,一套透明、可复现、可教学的视觉语言模型(VLM)的RL训练框架与标准化评估方案,助力VLM研究。
原文标题:从零搭一套可复现、可教学、可观察的RL for VLM训练流程,我们试了试
原文作者:机器之心
冷月清谈:
怜星夜思:
2、MAYE框架强调“白盒化”,将训练流程解构为四个清晰的模块。在实际应用中,你认为哪个模块对VLM的性能影响最大?为什么?
3、文章提到“反思行为(Reflection)频率与输出长度高度相关,但大多数性能提升仍来源于非反思型推理”。你如何理解这种现象?它对我们设计更有效的VLM训练策略有什么启示?
原文内容

自 Deepseek-R1 发布以来,研究社区迅速响应,纷纷在各自任务中复现 R1-moment。
在过去的几个月中,越来越多的研究尝试将 RL Scaling 的成功应用扩展到视觉语言模型(VLM)领域 —— 刷榜、追性能、制造 “Aha Moment”,整个社区正高速奔跑,RL for VLM 的边界也在不断被推远。
但在这样一个节奏飞快、聚焦结果的研究环境中,基础设施层面的透明性、评估的一致性,以及训练过程的可解释性,往往被忽视。
这会带来三个问题:
-
当底层实现依赖封装复杂的 RL 库时,整体流程往往难以看清,理解和修改成本高,不利于方法的教学与传播;
-
缺乏一致、鲁棒的评估标准,不同方法之间难以公平比较,也难以积累长期洞察;
-
训练过程行为不可观测,模型如何学习、学习出了什么能力、训练过程中出现了哪些行为变得难以分析。
于是,来自上海交通大学、MiniMax、复旦大学和 SII 的研究团队选择按下暂停键,进行了一次关于 RL Scaling 的重新思考(Rethinking):
他们提出 MAYE —— 一个从零实现的 RL for VLM 框架与标准化评估方案,希望为该领域奠定一个透明、可复现、可教学的研究起点。

-
论文标题:Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme
-
论文地址:https://arxiv.org/pdf/2504.02587
-
代码地址:https://github.com/GAIR-NLP/MAYE
-
数据集地址:https://huggingface.co/datasets/ManTle/MAYE
三大核心贡献
重塑 RL+VLMs 的研究范式
1. 简洁透明的 RL for VLM 训练架构:轻依赖、强可控
MAYE 的实现很「干净」:
-
没有 Ray / DeepSpeed / TRL / Verl / OpenRLHF / AReaL
-
从零实现,无黑箱封装,无多余抽象
-
基于 Transformers / FSDP2 / vLLM 搭建,专为 VLM 设计
-
支持灵活改动,适合教学与研究场景
这样的设计不仅提升了训练过程的可解释性,也极大降低了 RL for VLM 的入门门槛:每一行代码、每一个环节都可见、可查、可改,研究者可以更清晰地理解模型是如何学习的,又为何能收敛。
我们并未采用当前 VLM-RL 社区常用的 GRPO,而是选择探索 Reinforce++ 的替代可能性。整个项目的灵感来源于 OpenAI Spinning Up,我们希望 MAYE 能成为 VLM-RL 研究中的一个轻量、透明、可教学的入门底座。
相比市面上黑盒化程度较高的 RL 框架,MAYE 更像是一个透明的「教学级实验框架」:既可直接运行,也可任意插拔、修改各个组件,非常适合用于方法对比、原理教学,甚至作为新手入门的第一课。
我们将完整的训练流程解构为 4 个轻量模块:
数据流动(data flow) → 响应采集 (response collection) → 轨迹构造 (trajectory generation)→ 策略更新 (policy update)
每一步都通过清晰的接口呈现,可以像乐高一样自由拼接、替换,将原本复杂封装的黑盒流程彻底 “白盒化”。
训练过程不再是只能看 loss 和 accuracy 的黑箱,而是变成一条可以观察、分析、干预的路径。

RL for VLM,只需四步:结构清晰,可拆可查
2. 标准化评估方案:看清训练过程,看懂模型行为
RL 研究中,一直存在两个老大难问题:训练过程不稳定,评估过程不透明。
尤其在 VLM 场景下,很多 RL 工作只关注 “最后结果”,缺乏对学习曲线、行为演化的系统性观察与分析。
那么 —— 模型究竟是如何学会的?反思能力是如何出现的?长输出真的等于更强推理吗?过去缺乏统一的方式来回答这些问题。
为此,MAYE 提出了一整套细致、可复现的标准化评估方案(evaluation scheme),用于系统追踪训练动态和模型行为演化:
训练集指标:
-
accuracy curve(准确率曲线)
-
response length(响应长度)
-
多次独立运行取均值,展现真实学习趋势
验证 & 测试集指标:
-
pass@1 与 pass@8,在不同温度设置下评估泛化能力
-
提供平均值 + 最大值,全面覆盖性能变化
反思行为指标:
-
反思词使用频率统计(e.g., re-check, think again, verify)
-
五个比例指标,量化反思是否真正带来了正确率提升
这些指标覆盖了训练全过程,既能用于算法开发,也适合横向比较、机制研究。
无论你是做方法、做分析,还是做认知能力探测,MAYE 都能提供一套清晰可复现的过程视角。
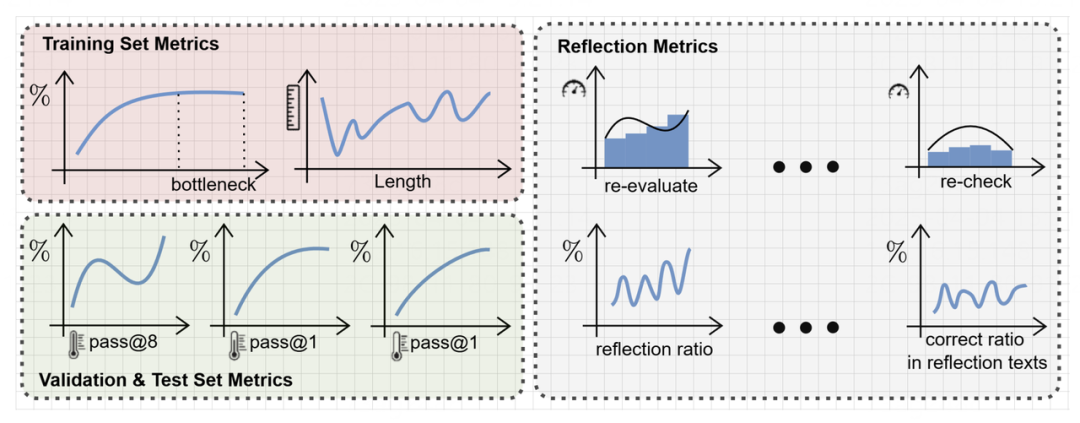
准确率曲线、输出长度、反思指标——三类视角还原 RL 全貌
3. 实证发现与行为洞察:RL 不止有效,更值得被理解
MAYE 不只是一个框架和评估工具,也是一套可以产出研究发现的实验平台。
研究团队在多个主流 VLMs(如 Qwen2 / Qwen2.5-VL-Instruct)和两类视觉推理数据集(文本主导 / 图像主导)上开展系统实验,复现实验足够稳健:所有结果均基于 3 次独立运行,并报告均值与标准差。
在此基础上,我们观察到了一些有代表性的现象:
-
输出长度会随着模型架构、数据分布、训练随机种子而显著变化,是判断模型推理策略演化的重要观测信号;
-
反思行为(Reflection)频率与输出长度高度相关,但大多数性能提升仍来源于非反思型推理。输出变长 ≠ 模型变强。长文本可能意味着更丰富的推理,也可能只是训练过程中的随机漂移或复读堆叠。只有当 “更长” 带来 “更准”,才值得被认为是有效行为;
-
Aha Moment 并不是 RL 训练凭空生成的,而是在 VLM 模型本身能力基础上被进一步激发和强化;

在多个模型和数据集上,系统追踪了训练动态与反思行为
在相同高质量监督数据(来自 textbook-style CoT)下,RL 在验证集和测试集上均显著优于 SFT,且具有更强的 OOD 泛化能力。即便是 Qwen2.5-VL 这类强基座模型,也能从 RL 中获得额外提升。

验证集与测试集全维度对比:RL 展现出更强的泛化能力

验证集与测试集全维度对比:RL 展现出更强的泛化能力
这些实证结果不仅揭示了 RL 对模型行为的真实影响,也为后续研究者提供了稳定、可对照的 baseline 实验结果。我们也呼吁社区更多采用多次独立运行报告结果,推动 RL for VLM 从 “能跑通” 迈向 “可分析、可信任”。
结语
MAYE 并不是一项追求极致性能的框架优化工程,而是一套面向研究者与教学场景的基础设施尝试。
我们希望它能成为 RL-VLM 研究中一块干净的起点,帮助社区更透明地理解训练过程、更一致地衡量行为变化、也更高效地探索 RL Scaling for VLM 的边界。
这只是一个起步,希望它对你的工作有所帮助。欢迎反馈、改进、复用。论文与代码资源全面开源,欢迎研究者探索和复现。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com