Dapr Agents是一个利用Dapr构建可扩展AI智能体的框架,支持工作流、多智能体协作和事件驱动执行,关注可靠性和可观测性。
原文标题:Dapr Agents 发布:支持规模化 AI 工作流、多智能体协作
原文作者:AI前线
冷月清谈:
怜星夜思:
2、Dapr Agents 使用 Dapr 的发布/订阅消息传递进行多智能体协作,这种方式相比传统的消息队列有什么优缺点?在哪些场景下更适用?
3、文章提到Dapr Agents可以抽象与数据库和消息智能体的集成,这对于开发者来说意味着什么?在实际开发中,如何利用这个特性来提升开发效率?
原文内容

Dapr 最近推出了 Dapr Agents,一个利用大语言模型构建可扩展、可靠的 AI 智能体的框架。它支持结构化的工作流、多智能体协调和基于事件驱动的执行能力,并利用了 Dapr 的安全性、可观测性和云中立架构。Dapr Agents 专为企业使用而设计,支持数千个智能体,可与数据库集成,并通过强大的编排和消息传递确保可靠性。
Dapr Agents 基于 Dapr 提供了一个框架,用于开发能够利用 LLM 进行推理、行动和协作的 AI 智能体。它提供了可靠性、可扩展性和可观测性,支持在单个核心上运行数千个智能体,并且原生支持在 Kubernetes 上运行。作者 Mark Fussell、Yaron Schneider 和 Roberto Rodriguez 描述了 Dapr Agents 与其他框架的不同之处:
Dapr Agents 基于 Dapr 的完整工作流引擎。许多其他智能体和 LLM 框架使用的是自建的工作流系统,这些系统在生产环境中往往不够可靠。Dapr Agents 使用经过验证的 Dapr 工作流系统,该系统具备很好的处理故障、重试和扩展问题的能力。
import logging
import asyncio
import requests
from dotenv import load_dotenv
from dapr_agents.llm.dapr import DaprChatClient
from dapr_agents import AssistantAgent, tool
# Load environment variables
load_dotenv()
logging.basicConfig(level=logging.INFO)
@tool
def get_pr_code(repository: str, pr: str) -> str:
"""Get the code for a given PR"""
response = requests.get(f"https://api.github.com/repos/{repository}/pulls/{pr}/files")
files = response.json()
code = {file["filename"]: requests.get(file["raw_url"]).text for file in files}
return code
@tool
def perform_review(code: str) -> str:
"""Review code"""
response = DaprChatClient().generate(f"Review the following code: {code}")
return response.get_content()
# Define Code Review Agent
code_review_agent = AssistantAgent(
name="CodeReviewAgent",
role="Review PRs",
instructions=["Review code in a pull request, then return comments and/or suggestions"],
tools=[get_pr_code, perform_review],
message_bus_name="messagepubsub",
state_store_name="workflowstatestore",
agents_registry_store_name="agentstatestore",
service_port=8001,
)
# Start Agent Workflow Service
await code_review_agent.start()
使用 Dapr Agent 构建代码评审智能体的示例(来源)
Distributed Application Runtime (Dapr) 是一个开源框架,通过提供服务调用、状态管理、发布 / 订阅消息传递和可观测性等构建块来简化云原生应用程序的开发。它抽象了基础设施的复杂性,让开发人员能够专注于业务逻辑,并能够无缝地集成到 Kubernetes 和其他环境中。
Agentic AI 指的是那些能够自主处理信息、做出决策并执行任务的 AI 的驱动系统。在这一领域有多种解决方案,包括 LangChain、AutoGen 和 CrewAI 等框架,它们为开发人员提供了构建基于智能体的应用程序的能力。
Dapr Agents 利用大语言模型作为其推理引擎,并与外部工具集成来增强功能。开发者可以创建具备预定义角色、目标和指令的智能体,赋予它们推理能力以及基于工具的行动能力。他们还可以利用包含 LLM 推理的函数来定义结构化、确定性的工作流。这些工作流确保任务按照预设的顺序执行,同时通过工具集成保持了灵活性。
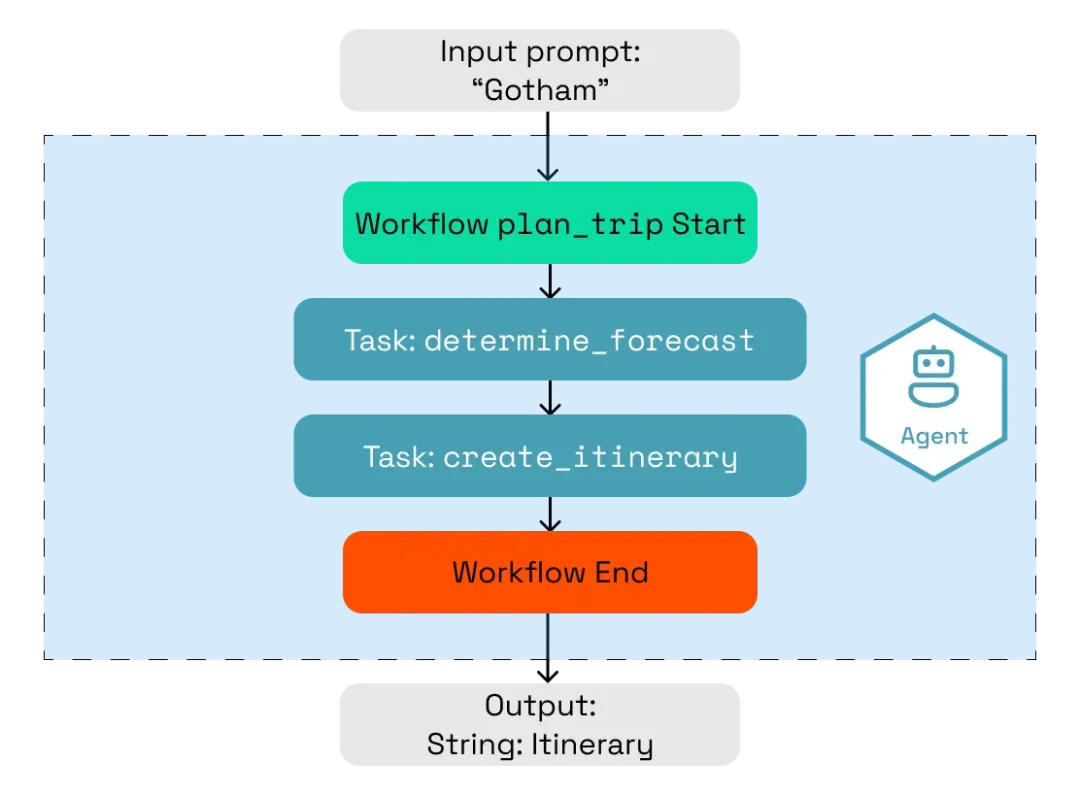
智能体工作流示例(来源)
Dapr Agents 支持多智能体工作流,智能体可以通过 Dapr 的发布 / 订阅消息传递进行协作。协调模型包括基于 LLM 的决策制定、随机选择和轮询任务分配,实现自适应、自我推理的工作流。作者进一步阐述了这一点:
智能体需要作为自主的实体来运行,能够动态响应事件,从而实现与工作流的实时交互和协作。这些事件驱动的智能体工作流利用了 Dapr 的发布 / 订阅消息传递系统,使得智能体能够通过消息智能体进行通信、共享任务,并根据环境触发的事件进行推理。
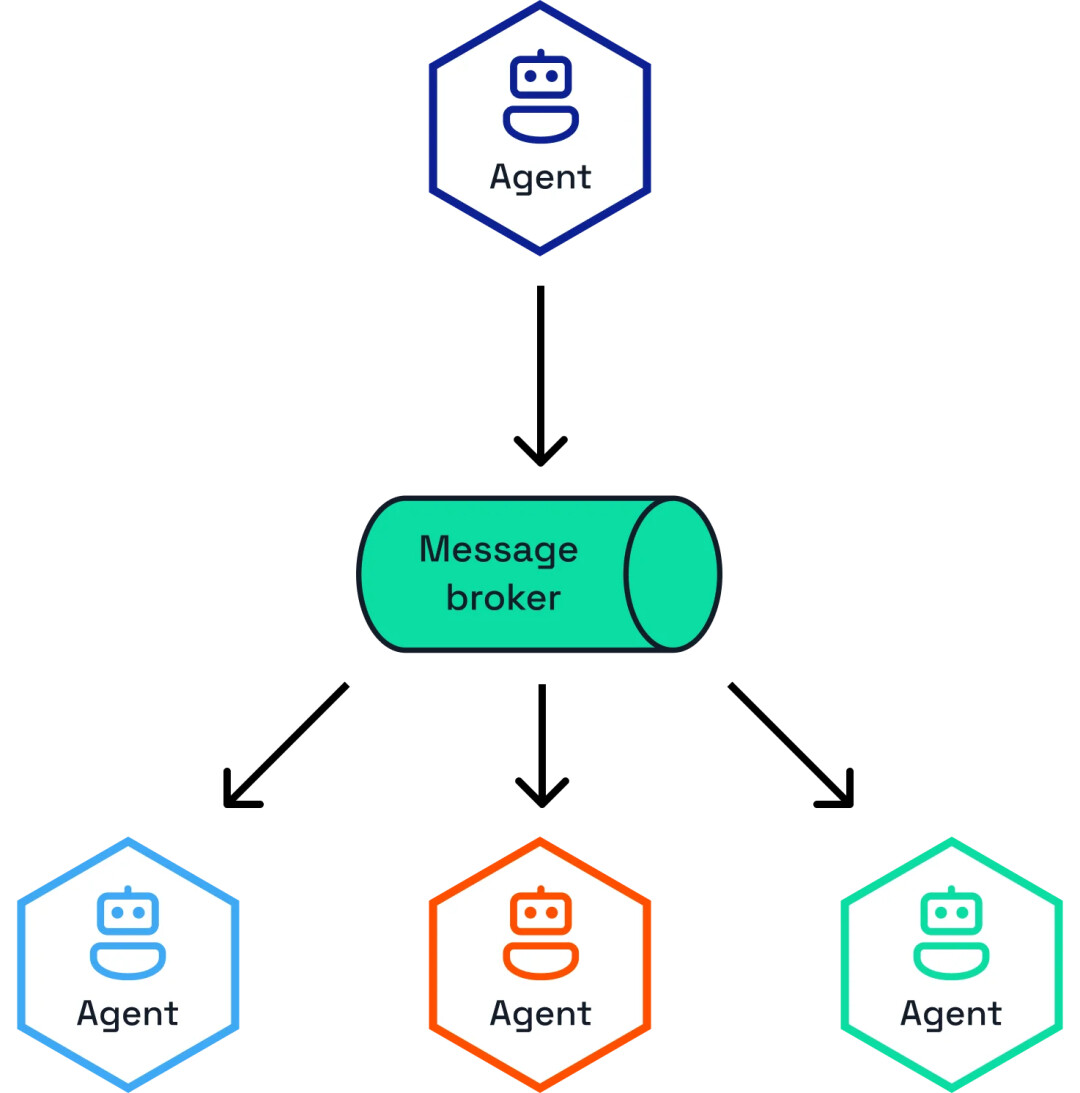
智能体可以通过消息智能体与其他智能体通信(来源)
该设计抽象了与数据库和消息智能体的集成,让开发人员能够在不进行重大代码更改的情况下切换基础设施供应商。它与 Prometheus 和 OpenTelemetry 等监控工具无缝集成,实现了可观测性。作为 CNCF 项目,它避免了供应商锁定,同时确保了安全通信和容错能力。
开发人员可以通过 GitHub 代码库探索 Dapr Agents 的功能,并加入 Discord 社区进行讨论和获取支持。
InfoQ 与 Diagrid 的 CTO 和 Dapr 维护者 Yaron Schneider 就 Dapr Agents、其实现和未来计划进行了交流。
Yaron Schneider:Dapr Agents 将智能体及其后续任务视为 Actor ——这些轻量级且持久的对象可以扩展到数百万个,具有非常低的延迟。这使得 Dapr Agents 能够在消耗极低 CPU 和内存的情况下运行大量智能体。由于 Dapr 可以原生集成到 Kubernetes 中,Dapr Agents 对故障具有高度弹性,并考虑到了 Kubernetes Pod 的瞬态特性。
Schneider:基于 Dapr 构建的 Dapr Agents 为其智能体工作流提供了指标数据,包括每秒请求数、错误率和延迟。此外,由于 Dapr 工作流支持分布式跟踪,开发人员可以使用 OTel 兼容工具来可视化智能体调用图。我们将在未来更多地在智能体可观测性方面进行投入。
Schneider:鉴于数据合成在智能体工作负载中的重要性日益增加,我们计划集成模型上下文协议(MCP),让开发人员能够通过状态存储和绑定 API 将 Dapr Agents 连接到各种数据源和 Dapr 的原生功能。此外,我们还计划通过 Dapr 的对话 API 增加对更多 LLM 供应商的支持。最重要的是,Dapr Agents 目前已经支持 Python,我们正在努力增加对 Dotnet 和 Java 的支持。
查看英文原文:
https://www.infoq.com/news/2025/03/dapr-agents/

