国产数据库迁移需关注事务处理差异。本文对比不同数据库的ACID属性、隔离级别和回滚机制,并探讨SAVEPOINT的合理使用,助力平滑迁移。
原文标题:国产数据库与Oracle数据库事务差异分析
原文作者:牧羊人的方向
冷月清谈:
怜星夜思:
2、文章中提到了多种数据库的默认隔离级别,以及不同隔离级别可能出现的并发问题,在实际生产环境中,你是如何权衡数据库隔离级别和并发性能的?有没有遇到过由于隔离级别选择不当导致的问题?
3、文章提到了SAVEPOINT可能引发的性能问题,那么在必须使用SAVEPOINT的场景下,除了文章中提到的优化方法,还有什么其他的策略来减少SAVEPOINT对数据库性能的影响?
原文内容
数据库中的ACID是事务的基本特性,而在Oracle等数据库迁移到国产数据库国产中,可能因为不同数据库事务处理机制的不同,在迁移后的业务逻辑处理上存在差异。本文简要介绍了事务的ACID属性、事务的隔离级别、回滚机制和超时机制,并总结SAVEPOINT的使用,以总结。
1、数据库中事务基本概念
事务是数据库中的基本逻辑操作单元,由一组不可分割的数据库操作序列组成,这些操作要么全部成功执行,要么全部失败回滚。其核心目的是确保数据的完整性和一致性,尤其在并发操作或系统故障时维护数据库的可靠状态。
ACID是事务的基本特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
-
原子性:事务中的所有操作必须作为一个整体执行,要么全部执行成功、要么全部失败回滚,不允许出现部分成功的情况。在数据库中通常是通过日志记录(如undo log)来实现回滚操作,若事务执行失败,系统跟进日志撤销已执行的操作。
-
一致性:事务执行前后,数据库必须保持一致性状态。所有数据必须满足预定义的完整性约束(如主键、外键、唯一性约束等)。即使事务失败,数据库也不能破坏这些规则。在数据库中通过一些约束和检查来确保数据库的完整性约束。
-
隔离性:多个事务并发执行时,每个事务的操作应与其他事务相互隔离,使得每个事务感觉不到其他事务的存在,最终效果应与事务串行执行的结果一致。数据库中通过锁机制(Locking)或多版本并发控制(MVCC)实现,不同的隔离级别提供不同程度的隔离性。
-
持久性:事务一旦提交,其对数据库的修改就是永久性的,即使系统发生故障(如断电、崩溃),修改也不会丢失。数据库中通过重做日志(Redo Log)实现持久性。提交事务时,对数据的修改首先写入日志,再异步写入数据库文件中。当数据库崩溃恢复时,通过重放日志恢复数据。
以转账交易为例,通过undo日志实现原子性,确保“扣款”和“存款”两个操作要么全部成功,要么全部失败;一致性是确保转账前后,数据库必须满足业务规则(如余额不为负、总额不变);通过锁机制和MVCC多版本并发控制来实现事务的隔离性,多个并发转账操作互不干扰,结果与串行执行一致;持久性则是一旦转账成功,即使系统崩溃,修改也不会丢失。
BEGIN TRANSACTION;
-- 1. 检查一致性:用户A余额是否足够(一致性)
SELECT balance FROM accounts WHERE user = 'A' FOR UPDATE;
-- 如果余额 < 100,抛出错误并回滚
-- 2. 扣款(原子性)
UPDATE accounts SET balance = balance - 100 WHERE user = 'A';
-- 3. 存款(原子性)
UPDATE accounts SET balance = balance + 100 WHERE user = 'B';
-- 4. 提交(持久性)
COMMIT;
事务隔离级别是数据库事务处理的基础,SQL-92标准定义了4种隔离级别:读未提交(READ UNCOMMITTED)、读已提交(READ COMMITTED)、可重复读(REPEATABLE READ)、串行化(SERIALIZABLE)。详见下表:

不同的隔离级别有不同的现象,并有不同的锁和并发机制。隔离级别越高,数据库的并发性能就越差。
1)脏读
A事务读取B事务尚未提交的更改数据,并在这个数据的基础上进行操作,这时候如果事务B回滚,那么A事务读到的数据是不被承认的。

2)不可重复读
不可重复读是指在同一个事务中,同一个查询在T1时刻读取一行数据,在T2时刻重新读取这一行数据的时候,发现这一行数据已经发生了修改(被更新或者删除)。假如A在取款事务的过程中,B往该账户转账100,A两次读取的余额发生不一致。
3)幻读
幻读是指在同一个事务中,当同一个查询多次执行的时候,由于其它插入操作的事务提交,会导致每次返回不同的结果集。不可重复读和幻读的区别是:前者是指读到了已经提交的事务的更改数据(修改或删除),后者是指读到了其他已经提交事务的新增数据。

-
Share:lock owner和任何并发程序可以read但是不能change locked page或row,并发程序可能获得S-lock、U-lock,也可能没有lock就进行读操作
-
Update:lock owner可read但是不能change locked page或row,但是owner可以将U-lock升级为X-lock这样就可以修改page或row
-
升级为X-lock这个过程可能会引起其它S-lock的并发进程暂停在那
-
当lock owner读数据的时候并决定是否需要修改它的时候,U-lock会减少deadlocks的几率
-
Exclusive:只有lock owner才能read或change locked page或row,并发程序只有当程序处于UNCOMMITTED read isolation的时候才能访问数据
-
Lock mode compatibility,见下表
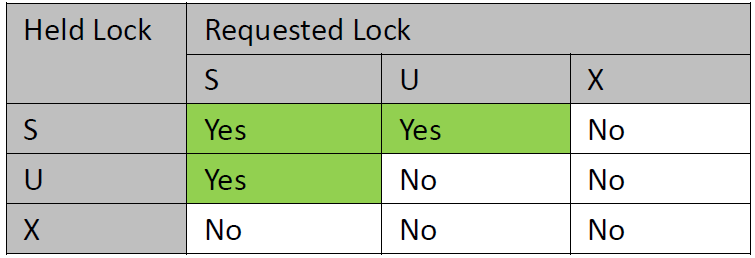
比如说User A对page hold住S-lock,如果User B想对page请求X-lock,则User A的lockmode会拒绝User B的请求。
1)读未提交(Read Uncommitted)
读未提交,就是一个事务可以读取另一个未提交事务的数据,也称为脏读。在读数据时候不加锁,写数据时候加行级别的共享锁,提交时释放锁。行级别的共享锁,不会对读产生影响,但是可以防止两个同时的写操作
2)读已提交(Read Committed)
读提交,就是一个事务要等另一个事务提交后才能读取它的数据,否则是读取不到另外一个事务的更改的数据。事务读取数据(读到数据的时候)加行级共享S锁,读完释放;事务写数据时候(写操作发生的瞬间)加行级独占X锁,事务结束释放。由于事务写操作加上独占X锁,因此事务写操作时,读操作也不能进行,因此,不能读到事务的未提交数据,避免了脏读的问题。但是由于,读操作的锁加在读上面,而不是加在事务之上,所以,在同一事务的两次读操作之间可以插入其他事务的写操作,所以可能发生不可重复读的问题。
3)可重复读(Repeatable Read)
当事务隔离级别为可重复读时,只能读到该事务启动时已经提交的其他事务修改的数据,未提交的数据或在事务启动后其他事务提交的数据是不可见的。对于本事务而言,事务语句可以看到之前的语句做出的修改。事务读取数据在读操作开始的瞬间就加上行级共享S锁,而且在事务结束的时候才释放。但是,由于加的是行级别的锁,仍然可能发生幻读的问题。
4)序列化(Serialization)
最严格的隔离级别,强制事务串行执行,使之不可能冲突,从而解决幻读的问题,资源消耗最大。在读操作时,加表级共享锁,事务结束时释放;写操作时候,加表级独占锁,事务结束时释放。在这个级别,可能会导致大量的锁超时和锁竞争现象,实际上也很少用到。
不同数据库支持的隔离级别也不同

-
Oracle数据库支持读已提交和序列化,默认隔离级别为Read Committed,通过通过多版本并发控制(MVCC)避免脏读,但存在不可重复读和幻读。
-
MySQL数据库支持四种隔离级别,默认为可重复读,通过MVCC和间隙锁来减少幻读问题。
-
MySQL数据库支持四种隔离级别,默认为Read Committed
-
OceanBase(for Oracle)模式支持读已提交和序列化,默认为Read Committed
-
TiDB支持读已提交、可重复读和序列化,默认为Repeatable Read,其实在TiDB中实现是快照隔离,类似可重复读;
-
GoldenDB兼容MySQL的隔离机制,支持4种隔离级别,但是默认的级别是Read Committed,也是并发和一致性平衡的结果;
-
GaussDB支持Read Committed和Repeatable Read,默认隔离级别是Read Committed
事务的原子性要求事务要么全部执行成功、要么全部执行失败回滚,但是对于Oracle数据库支持语句级的原子性,也就是一个事务中单个语句执行失败,则只会回滚该语句执行的操作,不会导致在当前事务中丢失之前的任何工作。如果需要回滚整个事务,需要处理错误并且主动调用ROLLBACK。这种语句级的回滚对于处理一些长时间运行的批处理任务有用,逻辑上希望能够处理错误,不需要回滚已经完成的所有操作。

不过从Oracle数据库迁移到国产数据库中,大部分数据库在事务的回滚机制上并不支持语句级别的,因此需要通过采用SAVEPOINT保存点的方式。使用SAVEPOINT虽然可以解决语句级别功能上的需求,但是不合理的使用可能引发其它问题。
数据库中事务会设置不同的超时机制,防止因为出现等锁而出现无限等待,超过这个时间后会出现等锁超时,事务会回滚。

-
Oracle数据库:默认不会主动终止因行锁等待而阻塞的事务,事务会无限期等待锁释放,需由应用层处理或手动终止,行锁在事务提交或回滚是自动释放;事务默认也无超时设置,但是可以限制会话的空闲时间,超过时间后会断开链接。
-
MySQL数据库:通过 innodb_lock_wait_timeout 控制,默认为50秒。当事务等待锁超过此时间时,会抛出错误;事务中无默认超时时间,但是连接的空闲超时设置wait_timeout,默认8小时。
-
PostgreSQL:通过pg_lock_timeout设置行锁等待超时时间,默认为0无限等待;事务中设置statement_timeout 控制单条SQL执行时间,默认无限制。
-
TiDB:兼容MySQL行锁等待设置;如果是悲观事务,默认TTL(Time-To-Live)为 1小时,超时后自动回滚,另外通过tidb_idle_transaction_timeout 控制空闲事务。
-
OceanBase:MySQL模式下兼容MySQL设置;事务中通过 ob_query_timeout 控制事务单条语句执行时间,默认1800s
-
GoldenDB:兼容MySQL设置
-
GaussDB:参数lockwait_timeout控制单个锁的最长等待时间,当申请的锁等待时间超过设定值时,系统会报错,默认为20min;通过通过 statement_timeout 控制单个语句执行时长,默认0表示不控制。
前文提到Oracle数据库中支持语句级别的回滚,在迁移到国产数据库后,为了兼容Oracle数据库这个特性,很多数据库支持SAVEPOINT机制。SAVEPOINT是事务中的一个逻辑标记点,用于标识事务执行到某个特定位置的状态。通过ROLLBACK TO SAVEPOINT可以回滚到该标记点,撤销该点之后的所有操作,但保留该点之前的操作。SAVEPOINT可以提供细粒度的事务控制,避免因整个事务回滚导致的数据丢失。对于一些复杂或长时间运行的事务中,可以分阶段提交或回滚操作。
BEGIN
INSERT INTO orders (id, amount) VALUES (1, 100);
SAVEPOINT sp1; -- 设置保存点sp1
UPDATE inventory SET stock = stock - 1 WHERE product_id = 101;
SAVEPOINT sp2; -- 设置保存点sp2
-- 假设此处发生错误
ROLLBACK TO sp1; -- 回滚到sp1,撤销UPDATE操作
COMMIT; -- 提交事务(仅保留INSERT操作)
END;
但是在一个长事务中不规范的使用SAVEPOINT可能会导致实例内存上涨、事务执行时间异常的问题。比如在Oracle数据库中的一个游标查询语句,每1K笔执行一次,迁移到GaussDB之后,URL串中指定了autosave参数,这样在每次游标访问时候都会执行一次SAVEPOINT动作,原来几分钟的任务可能几个小时都执行不完,出现很多SAVEPOINT等待事件,并且数据库实例的内存逐渐上涨。
那么对于一些复杂的业务场景,如何合理的使用SAVEPOINT?
-
禁止自动设置SAVEPOINT,只在必要时设置SAVEPOINT,如在数据更新、复杂逻辑分支操作上设置;
-
将长事务拆分为多个小事务,每处理一定的数据后提交,以释放资源;
-
避免在游标循环中频繁执行SAVEPOINT,改用批量处理或分页查询;
-
及时回滚或释放无用SAVEPOINT,在逻辑分支完成后,主动回滚到最近的SAVEPOINT并释放资源;
-
避免嵌套过深的SAVEPOINT:过多的嵌套SAVEPOINT会增加回滚段的复杂度。
参考资料:
-
https://pigsty.cc/blog/db/oracle-pg-xact/
-