OpenING:首个开放式图文交错生成评测基准,包含多样化真实任务和高质量数据,并开源IntJudge评测模型,助力多模态大语言模型发展。
原文标题:CVPR 2025 Oral | 多模态交互新基准OpenING,新版GPT-4o杀疯了?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章中提到 IntJudge 能够更公平地评估模型,避免 GPT-as-a-Judge 的偏见。那么,你认为在构建评估模型时,除了数据增强和人机协作,还有哪些方法可以进一步减少偏见,提高评估的客观性?
3、OpenING 的评测结果显示,目前多模态模型在图像生成质量和真实性方面仍有很大提升空间。你认为未来在哪些技术方向上突破,能够显著提升图像生成质量,使模型生成的图像更接近真实世界?
原文内容

文生图 or 图生文?不必纠结了!
人类大脑天然具备同时理解和创造视觉与语言信息的能力。一个通用的多模态大语言模型(MLLM)理应复刻人类的理解和生成能力,即能够自如地同时处理与生成各种模态内容,实现多模态交互,这也是向通用人工智能(AGI)迈进的关键挑战之一。最近爆火的新版 GPT4o 与 Gemini-2.0 在图文交互这方向上也带来了令人振奋的效果。
然而,当前大部分多模态大语言模型仍局限于处理单一的图像或文本,特别是难以实现内容流畅一致的多模态交错生成。而现实生活中,以设计、教育、内容创作等代表的任务,往往需要获取图文交错的内容作为参考,这对模型的多模态生成能力提出了挑战。
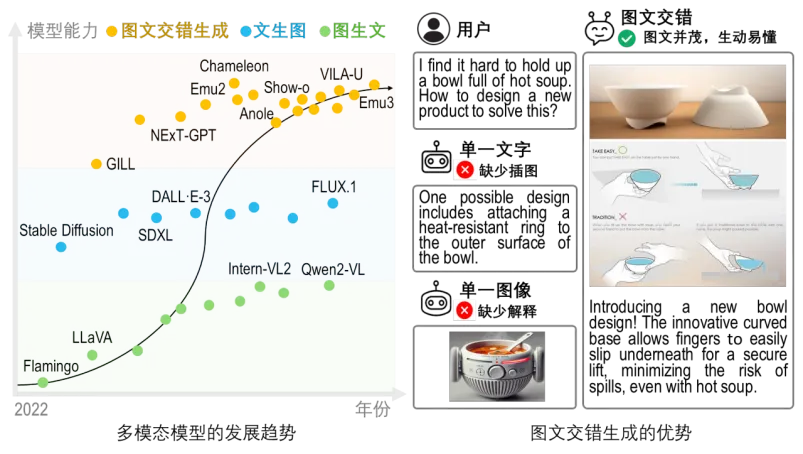
近日,上海人工智能实验室提出了首个面向开放式图文交错生成任务的综合评测基准 OpenING,相关论文成果已被 CVPR2025 接收为 Oral。该基准包含:1)多样化的真实图文生成任务与高质量的标注数据;2)通过增强训练得到的可靠裁判模型 IntJudge;3)对目前图文交错生成模型 / 统一理解生成模型进行的综合评测、排名与分析。研究中的关键发现与结论能够为下一代统一理解与生成的多模态大语言模型的研发提供了重要的启发与指导。

-
论文标题:OpenING: A Comprehensive Benchmark for Judging Open-ended Interleaved Image-Text Generation
-
技术报告: https://arxiv.org/abs/2411.18499
-
项目主页: https://opening-benchmark.github.io/
-
代码地址: https://github.com/LanceZPF/OpenING
OpenING 基准:更丰富、更真实、更全面
现有评测基准(如 OpenLEAF 和 InterleavedBench)存在规模小、主题多样性不足、数据来源受限等问题,且因过于依赖开源数据集作为数据来源导致数据污染的风险,难以满足真实场景的应用需求。

为此,OpenING 应运而生!
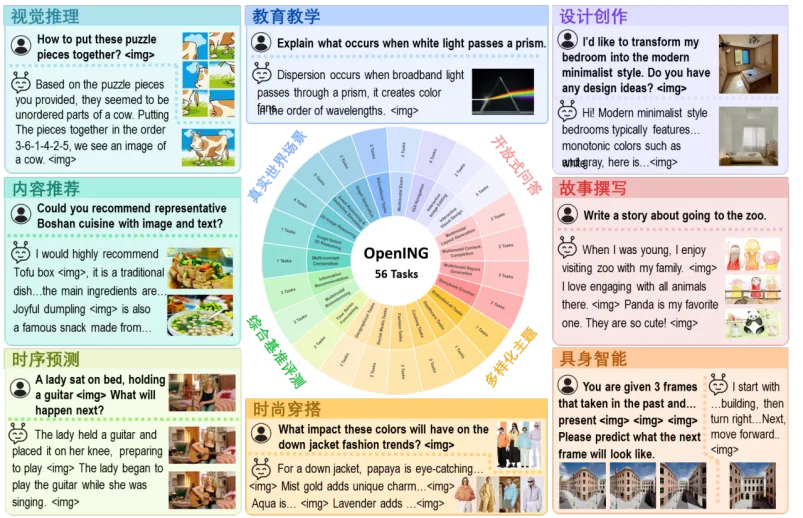
OpenING 首次系统地构建了涵盖 23 个现实领域、56 个具体任务的图文交错生成综合评测基准,共计收集 5400 个真实场景下的图文交错实例。这些实例来源于旅行指南、产品设计、烹饪助手、创意头脑风暴等日常高频应用场景。

OpenING 特别设计了高效的标注工具 IntLabel,由超过 50 人的专业团队严格把关,并通过精细化的标注流程确保了数据的一致性与真实性。OpenING 的数据划分为开发集和测试集两个部分,为 Judge 模型的训练和评测分析提供了坚实的基础。
强大评估模型 IntJudge:告别 GPT 偏见!
传统基于 GPT 的评测模型(比如 GPT-as-a-Judge)容易受到模型本身偏见,倾向于给自家生成的内容更高的评分。另外此类评测模型因为受到潜在的数据泄露的影响,使得评测的准确性和稳定性存疑。为了获得更加公平、精准、稳定的评测结果,OpenING 团队自主研发了一款名为 IntJudge 的评估模型。
IntJudge 的训练集采用了全新的人机协作标注方法 —Interleaved Arena,并在训练过程利用一种参考增强生成 Reference-Augmented Generation(RAG)的数据增强策略。通过融合人类专家评估数据和自动生成的数据,该策略大幅提升评测模型的鲁棒性和泛化能力。
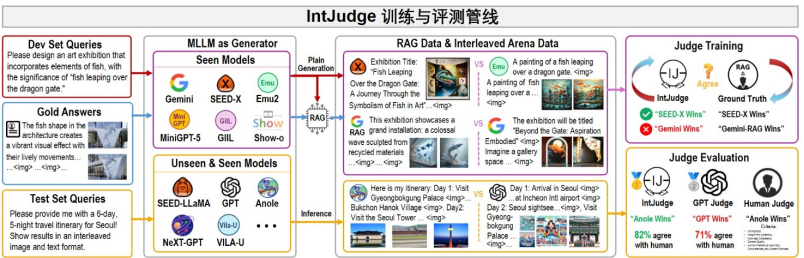
具体来讲,IntJudge 的训练数据由两部分组成:一是高质量对比数据 Interleaved Arena Data,这些数据通过对不同模型在 OpenING 开发集上生成的的图文交错内容进行人工判断获得;二是利用参考增强生成(RAG)技术构建的大规模增强数据 RAG Data,通过在每个 AB 对中认定以人工标注的金标准答案为参考的生成内容优于模型直接生成的内容。这种新颖的数据增强策略在极大丰富 IntJudge 模型训练数据量的同时确保了评测模型在多种生成风格和场景下的稳定表现。
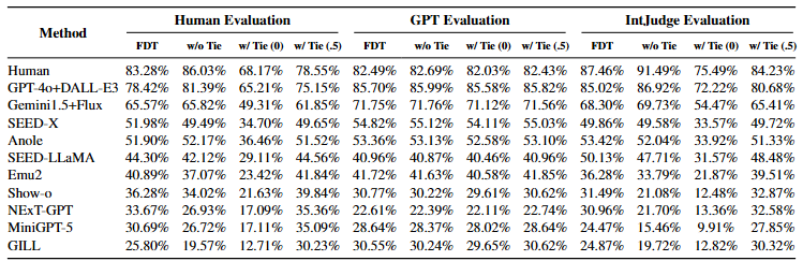
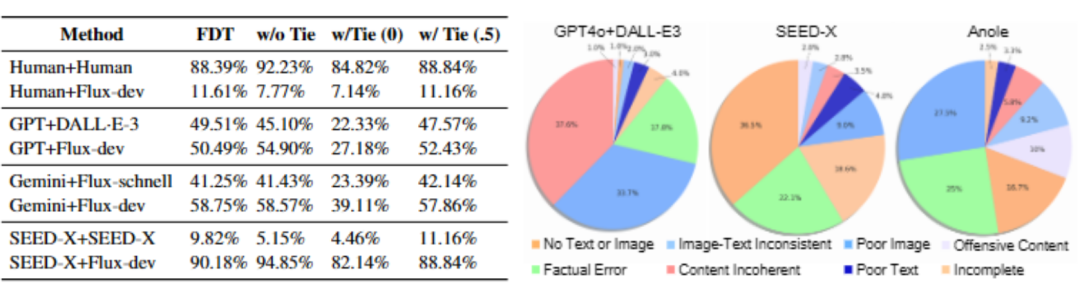
开放式问题的正确性通常难以直接判断,为此 OpenING 采用了类 ELO 机制的相对评分策略。该策略通过采样形成模型间的两两(AB Pair)对比,获得对模型客观性能评测的排行榜。这些客观指标包括强制区分平局指标 FDT, 以及该指标在包括平局 w/ Tie 和不包括平局 w/o Tie 的两种情况的指标。此外,OpenING 还提供多种额外评估指标, 包括基于 GPT-as-a-judge 的主观评测。

凭借创新的数据构建策略,IntJudge 与人类判断的一致率达到 82.42%,相较于基于 GPT 系列的评测方法 IntJudge 显著高出 11.34% . 此外,IntJudge 不仅适用于大规模自动化评测场景,还能够作为 Reward Model 直接应用于 GRPO 等强化学习(RL)训练,对多模态生成模型的性能和生成质量进行有效提升。IntJudge 训练过程中构建的 Interleaved Arena 数据也为多模态生成领域的直接偏好优化(DPO)研究提供了宝贵资源,进一步启发和促进该方向的深入探索。
模型生成性能大揭秘,与人类差距依然明显!
基于 OpenING 的详尽评测揭示了当前主流多模态模型的表现:
-
集成管道模型(如 GPT-4o+DALL・E-3 和 Gemini 1.5+Flux)得益于高性能基础模型的协同,整体表现优于其它模型。其生成内容在图文一致性与视觉质量方面均处领先地位。此外,这类交错生成管道的性能很大程度上取决于图像生成模型的能力。与其它主流图像生成模型相比,Flux-dev 在与多种文本模型搭配使用时展现出显著的性能提升
-
端到端模型(如 Anole、MiniGPT-5)具有统一的图文生成模型架构,其简洁的生成方式展现出了巨大的发展潜力。然而,目前此类模型在图像和文本生成的综合能力上仍存在较大提升空间
-
文本生成方面,GPT 系列模型的质量已达到甚至超越人类水平,但在图像生成质量和真实性方面,所有模型的生成结果仍难以企及人工标注的自然图像。
通过详细的误差分析发现当前模型普遍存在诸如图像视觉质量差、连续生成的内容不一致、以及无法有效生成图像或文本等问题。这些发现为下一步模型优化指明了明确的研究方向。此外,研究团队还针对不同类型模型(如 GPT-4o+DALL-E3、SEED-X、Anole 等)出现的具体问题进行了分析(例如事实性错误,文本或图片、图片风格不一致、生成效率不足等)并总结了问题出现的比例,为未来的方法优化提出了明确的路径。
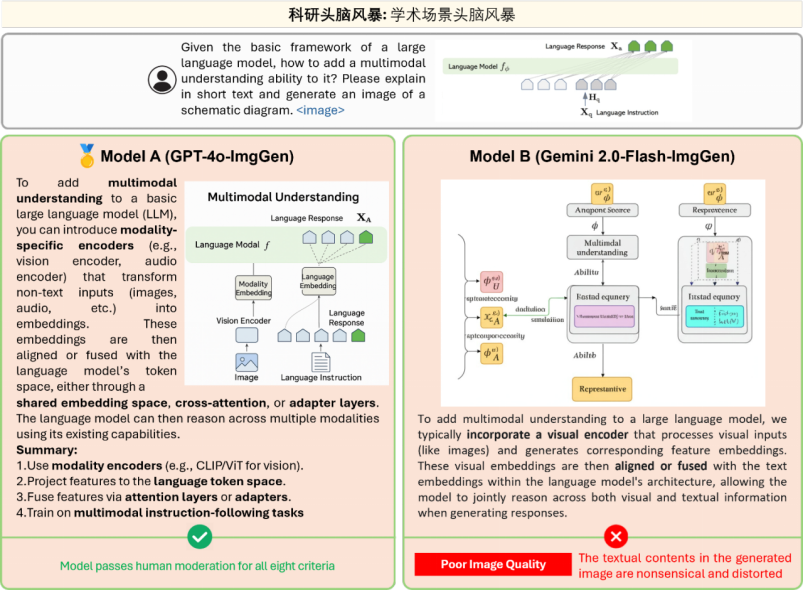
此外,在使用 OpenING 基准对近期发布的新模型 GPT-4o-ImgGen 和 Gemini 2.0-Flash-ImgGen 和进行评测时,我们惊喜地发现他们在多个任务中展现出了较强的图文理解能力,以及更为可靠的内容编辑与交错生成能力。同时,我们也观察到一些尚待解决的问题,例如 GPT-4o-ImgGen 对 prompt 中命令顺序的高度依赖 (如需要指示模型先生成文字再生成图像)且生图效率低,而 Gemini 2.0-Flash-ImgGen 无法在图片中生成高准确度和可识别的文字等。




开放源码与数据,全社区共建
为了推动图文交错生成领域的进一步发展,OpenING 研究团队已全面开源了完整的基准数据、IntJudge 评测模型及相关代码。
未来,OpenING 团队还将继续扩展数据规模与多样性,进一步优化评测模型,并推动更接近真实应用场景的研究。团队鼓励更多研究者加入,共同推进这一前沿领域的研究。研究团队相信,OpenING 将持续助力人工智能在真实场景中的落地,让机器真正具备与人类媲美的图文交互能力。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com