香港大学和华为发布Dream 7B,一款媲美大型自回归模型的扩散语言模型,在通用能力、数学推理和编程上表现出色,为NLP领域带来新可能。
原文标题:7B扩散LLM,居然能跟671B的DeepSeek V3掰手腕,扩散vs自回归,谁才是未来?
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章提到 Dream 7B 采用了 AR 模型初始化权重和上下文自适应 token 级噪声重排等技术,这些技术对于提升扩散模型的性能有多大帮助?你认为还有哪些可以改进的方向?
3、Dream 7B 在规划能力上超越了同等规模的 AR 模型,甚至在某些情况下优于 DeepSeek V3 671B。你认为扩散模型在规划能力上的优势来源于什么?这种优势对于未来的 AI 应用有哪些潜在价值?
原文内容
机器之心报道
编辑:张倩
语言是离散的,所以适合用自回归模型来生成;而图像是连续的,所以适合用扩散模型来生成。在生成模型发展早期,这种刻板印象广泛存在于很多研究者的脑海中。
但最近,这种印象正被打破。更多的研究者开始探索在图像生成中引入自回归(如 GPT-4o),在语言生成中引入扩散。
香港大学和华为诺亚方舟实验室的一项研究就是其中之一。他们刚刚发布的扩散推理模型 Dream 7B 拿下了开源扩散语言模型的新 SOTA,在各方面都大幅超越现有的扩散语言模型。

在通用能力、数学推理和编程任务上,这个模型展现出了与同等规模顶尖自回归模型(Qwen2.5 7B、LLaMA3 8B)相媲美的卓越性能,在某些情况下甚至优于最新的 Deepseek V3 671B(0324)。

同时,它还在规划能力和推理灵活性方面表现出独特优势,彰显了扩散建模在自然语言处理领域的广阔前景。

各语言模型在通用、数学、编程和规划任务上的比较。

语言模型在标准评估基准上的比较。* 表示 Dream 7B、LLaDA 8B、Qwen2.5 7B 和 LLaMA3 8B 在相同协议下评估。最佳结果以粗体显示,次佳结果带有下划线。
这项工作的作者之一、香港大学助理教授孔令鹏表示,「Dream 7B 终于实现了我们从开始研究离散扩散模型以来一直梦想的通用语言模型能力」。

研究团队将在几天内发布基础模型和指令模型的权重:
-
基础模型:https://huggingface.co/Dream-org/Dream-v0-Base-7B
-
SFT 模型:https://huggingface.co/Dream-org/Dream-v0-Instruct-7B
-
代码库:https://github.com/HKUNLP/Dream
他们相信,虽然自回归模型依然是文本生成领域的主流,但扩散模型在生成文本方面有其天然的优势。而且随着社区对扩散语言模型后训练方案探索的不断深入,这个方向还有很大的挖掘空间。
当然,在这个方向上,扩散模型究竟能走多远,现在还很难判断。但前 Stability AI 的研究总监 Tanishq Mathew Abraham 表示,「即使你不相信扩散模型是未来,我也不认为你可以完全忽略它们,它们至少可能会有一些有趣的特定应用。」


为什么用扩散模型生成文本?
目前,自回归(AR)模型在文本生成领域占据主导地位,几乎所有领先的 LLM(如 GPT-4、DeepSeek、Claude)都依赖于这种从左到右生成的架构。虽然这些模型表现出了卓越的能力,但一个基本问题浮现出来:什么样的架构范式可能定义下一代 LLM?
随着我们发现 AR 模型在规模化应用中显现出一系列局限 —— 包括复杂推理能力不足、长期规划困难以及难以在扩展上下文中保持连贯性等挑战,这个问题变得愈发重要。这些限制对新兴应用领域尤为关键,如具身 AI、自主智能体和长期决策系统,这些领域的成功依赖于持续有效的推理和深度的上下文理解。
离散扩散模型(DM)自被引入文本领域以来,作为序列生成的极具潜力的
替代方案备受瞩目。与 AR 模型按顺序逐个生成 token 不同,离散 DM 从完全噪声状态起步,同步动态优化整个序列。这种根本性的架构差异带来了几项显著优势:
-
双向上下文建模使信息能够从两个方向更丰富地整合,大大增强了生成文本的全局连贯性。
-
通过迭代优化过程自然地获得灵活的可控生成能力。
-
通过新颖的架构和训练目标,使噪声能够高效直接映射到数据,从而实现基础采样加速的潜力。
近期,一系列重大突破凸显了扩散技术在语言任务中日益增长的潜力。DiffuLLaMA 和 LLaDA 成功将扩散语言模型扩展至 7B 参数规模,而作为商业实现的 Mercury Coder 则在代码生成领域展示了卓越的推理效率。这种快速进展,结合扩散语言建模固有的架构优势,使这些模型成为突破自回归方法根本局限的极具前景的研究方向。
训练过程
Dream 7B 立足于研究团队在扩散语言模型领域的前期探索,融合了 RDM 的理论精髓与 DiffuLLaMA 的适配策略。作者采用掩码扩散范式构建模型,其架构如下图所示。训练数据全面覆盖文本、数学和代码领域,主要来源于 Dolma v1.7、OpenCoder 和 DCLM-Baseline,并经过一系列精细的预处理和数据优化流程。遵循精心设计的训练方案,作者用上述混合语料对 Dream 7B 进行预训练,累计处理 5800 亿个 token。预训练在 96 台 NVIDIA H800 GPU 上进行,总计耗时 256 小时。整个预训练过程进展顺利,虽偶有节点异常,但未出现不可恢复的损失突增情况。

自回归建模和 Dream 扩散建模的比较。Dream 以移位方式预测所有掩码 token,实现与 AR 模型的最大架构对齐和权重初始化。
在 1B 参数规模上,作者深入研究了各种设计选项,确立了多个关键组件,特别是来自 AR 模型(如 Qwen2.5 和 LLaMA3)的初始化权重以及上下文自适应的 token 级噪声重排机制,这些创新为 Dream 7B 的高效训练铺平了道路。
AR 初始化
基于团队此前在 DiffuLLaMA 上的研究成果,作者发现利用现有自回归(AR)模型的权重为扩散语言模型提供重要初始化效果显著。实践证明,这种设计策略比从零开始训练扩散语言模型更为高效,尤其在训练初期阶段,如下图所示。

Dream 1B 模型上 200B token 的从零训练与使用 LLaMA3.2 1B 进行 AR 初始化的损失对比。AR 初始化虽然在从因果注意力向全注意力转变初期也会经历损失上升,但在整个训练周期中始终保持低于从零训练的水平。
Dream 7B 最终选择了 Qwen2.5 7B 的权重作为初始化基础。在训练过程中,作者发现学习率参数至关重要:设置过高会迅速冲淡初始权重中宝贵的从左到右知识,对扩散训练几无助益;设置过低则会束缚扩散训练的进展。作者精心选择了这个参数以及其他训练参数。
借助 AR 模型中已有的从左到右知识结构,扩散模型的任意顺序学习能力得到显著增强,大幅减少了预训练所需的 token 量和计算资源。
上下文自适应 token 级噪声重排
序列中每个 token 的选择深受其上下文环境影响,然而作者观察到现有扩散训练方法未能充分把握这一核心要素。具体而言,传统离散扩散训练中,系统首先采样一个时间步 t 来确定句子级噪声水平,随后模型执行去噪操作。但由于实际学习最终在 token 级别进行,离散噪声的应用导致各 token 的实际噪声水平与 t 值并不完全对应。这一不匹配导致模型对拥有不同上下文信息丰富度的 token 学习效果参差不齐。

上下文自适应 token 级噪声重排机制示意图。Dream 通过精确测量上下文信息量,为每个掩码 token 动态调整 token 级时间步 t。
针对这一挑战,作者创新性地提出了上下文自适应 token 级噪声重排机制,该机制能根据噪声注入后的受损上下文智能调整各 token 的噪声水平。这一精细化机制为每个 token 的学习过程提供了更为精准的层次化指导。
规划能力
在此前的研究中,作者已证实文本扩散可以在小规模、特定任务场景下展现出色的规划能力。然而,一个关键问题始终悬而未决:这种能力是否能扩展到通用、大规模扩散模型中?如今,凭借 Dream 7B 的问世,他们终于能够给出更加确切的答案。
他们选择了《Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning》中的 Countdown 和数独任务作为测试平台,这些任务允许研究者精确调控规划难度。评估对象包括 Dream 7B、LLaDA 8B、Qwen2.5 7B 和 LLaMA3 8B,并将最新的 Deepseek V3 671B(0324)作为参考基准。所有模型均在少样本学习环境下进行测试,且未针对这些特定任务进行过专门训练。

不同规划难度下,不同模型在 Countdown 和数独任务中的性能表现对比。
结果清晰显示,Dream 在同等规模模型中表现卓越。特别值得一提的是,两种扩散模型均显著超越了同级别 AR 模型,在某些情况下甚至优于最新的 DeepSeek V3,尽管后者拥有数量级更庞大的参数规模。这一现象背后的核心洞见是:扩散语言模型在处理多重约束问题或实现特定目标任务时更有效。
以下为 Qwen 2.5 7B 与 Dream 7B 在三个规划任务中的表现示例:

Qwen2.5 7B 与 Dream 7B 的生成结果对比。
推理灵活性
相较于 AR 模型,扩散模型在两个核心维度上显著增强了推理灵活性。
任意顺序生成
扩散模型彻底打破了传统从左到右生成的束缚,能够按任意顺序合成输出内容 —— 这一特性为多样化的用户查询提供了可能性。
1、Completion 任务

Dream-7B-instruct 执行补全任务的效果展示。
2、Infilling 任务

Dream-7B-instruct 执行指定结尾句填充任务的效果展示。
3、精细控制解码行为
不同类型的查询通常需要不同的响应生成顺序。通过调整解码超参数,我们可以精确控制模型的解码行为,实现从类 AR 模型的严格从左到右生成,到完全自由的随机顺序生成的全谱系调控。

模拟 AR 模型的从左到右解码模式。

在解码顺序中引入适度随机性。

完全随机化的解码顺序。
灵活的质量 - 速度权衡
在上述演示中,作者展示了每步生成单个 token 的情况。然而,每步生成的 token 数量(由扩散步骤控制)可以根据需求动态调整,从而在速度和质量之间提供可调的权衡:减少步骤可获得更快但粗略的结果,增加步骤则以更高计算成本换取更优质的输出。这一机制为推理时间 scaling 开辟了全新维度,不是替代而是补充了主流大型语言模型(如 o1 和 r1)中采用的长思维链推理等技术。这种灵活可调的计算 - 质量平衡机制,正是扩散模型相较传统 AR 框架的独特优势所在。
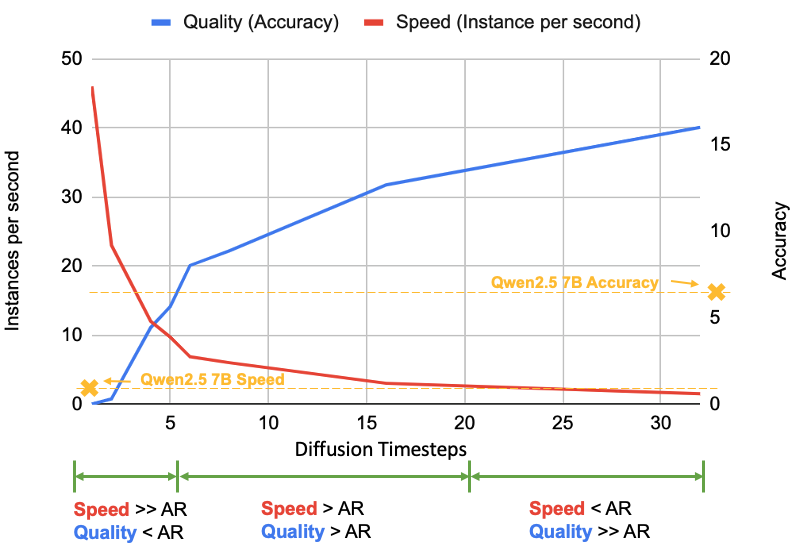
Dream 7B 与 Qwen2.5 7B 在 Countdown 任务上的质量 - 速度性能对比。通过精准调整扩散时间步参数,Dream 能够在速度优先与质量优先之间实现灵活切换。
有监督微调
作为扩散语言模型后训练阶段的关键一步,作者实施了有监督微调以增强 Dream 与用户指令的对齐度。他们精心从 Tulu 3 和 SmolLM2 筛选并整合了 180 万对高质量指令 - 响应数据,对 Dream 进行了三轮深度微调。实验结果充分展现了 Dream 在性能表现上与顶尖自回归模型比肩的潜力。展望未来,作者正积极探索为扩散语言模型量身定制更先进的后训练优化方案。

有监督微调效果对比图。
原文链接:
https://hkunlp.github.io/blog/2025/dream/

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]